- [Deep Dive into LLMs like ChatGPT](https://www.youtube.com/watch?v=7xTGNNLPyMI)
# Pretraining
- **pretraining & inference** :
1. download and preprocess the internet
- 需要大量文档,large diversity & high quality,来获取足够多的知识
- [fineweb](https://huggingface.co/datasets/HuggingFaceFW/fineweb)
2. tokenization
- 将 txt 重新拆分呈现为一维的 symbols 序列
- 减少 vocabulary(symbol set) size
- symbol/token 可以看作是 unique id
- [Tiktokenizer](https://tiktokenizer.vercel.app/)
3. neural network training
- 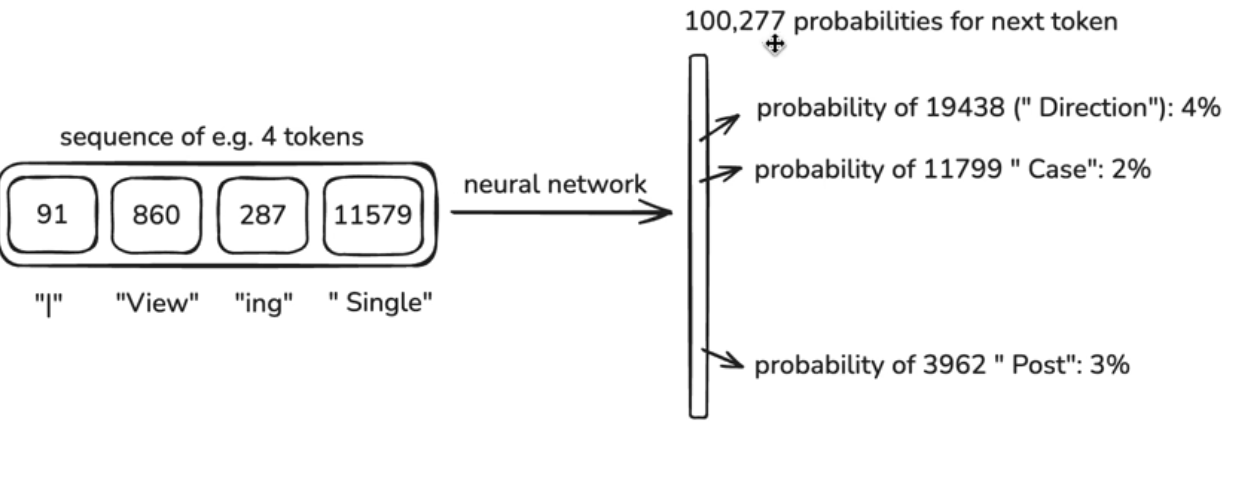
- **输入**:windows of token, window 长度不固定,一般有最大限制(max context length)
- **输出**:prediction,预测下一个token是什么
- 从训练文本我们知道正确答案是什么,通过对神经网络进行 tuning,使得正确答案的概率更高
- internals:
- 
- 参数化的数学函数,无 memory,stateless
- 不断更新、调整参数/weights,让 predictions 跟 training set 一致
- [Transformer Neural Net 3D visualizer](https://bbycroft.net/llm)
- inference
- 根据模型生成新的数据,predict one token at a time
- 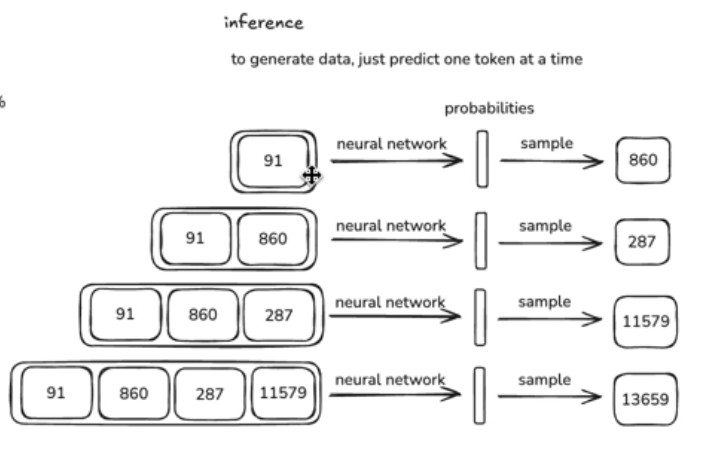
- 每次都是按概率投硬币,生成下一个 token。
- llm.c Let's Reproduce GPT-2:[https://github.com/karpathy/llm.c/discussions/677](https://github.com/karpathy/llm.c/discussions/677)
