# Background
## 真实世界数据的特征
- 数据集的属性值分布往往是高度倾斜的。
- 如 Zipfian 分布
- 数据集同一 tuple 的不同属性有很强的相关性
- 例如 Zip Code 与 City、Order Date 与 Ship Date
## Observation
- 传统上, IO 是查询执行的主要瓶颈。
- 核心 trade-off 是 speed 与 compression ratio
- 压缩可以减少对 DRAM 的需求
------
# 1. Database Compression
- **目标**
1. 必须输出 fixed-length values
2. 必须是**无损的**
3. 理想情况下,在查询执行期间尽可能延迟解压缩。
- **Lossless VS. Lossy Compression**
- DBMS 压缩必须是 lossless 的(不能丢失数据)
- 任何 lossy 的压缩必须在应用层执行
- **Compression Granularity**
- **Block-level**
- 如 database page、RowGroup
- **Tuple-level**
- NSM-only,压缩整个 tuple 的内容
- **Attribute-level**
- 压缩一行数据中的单个列值
- **Column-level**
- DSM-only,压缩多行的一个/多个列值
--------
# 2. Naive Compression
- 使用**通用**的压缩算法,对 Database 透明
- LZO、LZ4、Snappy、Brotli、Oracel OZIP、**Zstd**
- 考量:
- 计算开销
- 压缩 和 解压的速度
## MySQL Innodb Compression
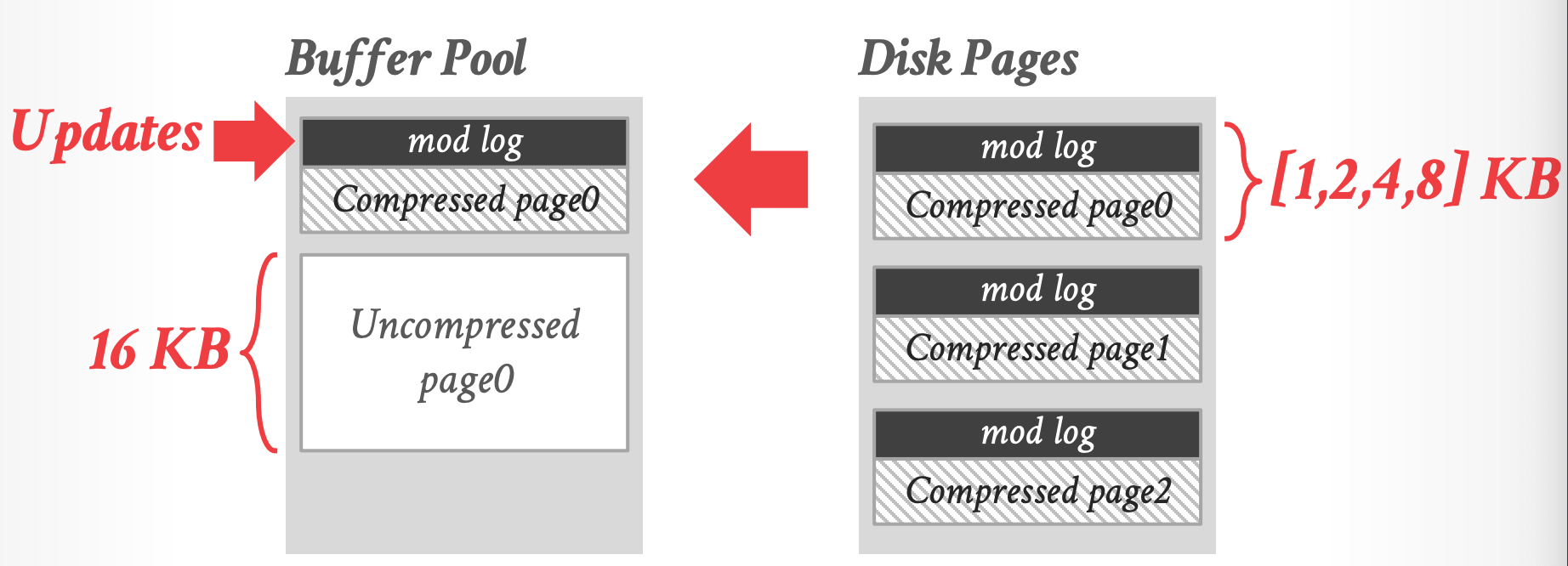
- compressed page 的大小是固定的几个尺寸,不够会padding
- 更新先写如 mod log,可以不解压就更新
- 解压后的大小固定是 16 KB
## 总结
- 读和修改时,必须先解压
- 这些方案也没有考虑数据的高层含义或语义
- 例如不关心里面数据的类型、无法在压缩数据上直接进行一些谓词计算
-------
# 3. Columnar Compression
## 3.1 Run-Length Encoding
- 将列值相同的 runs 压缩成三元组:
- 列值
- 在 column segment 中的起始位置
- 元素的个数
- 需要先对列进行**排序**,来最大化压缩的机会
- 有时被称为 **null suppression** 如果 DBMS 只跟踪 empty space
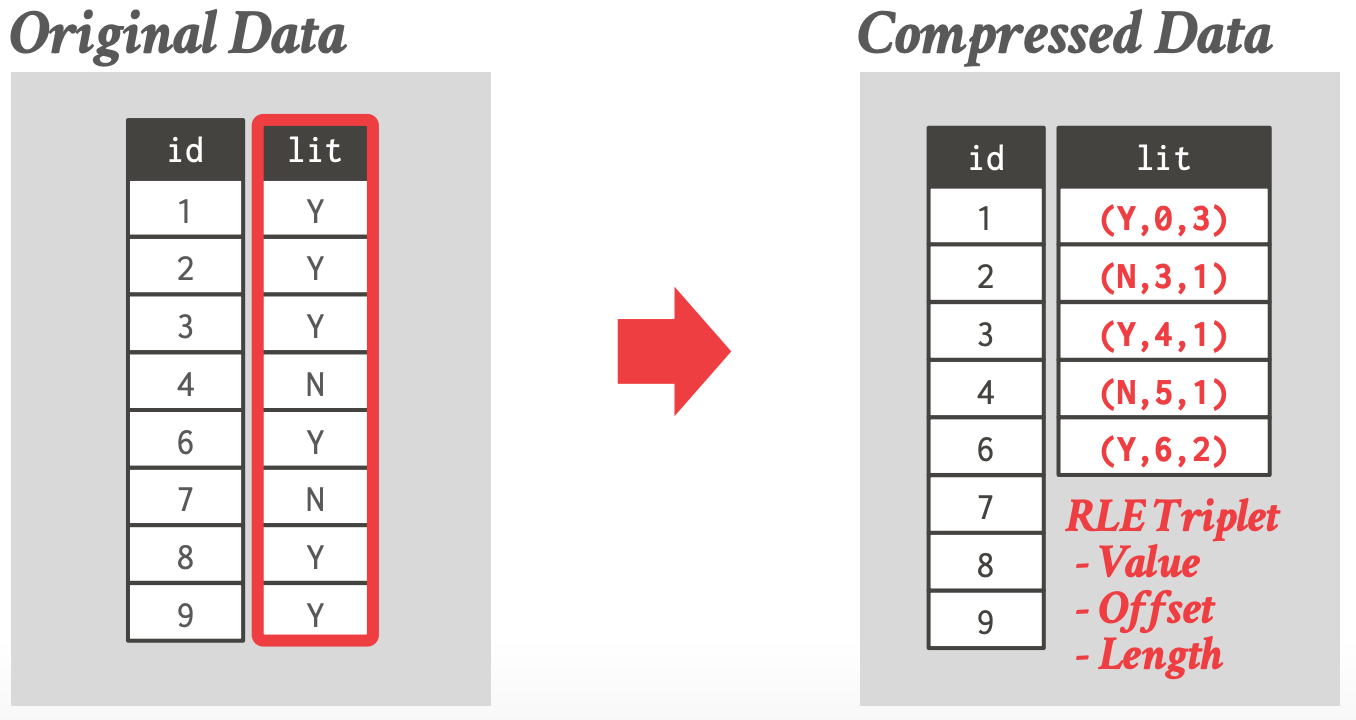
- 像查询 `SELECT lit, COUNT(*) FROM users GROUP BY lit` 可以直接在编码后的数据上执行
- 排序后,压缩的效果会很好。
## 3.2 Dictionary Compression
- 将**出现频率高**的 values 替换为更小的固定长度的 code,然后维护一个从 code 到原始值之间的一个映射(即 字典)
