- 数据在物理上如何表示 几乎决定了 DBMS 的整个系统架构:
- Processing Model
- Tuple Materialization Strategy
- Operator Algorithms
- Data Ingestion / Updates
- Concurrency Control
- Query Optimization
# 1. Storage Models
- **storage model** 定义了 DBMS 如何在磁盘和内存中物理地组织 tuples。
## 1.1 N-ary Storage Model (NSM)
- DBMS 将一个 tuple 的几乎所有属性连续地存储在一个 page 中。
- 适合 OLTP workloads(事务倾向访问单个/若干实体)和 insert-heavy workloads
- 使用 tuple-at-a-time iterator process model
- NSM dataase 的 page sizes 一般是个常量( 硬件 page 4KB 的倍数)
- 如 Oracle(4KB),Posgres(8KB),MySQL(16KB)
### Physical Organization
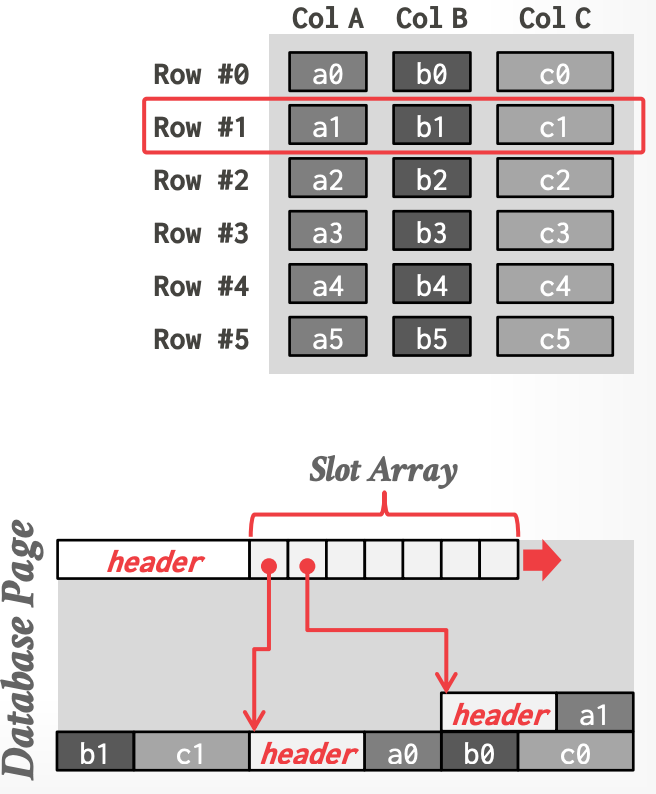
- 一个 tuple 的属性们连续地存储在一个 slotted page 中。
- page header:checksum等元数据
- slot array 存储每个 tuple 的 offset
- 定位物理上的 tuple:**record id** 即 (page#, slot#)
### Pros Cons
- **优势**
- insert、update 和 delete 很快
- 有利于需要整个 tuple 的查询(OLTP),一个 tuple 的所有属性都在一起
- 可以使用 index-orientd physical storage(clustering),如 B+ tree
- **劣势**
- 不利于 scan table 的大部分、属性的部分子集
- memory locality 差(访问某列需要 jumping)
- 不利于压缩(一个page 内有多个 value domains)
## 1.2 Decomposition Storage Model(DSM)
- DSM: columnar store
- 所有 tuples 的某一列连续地存储在一个数据块内。
- 适合 OLAP workload
- 只读查询只批量 scan 某几列
- 使用 batched vectorized processing model
- 文件大小会更大(数百 MB),但在文件内也可以切分为小的 groups
### Physical Organization
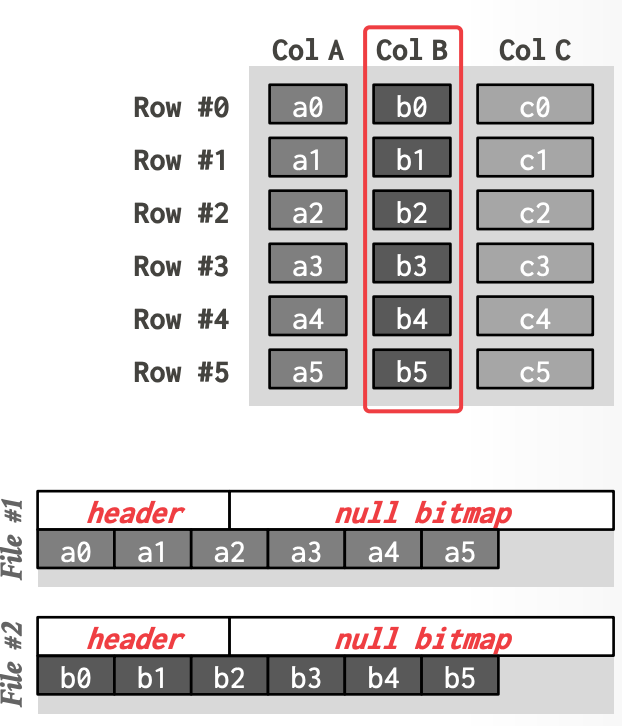
- 图中结构:每个 clomun 一个文件,文件头部有一个关于该 column 的 header 存储 metadata