- **base model**: internet document simulator
- 模型示例:
- [openai/gpt-2](https://github.com/openai/gpt-2)
- Llama 3
- a release of a model 包括:
- 运行 Transformer 的代码(例如 200 行 python 代码)
- Transformer 的 parameters(例如 1.6 亿个数字)
- 测试:Hyperbolic, for inference of base model: https://app.hyperbolic.xyz
- base model 不是一个 assistant,只是一个 ==token autocomplete==,并且是一个 stochastic system(随机系统)。
- 并不是很有用,predict 也并不完全可信(只是对 internet documents 的 recollection)。
- 1.6 亿个 parameters 可以看作是对 internet 的一种==有损压缩==
- 通过 parameters 存储了大量 knowledge
- knowledge 不是精确的,而是 vegue、probabilistic 和 statistical 的
- 训练文本中质量高的、出现次数多的,更有可能被 recite(例如维基百科)
- **hallucination**:例如输入模型训练时间点之后的内容,模型会猜测输出不真实的信息
- 具备一定的应用能力:
- Few-shot prompting & in context learning ability:通过 prompt 使 base model 变成 assistant
- shot:给 AI 提供一些 examples
> [!summary]
> - **pretraining stage**:将 internet documents 拆分为 tokens,通过神经网络来 predict token sequences
> - **base model** 是 pretraining stage 的产出,具备一定应用能力,但可以做到更好(通过 post-training);