- 通常一个 code 对应一个列值
- 理想的字典方案对于点查和范围查询都支持快速的编码/解码
- 四个问题:
- 何时构建字典
- 字典的范围(block级别 / 表级别等)
- 字典使用的数据结构
- 字典的编码方案
### Construction
- 方案一:**All-At-Once**
- 为当前所有的 tuples 计算字典(如 immutable file)
- 容易实现
- 方案二:**Incrmental**
- 现存字典中合并新到来的 tuples
- 有可能需要对之前的 tuple 进行 **re-encoding**(例如需要 order-preserving 时可能会)
### Scope
- **Block-level**
- 字典只覆盖 table 的一个子集,每个 block 有自己的字典
- 合并多个 blocks 中的 tuples 时**必须解压**
- 相同列值在不同 block 中的 code 不一样
- 如 joins 构建 hash table 不能基于 code 构建
- **Table-level**
- 整个表一个字典
- 压缩率更好,但是更新代价很高
- **Multi-Table**
- 一些场景下,有利于 joins 和 set 操作
### Encoding / Decoding
- Encode / Locate
- Decode / Extract
- **Order-Preserving Encoding**
- 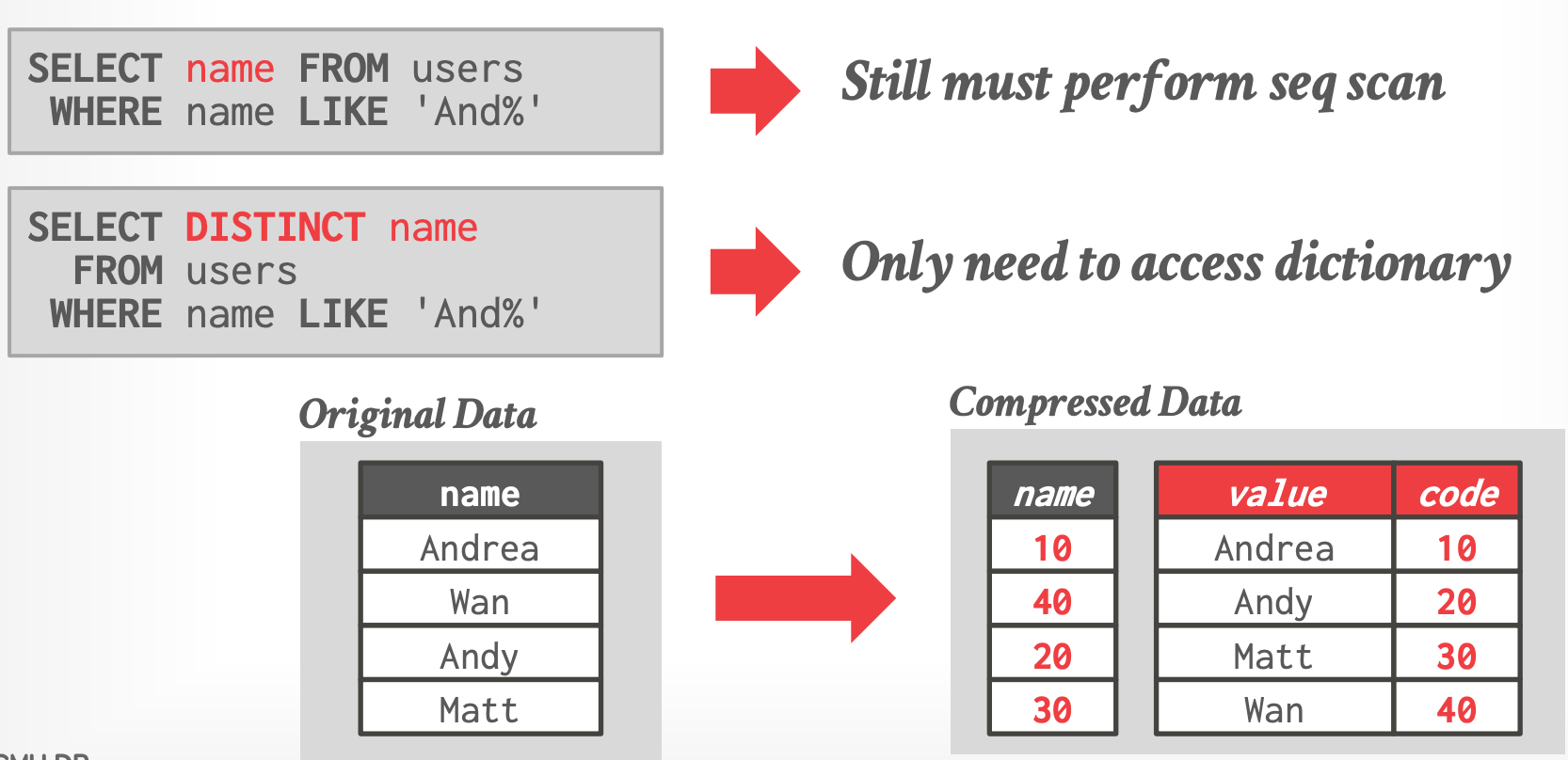
- 第一条查询的谓词可以替换为 `WHEREN name BETWEEN 10 AND 20`
### Data Structures
- **Array**
- 首先**排序**
- 存储到字节数组中(同时存储变长字符串 + offsets)
- code 是字节数组的 index
- **更新代价高**,一般只用于 immutable files
- **Hash Table**
- Fast and Compact
- 不支持 **range** 和 **prefix** 查询
- **B+ Tree**
- 比 hash table 慢,且占用更多内存
- 可以支持 range 和 prefix 查询
#### Shared-Leaves B+ Tree
- 论文:[Dictionary-based Order-preserving String Compression for Main Memory Column Stores](https://dl.acm.org/doi/10.1145/1559845.1559877)
- 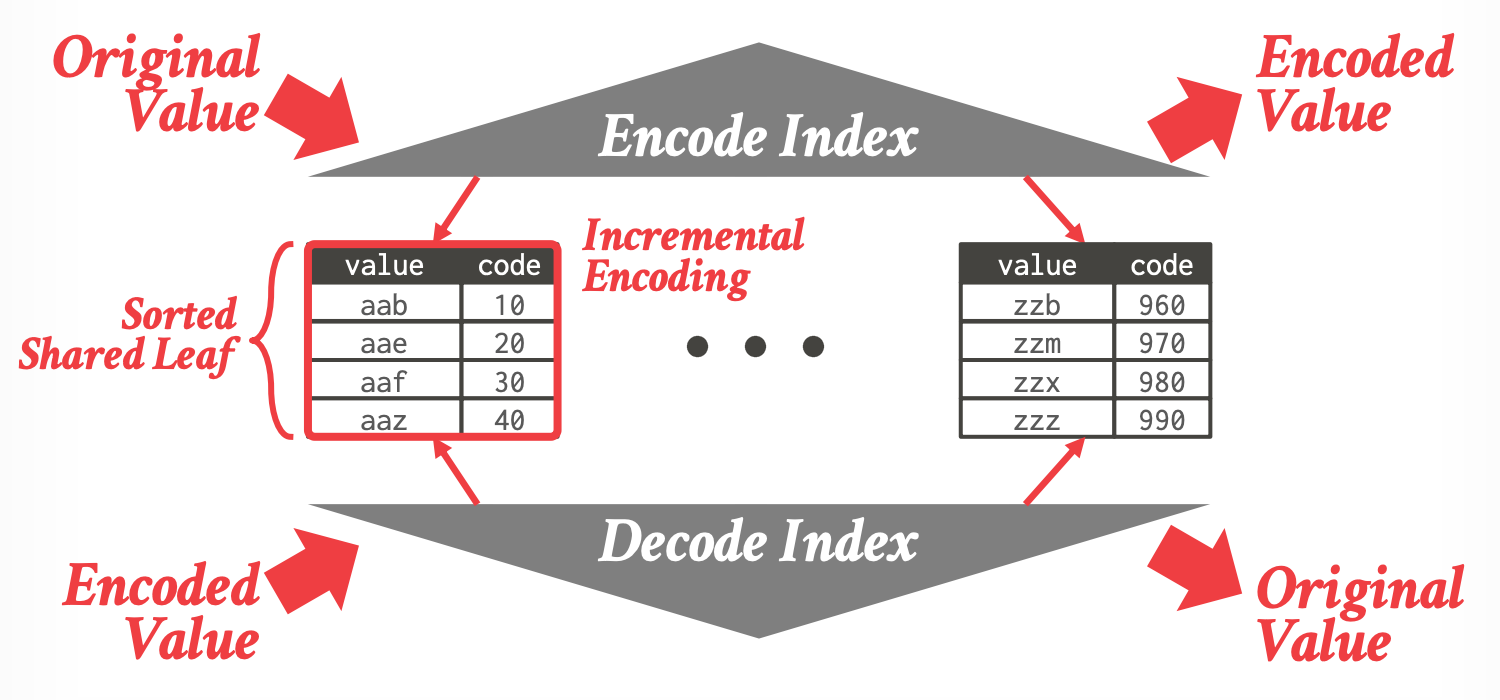
- 两个 B+ Tree 索引
- Encode Index:索引 value 到 leaves
- Decode Index:索引 code 到 leaves
- 两个索引共享 leaves
### Exposing Dictionary To DBMS
- Parquet / ORC 没有提供 API 来直接访问文件的 dictionary
