# 1. Distributed Query Execution
- 分布式数据库中执行 OLAP 查询跟单机数据库大致一样
- Query plan 是 physical operators 的 DAG
每个 operaotr 需要考虑输入来自哪里、输出发送到哪里(parent operator)
- 将 plan 切分 tasks 分布到多个节点上,也类似分布到单机的多核上
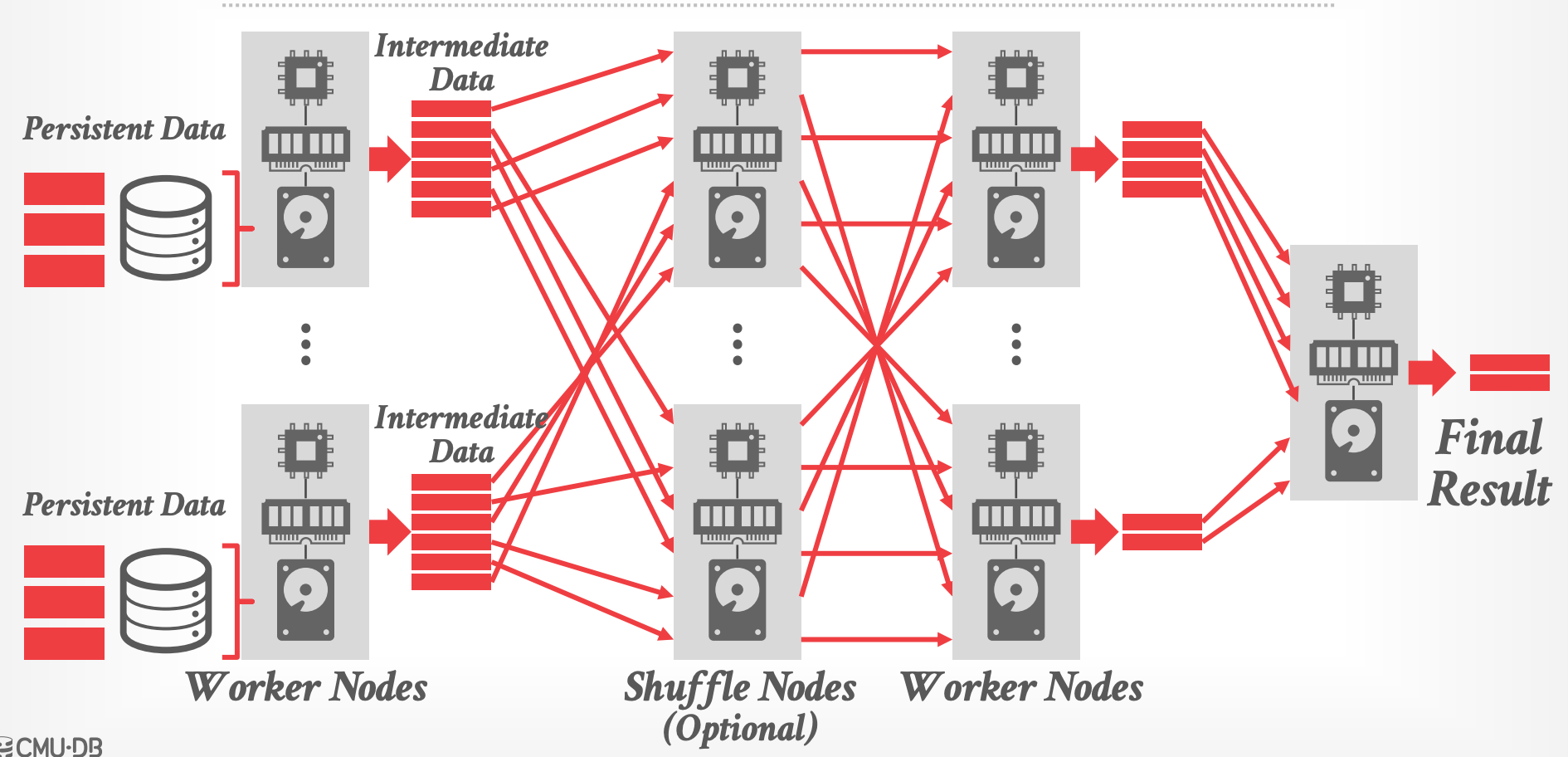
- **数据种类**
- Persistent Data
- "source of record",如 table 数据
- 现代系统假设这些数据文件是不可变的,通过重写来支持更新
- Intermediate Data
- Short-lived,由 operator 执行时产生,被其他 operators 消费
- 大小跟读取的 persistent data 大小不一定相关
-----------
# 2. Distributed System Architectures
- 主要在于指定 persistent data files 的 位置
这会影响 nodes 之间如何协调、在哪里获取/存储 objects
- 两种途径(不互斥)
- **Push Query to Data**
- **Pull Data to Query**
## 2.1 Push VS. Pull
### Push Query to Data
- 发送 query(或者它的一部分)到包含数据的节点
- 网络传输之前,在数据所在地尽可能地执行更多的 filter 和 processing
### Pull Data to Query
- 将数据带到执行 query 的节点上(该 query 需要这部分数据)
- 对于数据所在地不包含计算资源的场景下,是必须的(如 remote file system)
> 两种并不互斥,如 S3 Select、Azure Query Blob Contents 读数据时执行 initial filtering。
## 2.2 Two High Level Approaches
### Shared Nothing
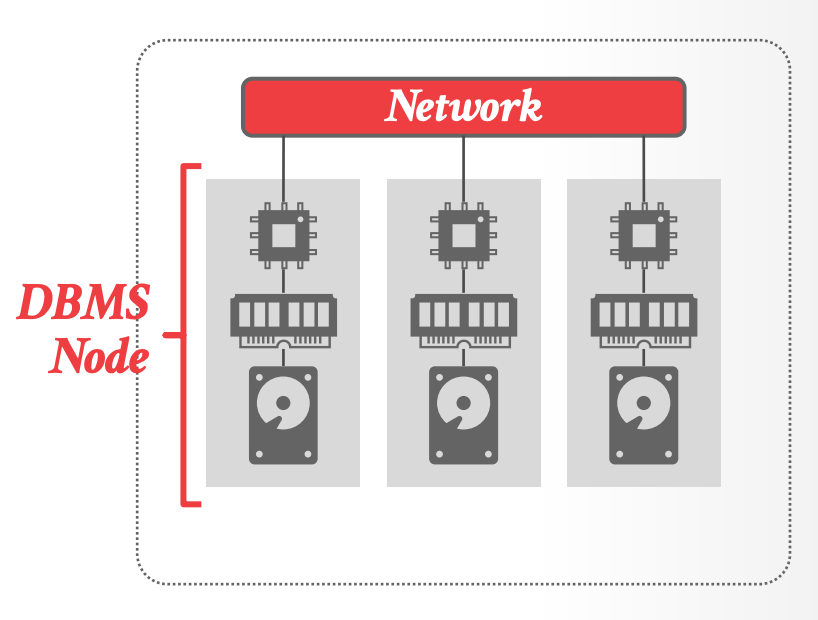
- 每个节点由自己的 CPU、内存、locally-attached disk
- 节点之间只通过网络来通信
- Database 划分成不相交的子集分布到不同节点上
- 添加一个新节点,需要跨节点物理搬迁数据
- 数据是本地的,DBMS 可以通过 POSIX API 来访问。
### Shared Disk
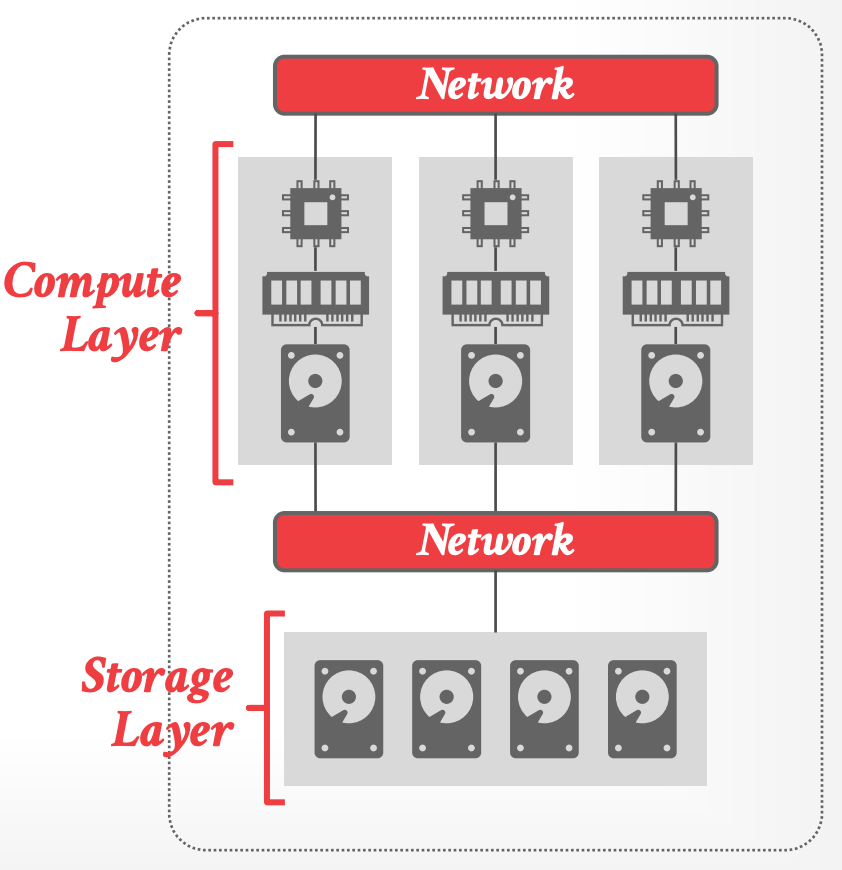
- 每个节点通过 interconnect 访问一个 logical disk
- 但节点同时也有自己私有的内存和 ephemeral storage(cache或者保存临时数据)