---
# Post-training Supervised Finetuning
- 相比 pretraining 训练成本更低,但也极其重要,将 model 转换成 assistant。
- pre-training 需要3 个月 vs post-training 3 小时
- 基于 data set of **conversations**(来自人工标注)继续训练神经网络
- 让模型学会如何在 inference 时回应 human queries
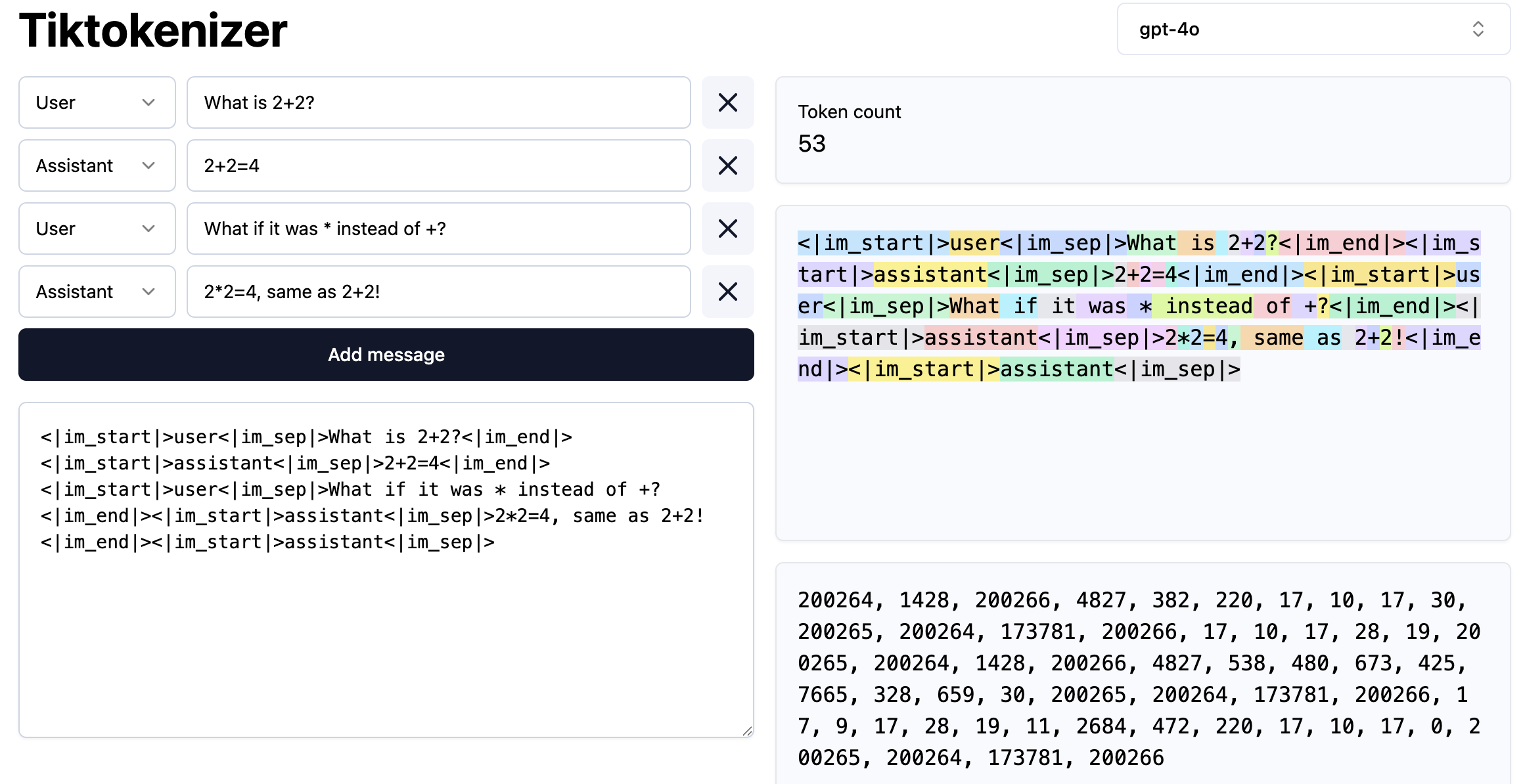
- **tokenization** of conversations
- 协议/格式:将 coversation 编解码为 token
- 将 structured object 转换为一维 tokens
- 加入新的 special token 表示一轮会话的开始、角色、结束等
- 
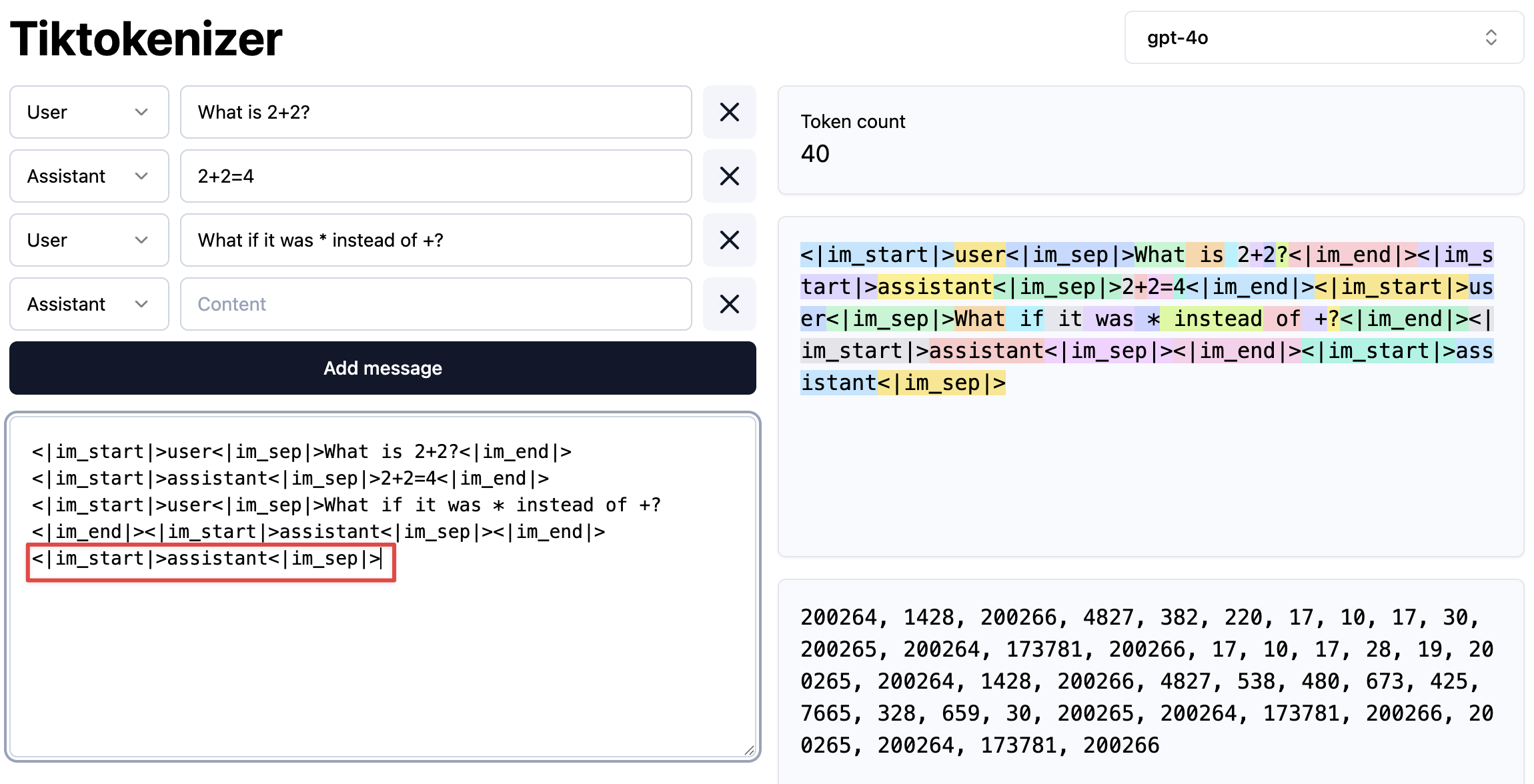
- 将 conversations 转换为 tokens 后,后续的流程就跟 pre-training 一样了,包括训练和推理。
- 推理时构造如下的 token prefix :
- 
- ==a statistical simulation of a human labeler==
- [InstructGPT](https://arxiv.org/abs/2203.02155)
- fine tune LLM on conversations
- 人工标注,构造 conversations
- prompt + ideal assistant response
- helpful,truthful,harmless
- conversations 的生成:
- 人工标注:[OpenAssistant Conversations Dataset](https://huggingface.co/datasets/OpenAssistant/oasst1)
- LLM 可以用于生成 conversations
> [!summary] Post-training
> - 与 pre-training 的区别:训练数据集不同,来自 conversations
---
# LLM Psychology
## Hallucinations
- 