- 实际实现如 parquet,metadata 都放在 footer 中。
- null bitmap:有多少 tuple 就有多少 bits。null value 也分配空间(value 长度固定)
### Tuple Identification
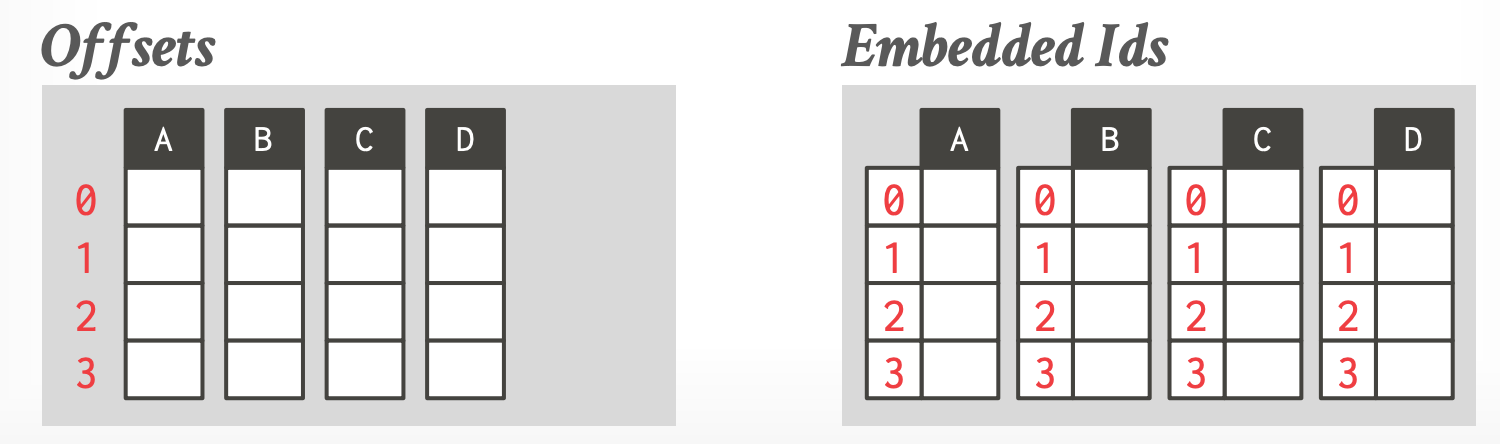
- **Fix-length Offsets**
- 该列的每个 value 的长度相同
- **Embedded Tuple Ids**
- value 存储时携带 tuple id
### Variable-length Data
- 添加 padding,变成固定长度。(浪费)
- 字典压缩,将变长数据转变为固定长度(如 32位整型)
### System History
- **1970s**:Cantor DBMS
- **1980s**:[DSM Proposal](https://dl.acm.org/doi/10.5555/645472.655555)
- **1990s**:SybaseIQ(in-memory only)
- **2000s**:Vertica、Vectorwise、MonetDB
- **2010s**:Everyone
### Pros Cons
- **优势**
- 减少 IO,只读取查询需要的数据
- 查询处理更快:locality 、cache 更好
- 有利于数据压缩
- **劣势**
- 点查、插入、更新、删除比较慢(需要拆分/重组 tuple)
## 1.3 Hybrid Storage Model(PAX)
- **PAX: Partition Attributes Across**
- 混合存储模型,在一个 database page / group 内垂直切分列
- 同一个 tuple 的所有列在物理上相对比较接近,仍然属于列存
- Parquet 和 Orc 使用
### Physical Organization
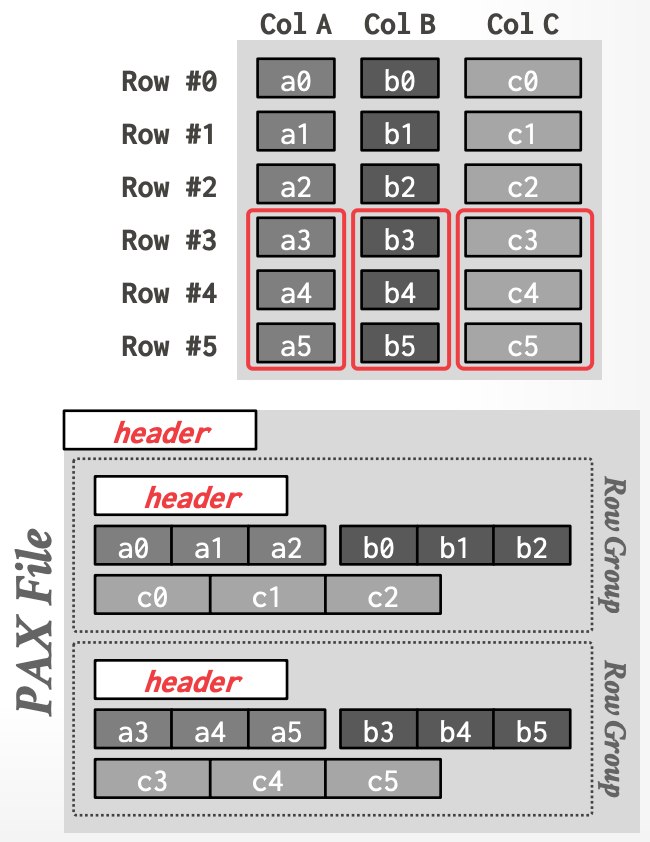
- 将 rows 水平地切分为 groups,然后将每个 group 垂直地按列切分。
- global header 维护了 file groups 的 offset
- Parquet/Orc 存储在 footer 中
- 每个 row group 拥有自己的 metadata header。
## 1.4 Memory Pages
- OLAP 场景内存分配较大,**大页**有一定有效。
- Google [最近研究](https://www.usenix.org/conference/osdi21/presentation/hunter)能提升 7% 性能
- [Huge Pages are a Good Idea (evanjones.ca)](https://www.evanjones.ca/hugepages-are-a-good-idea.html)
- **Transparent Huge Pages(THP)**
- THP开启后,OS 会在后台重新组织 pages
- 将大页拆分为小页