- DBMS 使用 userspace API 来访问 disk。
### Pro and Cons
- **Shared Nothing**
- 扩容困难(需要移动数据)
- 更好的性能和效率
- 数据传输之前可以应用 filters
- **Shared Disk**
- 计算和存储层可以分别独立扩展
- 可以很容易关闭空闲计算资源
- 可能需要从存储层拉取没被缓冲的数据,之后才能应用 filters
### Object Stores
- 将 table 分割为 large、immutable files 存储在 object store 中。
- columnar layout(如PAX)
- catalog 等管理文件在 object store 中的位置
- file header(or footer)包含了 metadata(如 columnar offset、indexes等)
DBMS先获取 block header,再决定读取的数据范围。
- 每个云厂商提供自己的 API 来访问数据(PUT,Get,DELETE)
- 一些厂商支持 predicate pushdown (S3)
- Yellowbrick
- 如何使用 S3(自定义 access library、UDP通信等)
--------
# 3. OLAP Commoditization
- 近些年的趋势之一:OLAP engine sub-systems 拆分成了独立的开源组件
- 一般由开源组织完成,而非售卖 DBMS 的商业公司
- 示例:
- System Catalogs
- Query Optimizers
- File Fomart / Access Libraries
- Execution Engines
## 3.1 System Catalogs
- DBMS 使用 catalog 来跟踪 schema(table,columns)和 data files
- 如果 DBMS 在 data ingestion 的执行路径上,那么它可以增量地维护 catalog
- 如果 data files 由外部添加,则需要更新 catalog(这样 DBMS 才能感知到)
- 知名实现
- [HCatalog](https://cwiki.apache.org/confluence/display/Hive/HCatalog)
- [Google Data Catalog](https://cloud.google.com/data-catalog/)
- [Amazon Glue Data Catalog](https://docs.aws.amazon.com/glue/latest/dg/tables-described.html)
## 3.2 Query Optimizer
- **Extendible search engine framework** for heuristic and cost-base query optimization