- 对于不知道的知识进行 sample from probabilieis,consistent with the sytle of the answer in its training set
- best guess
- meta Llama 的处理:
1. knowledge probing technique: 识别出 model 知道什么和不知道什么
- 给定一段话,让另一个 LLM 从中提取生成 factual questions(问题 + 正确答案),对 LLM 进行测试其是否知道
2. 在 training set 中添加 examples:对于 model 不知道的事情正确的回答就是不知道
- 添加 conversations:factual question,答案是 i don’t known
## Tools
- Allow the model to search
- 是解决 Hallucinations 的一种方式。
- 示例:
- Human:"Who is Orson Kovacs"
- Assistant: "<SEARCH_START> Who is Orson Kovacs <SEARCH_END>"
- 引入新的格式/协议,模型可以输出特殊的 token(SEARCH),模型识别到特殊 tokens 后停止继续生成并转去搜索,将搜索的结果加入 context window
- context window 可以看作是模型的 working memory。context window 中的 data 可以被模型访问到,可以 feed 给 neural network。
- 在 training set 中加入 example,让模型学会使用工具(web search),模型决定何时去 search。
## Vague recollection vs Working memory
- Knowledge in the parameters == Vague recollection
- 类似于你一个月前读过的东西
- Knowledge in the tokens of context window == Working memory
## Knowledge of self
- Users:What model are you? Who built you?