- 将小页合并为大页
- 可能会导致 DBMS 进程访问内存时**卡住**
- 历史上,每个 DBMS 都建议关闭 THP
- Vertica [建议](https://www.vertica.com/docs/9.3.x/HTML/Content/Authoring/InstallationGuide/BeforeYouInstall/transparenthugepages.htm)只在更新的 Linux 版本开启 THP
-----
# 2. Type Representation
- I**NTEGER / BIGINT / SMALLINT / TINYINT**
- C/C++ Representation
- **Float / REAL vs. NUMERIC / DECIMAL**
- IEEE-754 Standard / Fixed-point Decimals
- **TIME / DATE / TIMESTAMP**
- 32/64 位整型,自 Unix Epoch 之后的 micro/milli/seconds
- **VARCHAR / VARBINARY / TEXT / BLOB**
- 小于 64 位,可以 inlined
- 指向其他 location 的指针(如果类型大于 64 位)
- Header(length + address如果segmented ),后面跟实际数据
- 可使用字典压缩
## 2.1 Variable Precision Numbers
- **不精确**
- $x+y=0.30000001192092895508$
- $0.3=0.299999999999999998890$
- 可直接对应原生的 C/C++ 类型(float / double)
- 按照 [IEEE-754](https://en.wikipedia.org/wiki/IEEE_754) 标准存储
- 示例:FLOAT、REAL / DOUBLE
- 一般要比 fixed precision 数值更快,硬件原生支持
> CPU ISA 有专门的指令和寄存器来支持运算等。
## 2.2 Fixed Precision Numbers
- 由 DBMS 自己实现而非靠硬件,理论上能支持任意的 percision 和 scale
- 使用场景:rounding errors 不可接受时
- 示例: NUMERIC,DECIMAL
- 不同的实现
- 存储为精确的、变长的二进制,再加上额外的 meta-data
- 不支持任意 precision,实现成本小(例如所有值的小数点位数都一样)
- [cmu libfixeypointy](https://github.com/cmu-db/libfixeypointy)
### Postgres: NUMERIC
```c
typedef unsigned char NumericDigit;
typedef struct {
int ndigits; // 总共多少位数字
int weight; // 第一个数字表示 weight