- DBMS 提供 transformation rules 和 cost estimate
- Framework 返回一个 logical 或者 physical query plan
- 知名实现
- [Greenplum Orca](https://github.com/greenplum-db/gporca)
- Paper: [Orca: a modular query optimizer architecture for big data](https://dl.acm.org/doi/10.1145/2588555.2595637)
- [Apace Calcite](https://calcite.apache.org/)
- Paper:[Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources](https://dl.acm.org/doi/10.1145/3183713.3190662)
## 3.3 File Formats
- 大多数 DBMS 使用私有的磁盘文件格式。
- 唯一共享数据的方式是转化数据为共同的 text-based format
- 如 CSV,JSON,XML
- 开源 binary file formats
- 更容易跨 systems 和 libraries 来访问数据
- libraries 提供一个 iterator 来批量从文件获取 columns
### 3.3.1 Universal Formats
- **Apache Parquet(2013)** [[parquet-fomart]]
- 压缩列存,来自 Cloudera/Twitter
- **Apace ORC(2013)**
- 压缩列存,来自 Apache Hive
- **Apache CarbonData(2013)**
- 压缩列存,来自华为
- **Apache Iceberg(2017)** [[iceberg-review]]
- 灵活的数据格式,支持 schema evolution,来自 Netflix
- **HDF5(1998)**
- Multi-dimensional arrays,主要用于科学计算
- **Apache Arrow(2016)**
- 内存中的压缩列存,来自 Pandas/Dremio
## 3.4 Execution Engines
- 单独的库,用于在**列存**数据之上,执行**向量化**的查询算子。
- 输入是 physical operators 的 DAG
- 需要外部的 scheduling 和 orchestration
- 知名实现
- [[meta-velox-paper |Velox]]
- [DataFusion](https://arrow.apache.org/datafusion/)
- [Intel OAP](https://oap-project.github.io/latest/)