- AI 没有自我身份的认知(identify),只是 token simulator。
- 解决:
- hardcoded dataset:给出此类问题的正确答案
- [allenai/olmo-2-hard-coded](https://huggingface.co/datasets/allenai/olmo-2-hard-coded)
- system message:invisible messages,加入模型的 identify
----
# Computational capabilities
## Models need tokens to rethink
- 
- 右边的更好
- 创建了 intermediate calculations,much easier for the model,it‘s not too much work per token,可以处理 single forward pass of network 无法解决的问题
- ==spread out== its compuatation over the tokens, ask models to create intermediate results.
- every single token is only spending finite amount of computation on the model.
- 也就是说 inference 一个 token 的计算能力是**有限**的(single forward pass of a network),避免只靠一个 token 计算一个复杂的问题。
- 使用 code **tool**
- 避免模型 try to do it all in their memory
```prompt
Emily buys 23 apples and 177 oranges. Each orange costs $4. The total cost of all the fruit is $869. What is the cost of each apple?
Use code.
```
> [!summary] Models need tokens to rethink
> 让模型有机会执行更多 forward passes of network
## Models can't count
- ```prompt
How many dots are below?
.................................................................................................
```
- 模型不是很擅长计数,原因也是与上面类似的,在单个 token inference 时要求了太多计算。
- in a single token, it has to count the number of dots in its context window. It has to do that in the **single forward pass** of a network.
## Models are not good with spellings
```prompt
Print back the following string, but only print every 3rd character, starting from the first one.
ubiquitous
```
- Models see tokens (text chunks), not individual letters!
---
# Post-Training: Reinforcement Learning
- training pipleline 的第三步。last major stage of training。