- DBMS 就不能执行谓词下推(例如 **编码谓词**),不能直接在压缩过的数据上操作(除非解压)
- Google [Procella](https://dl.acm.org/doi/10.14778/3352063.3352121) 的 Artus 格式支持(但需要拷贝)
## 3.3 Bitmap Encoding
- 如果列的**基数很小**,那么使用 Bitmap 能有效减少存储大小。
- 查找 Bitmap 时,**优先查找** tuples多的(1的个数),匹配的概率更高
### Compression
- **通用的压缩**
- 标准压缩算法,Snappy、zstd 等
- 处理查询时必须先解压
- **Byte-aligned Bitmap Codes**
- structured run-length encoding compression
- **Roaring Bitmaps**
- modern hybrid of run-length encoding and value lists
### Oracle Byte-Aligned Bitmap Codes
- 根据包含的 bytes 的不同种类 ,将 bitmap 分割为 chunks
- **Gap Byte**:所有的 bits 都是 0
- **Tail Byte**:有些 bits 是 1
- 编码每个 **chunk**(包含了若干 **Gap Bytes** 再加上若干 **Tail Bytes**)
- **Gap Bytes** 使用 RLE 压缩
- **Tail Bytes** 不压缩(除非它只有一个 Byte,==或者==只有一个非 0 bit)
- Gap Bytes 小于 7 的编码方式:
- 
- 第 1-3 Bit:表示 Gap Bytes 的个数(不超过7)
- 第 4 Bit:Tail 是否是特殊的
- 第 5-7 Bit:
- 如果第 4 Bit = 0:表示后续未压缩 Tail Bytes 的个数
- 如果第 4 Bit = 1:表示 tail-byte 中 1 的位置
- Gap Bytes 大于 7 的编码:
- 
- 111 表示特殊标记(Gap Length > 1,需要额外的 Bytes 表示 gap length)
- 0 表示 Tail Bytes 不特殊
- 0010 表示后面 Tail-Bytes 的个数
- Gap Length = 13
- 最后跟两个 Tail Bytes(未压缩的)
- **Observation**
- Oracle 的 BBC 是一个过时的格式
- 压缩效果好,但是比较慢(CPU执行分支多,比如判断 Tail-Bytes 是否特殊等)
- [Word-Aligned Hybrid](https://sdm.lbl.gov/fastbit/compression.html)(WAH) 是一个专利变种,提供了更好的性能
- 都不支持随机访问(BCC 和 WAH)
