# 前言
## Execution Optimization
- DBMS 是一系列优化的编排,旨在充分利用硬件。
- 没有任何一种技术会比其他所有技术更重要(需要看场景)
- **Andy 不科学的 Top-3 优化**:
- Data Parallelization(Vectorization)
- Task Parallelization(Multi-threading)
- Code Specialization(Compilation)
## Optimization Gloals
1. **Reduce Instruction Count**
- 使用更少的指令完成相同的工作
- 例如使用 Compilation、SIMD、启用 `O2` 优化
> I personally think -O3 in general is unsafe. [By linus](https://lore.kernel.org/lkml/CAHk-=wjuoGyxDhAF8SsrTkN0-YfCx7E6jUN3ikC_tn2AKWTTsA@mail.gmail.com/)
2. **Reduce Cycles per Instuction**
- 更少的 cycles 内执行更多的 CPU 指令
- 例:减少 branching、利用 Cache 等减少 CPU stalls
3. **Parallelize Execution**
- 使用多线程并行执行查询
## Query Execution
^edad15
- **Query Plan**:DAG of operators
- **Operator Instance**:An invocation of an operator on a **unique** segment of data
- **Task**:一个或多个 operator instance 的序列(有时也称为 pipeline)
- 调度和执行的单位
- **Task Set**:一个逻辑 pipeline 的可执行 tasks 的集合
- 
----------
# 1. MonetDB/X100 Analysis
## 1.1 MonetDB/100(2005)
- 从底层分析了内存数据库在 OLAP 负载下的执行瓶颈
- 结论:对于 modern CPU 架构, DBMS 的设计不正确
- 基于上述发现,提出了新的 DBMS 即 MonetDB/X100
- 2010年,改名为 Vectorwise,被 Actian 收购
- Rebranded 为 Vector 和 [Avalanche](https://www.actian.com/analytic-database/avalanche/)
## 1.2 CPU Overview
- CPU 将指令组织成 **pipeline stages**
- 掩盖无法在单个周期内完成的指令的延迟,使处理器的所有部分在每个周期都保持繁忙。
- Super-scalar CPU 支持多条 pipelines
- **out-of-order** execution:一个周期/cycle内执行多条无关联的指令
## 1.3 DBMS / CPU Problems
- 问题一:**Dependencies**
- 如果一个指令依赖另一个指令,无法进行 out-of-order execution
- 问题二:**Branch Prediction**
- CPU 会尝试分支预测,然后将分支的指令填充到 pipeline 中
- 如果预测失败,它必须丢弃所有 speculative work 以及 flush the pipeline(然后 rollback)
- DBMS中执行最多的分支代码是顺序扫描期间的 **filter** 操作
- 但是**几乎不可能**正确地预测
- **likely,unlikely**
- 2006 后,intel 等 CPU 开始忽略它
- [`Don’t use the [[likely]] or [[unlikely]] attributes`](https://blog.aaronballman.com/2020/08/dont-use-the-likely-or-unlikely-attributes/)