- stages of learning a textbook:
1. exposition <=> pretraining
- background knowledge
- base model
2. worked problems <=> supervised finetuning
- problem + demonstrated solution, for imitation
- sft model
- 模拟 human expert
3. practice problems <=> reinforcement learning
- prompts to practice, trial & error until you reach the correct answer
- 知道最终答案,但不知道 solution,尝试去练习 solution
- 动机:
- we are not in a good postition to create these token sequences for the LLM
- 认知不同,人类并不一定知道哪些 token sequences 对 LLM 来说是更好的
- let the LLM to dicover the token sequences that work for it, what token sequences reliably gets to the answer
- 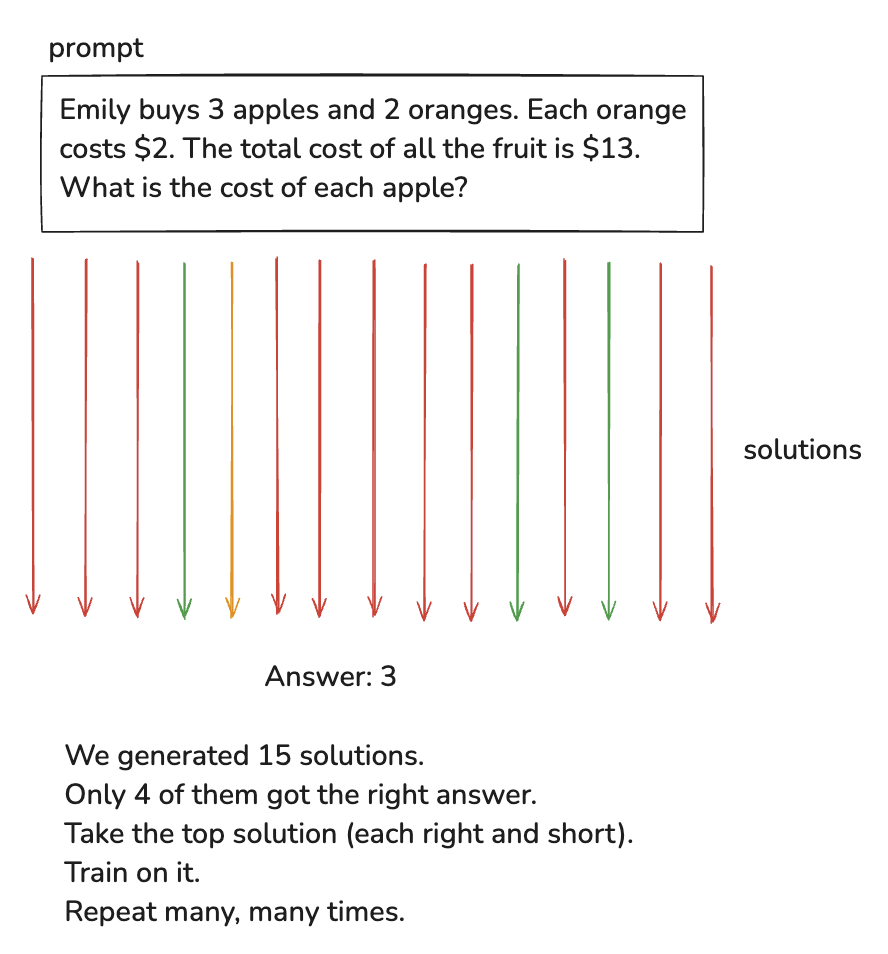
1. 给定 prompt 和 final answer,不断尝试让 LLM 生成 solutions
2. 挑选正确且短的 solution,鼓励 LLM 去生成这类 solutions
- 短或者有其他好的属性的 solution
3. 鼓励:基于这些 solutions 做训练
> [!summary]
> - Reinforcement Learning 的 data sets 不来自人工标注,而是来自 LLM 自身生成的 solutions。
- RL 的开发目前还处于早期阶段,在该领域内还没有标准化。
- [DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning](https://arxiv.org/abs/2501.12948)
- thinking model
- thinking and trying different ways, giving higher accuracy
- AlphaGo
- 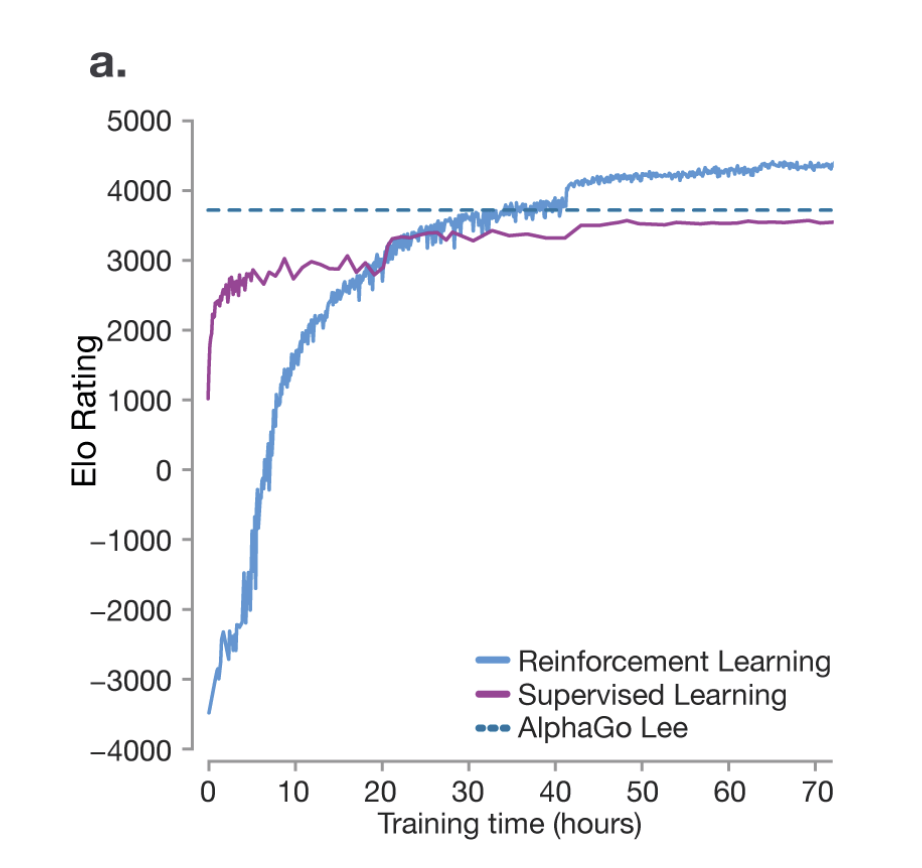
- Supervised Learning 只是模仿人类顶尖的 player,永远无法超越他们
- 而 RL 通过自我对抗可以做到超越
- learning in unverifiable domains
- 没有固定答案,LLM 无法自动评价 solutions(score)
- prompt:"write a joke about pelicans"
- RLHF(Reinforcement Learning From Human Feedback)
- Naive approach:
- Run RL as usual, of 1,000 updates of 1,000 prompts of 1,000 rollouts.
- cost: 1,000,000,000 scores from humans
- RHLF approach:
1. Take 1,000 prompts, get 5 rollouts, order them from best to worst (cost: 5,000 scores from humans)
2. Train a neural net simulator of human preferences ("reward model")