### Roaring Bitmaps
- 论文:[Better bitmap performance with Roaring bitmaps](https://onlinelibrary.wiley.com/doi/abs/10.1002/spe.2325)
- 将 32 位整数存储在紧凑的两级索引数据结构中
- Dense chunks 使用 bitmaps 存储
- Sparse chunks 使用 16 位整型的 packed arrays
- Lucene、Hive、Spark、Pinot 等中都使用到了它。
- 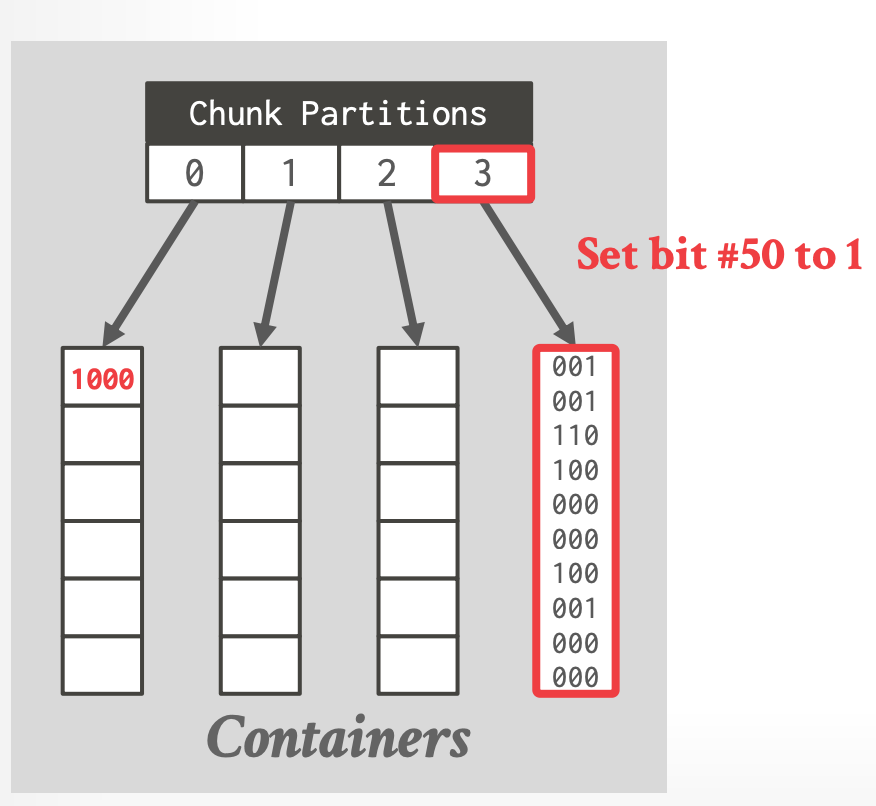
1. 每个 Value k,根据 $k / 2^{16}$ 分配 chunk container
2. 如果 container 中的 values 个数小于 4096,则存储为 array,否则存储为 Bitmap
- 例:k = 100
- $1000/2^{16} = 0$, 分配到第 0 个 chunk
- $1000 \% 2^{16} = 1000$, 直接存储到数组中
- 例:k = 199658
- $199658/2^{16}=3$,chunk 为 3
- $199658\%2^{16}=50$,设置第 50 Bit 为 1
- [ ] 两种 container 如何来回转换
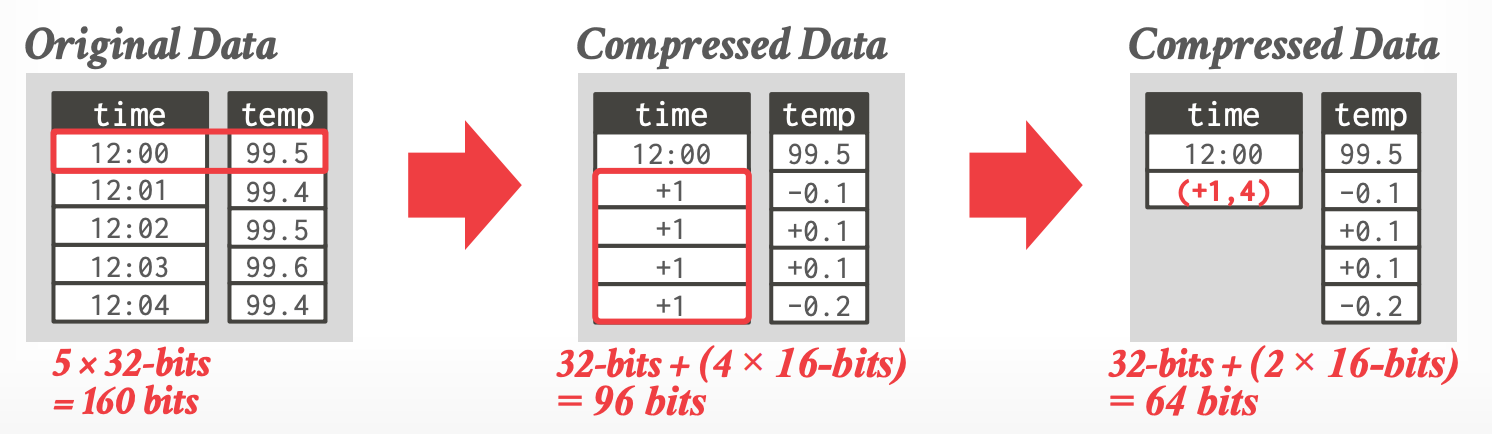
## 3.4 Delta Encoding
- 存储相邻数值间的差异
- base value 的存储可以是 in-line 或者在一个单独的 look-up table
- 可以跟 RLE 结合来获取更好的压缩率