int scale; // scale factor,小数点后的位数
int sign; // 符号,正数/负数/Nan
NumericDigit *digits; // 变长字符串数组,负责实际存储
} numeric;
```
### MySQL: NUMERIC
```c
typedef int32 decimal_digit_t;
struct decimal_t {
int intg, frac, len; // 小数点之前的位数,之后的位数,长度(字节数)
bool sign; // 正数,负数
decimal_digit_t *buf; // 32位整型数组,实际数据存储
};
```
## 2.3 Null Data Types
- 选择1: **Special Values**
- 指定一个特殊值来表示该数据类型的 NULL(如 INT32_MIN)
- 选择2:**Null Column Bitmap Header**
- 在一个集中的 header 里存储 bitmap,表示该列的哪些行是 NULL
- 选择3:**Per Attribute Null Flags**
- 每个列值存储一个 flag 来表示是否为 NULL
- 空间浪费比较严重
-----
# 3. Hybrid Storage Model
- 使用为 NSM 和 DSM 优化的两套独立的执行引擎
- 新数据存储在 NSM,OLTP 更快
- 将数据迁移到 DSM,支持更高效的 OLAP
- 合并两个引擎的查询结果,对外表现为一个逻辑 Database
- 选择一:**Fractured Mirrors**
- 示例:Oracle、IBM DB2 Blu、MS SQL Server
- 在 DSM 存储中额外存储一份数据的拷贝
- 所有更新先进入 NSM,最终进入 DSM mirror
- 更新需要 invalidate DSM 中的数据
- 选择二:**Delta Store**
- 示例:SAP HANA、Vertica、SingleStore、Databricks、Google Napa
- NSM 和 DSM 中数据没有重复,例如数据变冷后,从 NSM 迁移到 DSM
---
# 4. Partitioning
- 将 Database 拆分到多个资源之上
- Disks, nodes, processors
- NoSQL 一般称为 sharding
- Partition 可以是物理上的(shared nothing)或者 逻辑上的(shard disk)
## 4.1 Horizontal Partitioning
- 按照 partition key / columns 将 table 的 tuples 拆分为不相交的子集。
- **Partitioning Schemas**
- Hashing
- Ranges
- Predicates
## 4.2 Logical Partitioning
- 基于 Shared Disk,不会把数据移动物理节点上去,而是指定节点负责操作哪些数据
## 4.3 Physical Partitioning
- Share Nothing 架构