3. Run RL as usual, but using the simulator instead of actual humans
- 专门训练一个 reward model,模拟人类评价
- 该模型的输出是 a single number: score
- consistent with human orderings
- **upside**:
- run RL in arbitrary domains
- improves the performance of the model, possibly due to the "discriminator - generator gap"
- 对 human labbers 来说,辨别/评价比生成更简单,准确度更高
- **dowside**:
- We are doing RL with respect to a ==lossy== simulation of humans. It might be misleading!
- RL discovers ways to "game" the model.
- get high score in a fake way
- 不能像普通 RL 一样无限次运行
---
# Previewing of Things to Come
- Multimodal
- audio, images, video, natural conversations
- tasks -> agents
- long, coherent, error-correcting contexts
- pervasive, invisible
- computer-using
- test-time tranining?, etc
- 模型训练完后就是固定的了,唯一有变动的是 tokens in the context windows
- in-context learning, dynamically adjustable
- 只靠增大 context windows 不适合 long running tasks
----
# Where to Keep Track of them
- reference https://lmarena.ai/
- subscribe to https://buttondown.com/ainews
- X / Twitter
---
# Where To Find Them
- Proprietary models: on the respective websites of the LLM providers
- Open weights models (DeepSeek, Llama): an inference provider, e.g. TogetherAI
- Run them locally! LMStudio
---
# Summary
| | Pre-Training | Post-Training(SuperVised Finetuning) | Post-Training(Reinforcement Learning) |
| -------- | ------------------------ | ------------------------------------ | ------------------------------------- |
| data-set | internet | conversations of human labbers | LLM self generated solutions |
| product | base model | sft model | RL model |
| function | internet token simulator | imitation of human experts | thinking and cognitive strategies |