## 1.4 Selection Scans
- 
- Selectivity 对分支预测的影响:
- 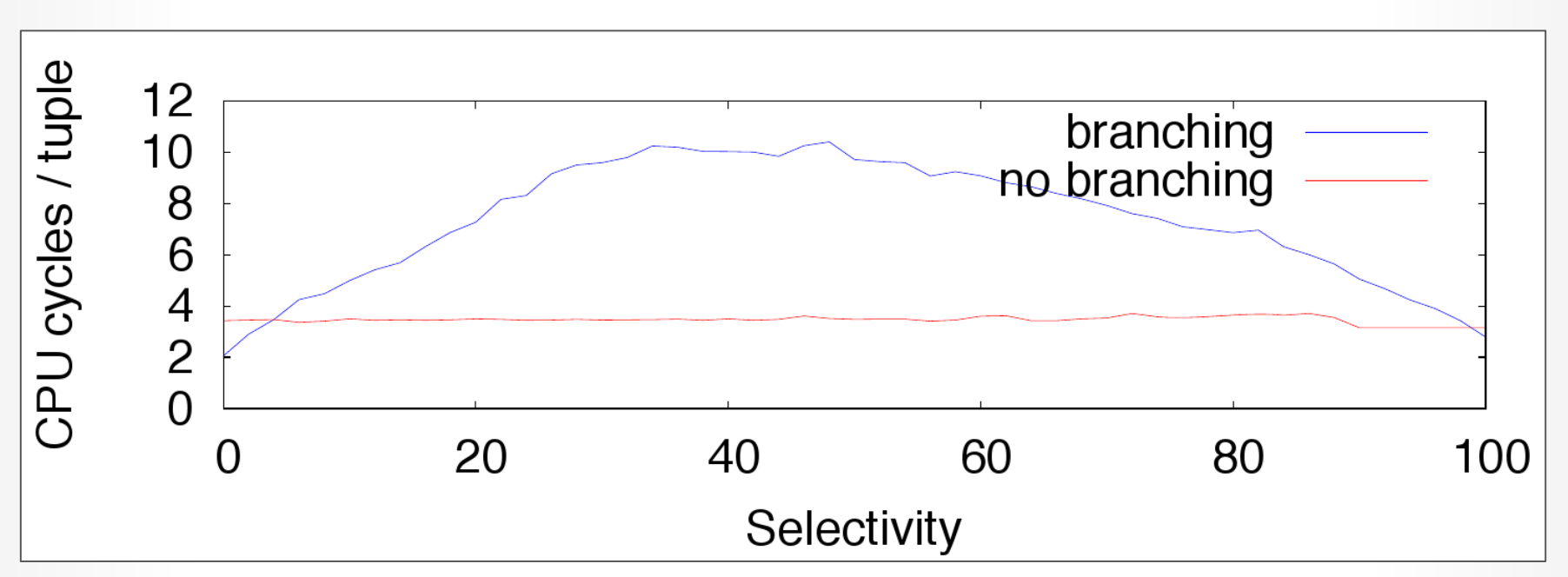
- 50%左右失败的概率最高
- Paper:[Micro adaptivity in Vectorwise](https://dl.acm.org/doi/10.1145/2463676.2465292)
## 1.5 Excessive Instructions
- DBMS 需要支持不同的数据类型,所有在对 value 执行任何操作前都必须检查 value 的 type
- 通常实现为一个很大的 switch 语句
- 创造出了更多的分支,CPU 不容易预测正确
- 例:Postgres' [NUMERIC types](https://doxygen.postgresql.org/interfaces_2ecpg_2pgtypeslib_2numeric_8c_source.html#l00722)
--------
# 2. Processing Models
- **Processing Model** 定义了系统如何执行一个 query plan
- 不同的 workloads(OLTP vs. OLAP)有不同的 trade-offs
- 三种方案:
- [[12-query-execution-1#^4a72bd |Iterator Model]]
- **Materialization Model**
- **Vectorized / Batch Model**
## 2.1 Plan Processing Direction
- **Top-to-Bottom(Pull)**
- 由 root 开始,从 children pull data
- Tuples 总是与函数调用一起传递
- **Bottom-to-Top(Push)**
- 由 leaf nodes 开始,push data 到它的 parents
- 例子:
- [Efficiently Compiling Efficient Query Plans for Modern Hardware](https://www.vldb.org/pvldb/vol4/p539-neumann.pdf)
- [Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last](http://www.vldb.org/pvldb/vol11/p1-menon.pdf)
- Snowflake
- DuckDB:[Move to push-based execution model](https://github.com/duckdb/duckdb/issues/1583)
- 好处:Keep Data in CPU Cache / Registers
### 对比
- **Pull**
- 容易实现输出控制,如 LIMIT
- Parent operator 阻塞着直到 child 返回一个 tuple
- next 虚函数带来的额外开销(还增加了额外的分支)
- **Push**
- Allows for tighter control of caches/registers in pipelines.
- 难以实现输出控制 LIMIT
- 难以实现 Sort-Merge Join
- 论文:[Push vs. Pull-Based Loop Fusion in Query Engines](https://arxiv.org/abs/1610.09166)
----------
# 3. Parallel Execution
[[13-query-execution-2#^e287a2]]
---------
# Parting Thoughts
- 大多数场景下,vectorized / bottom-up execution 是执行 OLAP 查询更好的方式。