- 
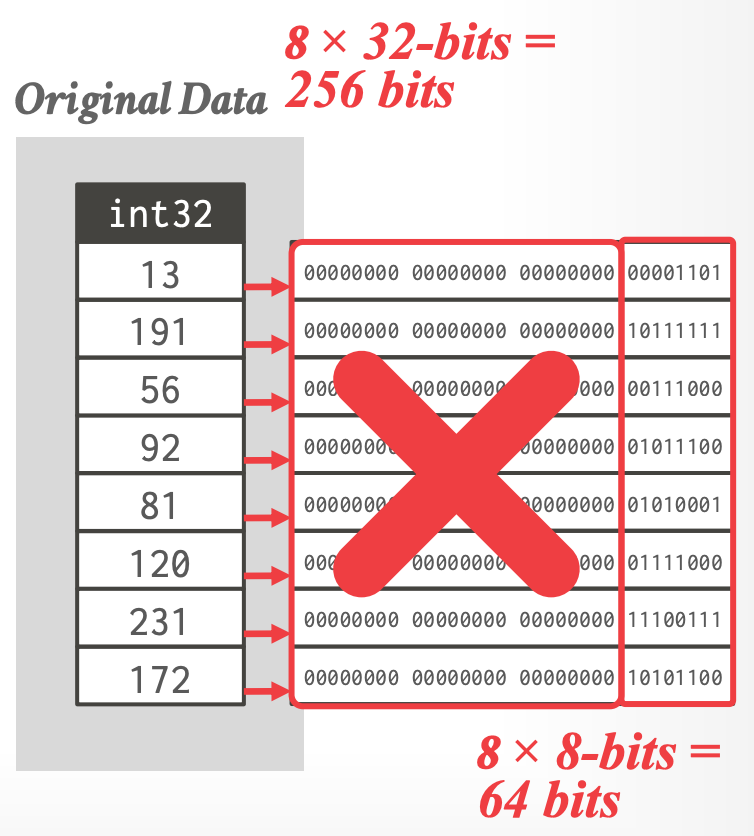
## 3.5 Bit Packing
- 如果整型列的 values 小于它的 data type size,那么减少每个 value 的位数。
- 使用 bit-shifting 在一个 word 中操作多个 values
- 
### Mostly Encoding
- Bit Packing 的变种,适用于列的**大多数** values 小于 largest size
- 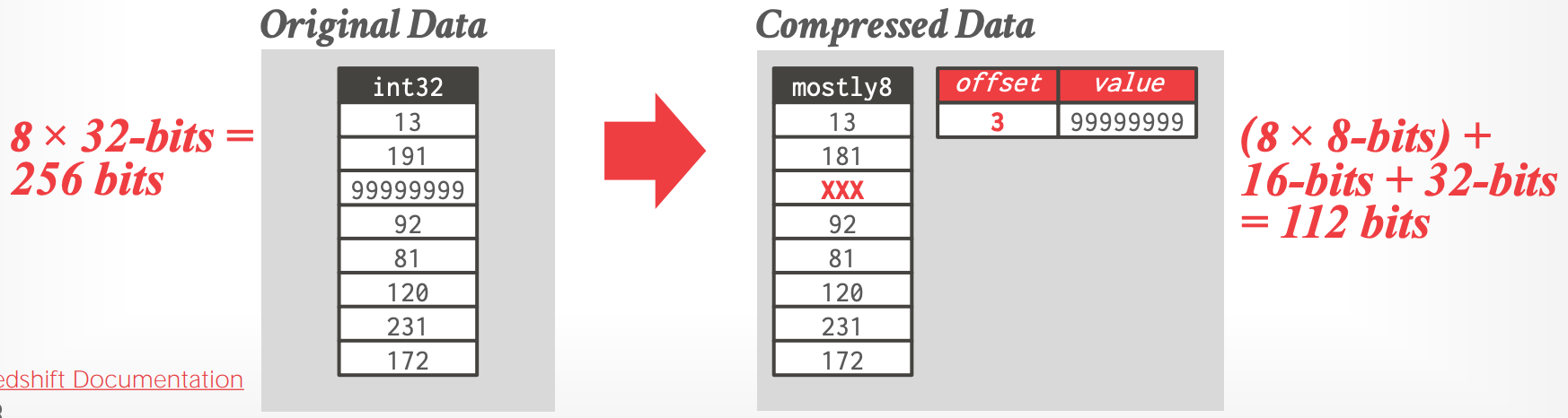
- [Redshift Documentation](https://docs.aws.amazon.com/redshift/latest/dg/c_MostlyN_encoding.html)
----------
# 4. Intermediate Data
- 在 compressed data 之上执行完计算后,DBMS 会进行 decompress,将 data 从 scan operator move 到下一个 operator。
- operator 之间传递的数据是 decompressed 的形式
- DBMS 在查询执行时一般不会 recompress data。否则执行引擎就需要嵌入解压逻辑。
---------
# Parting Thoughts
- Dictionary encoding 不总是最高效的方案,但却是最常用的
- DBMS 可以结合多种方式一起使用,来获取更好的压缩效果。