# 前言
## Query Execution
[[06-query-execution#^edad15]]
## Scheduling
- 针对每一个 query plan,DBMS 必须决定 where、when 、how to execute it:
- 使用多少个 task
- 使用多少个 CPU cores
- tasks 在哪个 CPU core 上执行
- task 应该把输出存储到哪里
> The DBMS **always** knows more than the OS.
### Scheduling Goals
- **Throughput**
- **Fairness**
- no query is starved for resources
- **Query Responsiveness**
- 最小化 tail latencies(特别是 short queries)
- **Low overhead**
- Workers 应该在 task 执行上花费绝大多时间,而非挑选哪个 task 去执行。
--------
# 1. Worker Allocation
## 1.1 Process Model
- 一个 DBMS 的 **process model** 定义了系统是如何架构来支持来自多用户应用的并发请求。
- **Woker** 是负责代表 Client 执行任务并返回结果的 DBMS 组件。
- 一般指线程
- [Architecture of a Database System](https://dsf.berkeley.edu/papers/fntdb07-architecture.pdf)
## 1.2 Worker Allocation
- 方式一:**One Worker per Core**
- 每个 core 分配并绑定(pinned)一个线程
- 可以使用 `sched_setaffinity`
- 方式二:**Multiple Workers per Core**
- 每个 core (或者每个 socket)使用 a pool of workers
- 可以重复利用CPU(一个 worked 阻塞住时)
## 1.3 Task Assignment
- 方式一:**Push**
- 一个中心化的 dispatcher / scheduler 给 workers 分配 tasks,并且监视进度
- 当 worker 通知 dispatcher task 完成时,给它分配新 task
- 方式二:**Pull**
- Workers 从一个对列中获取任务 -> 处理 -> 再获取下一个任务
## Observation
- 不论 DBMS 使用哪种 worker allocation 或者 task assignment 策略,保证 workers 操作 local data 很重要
- DBMS 需要关注硬件的内存分布(NUMA)
- 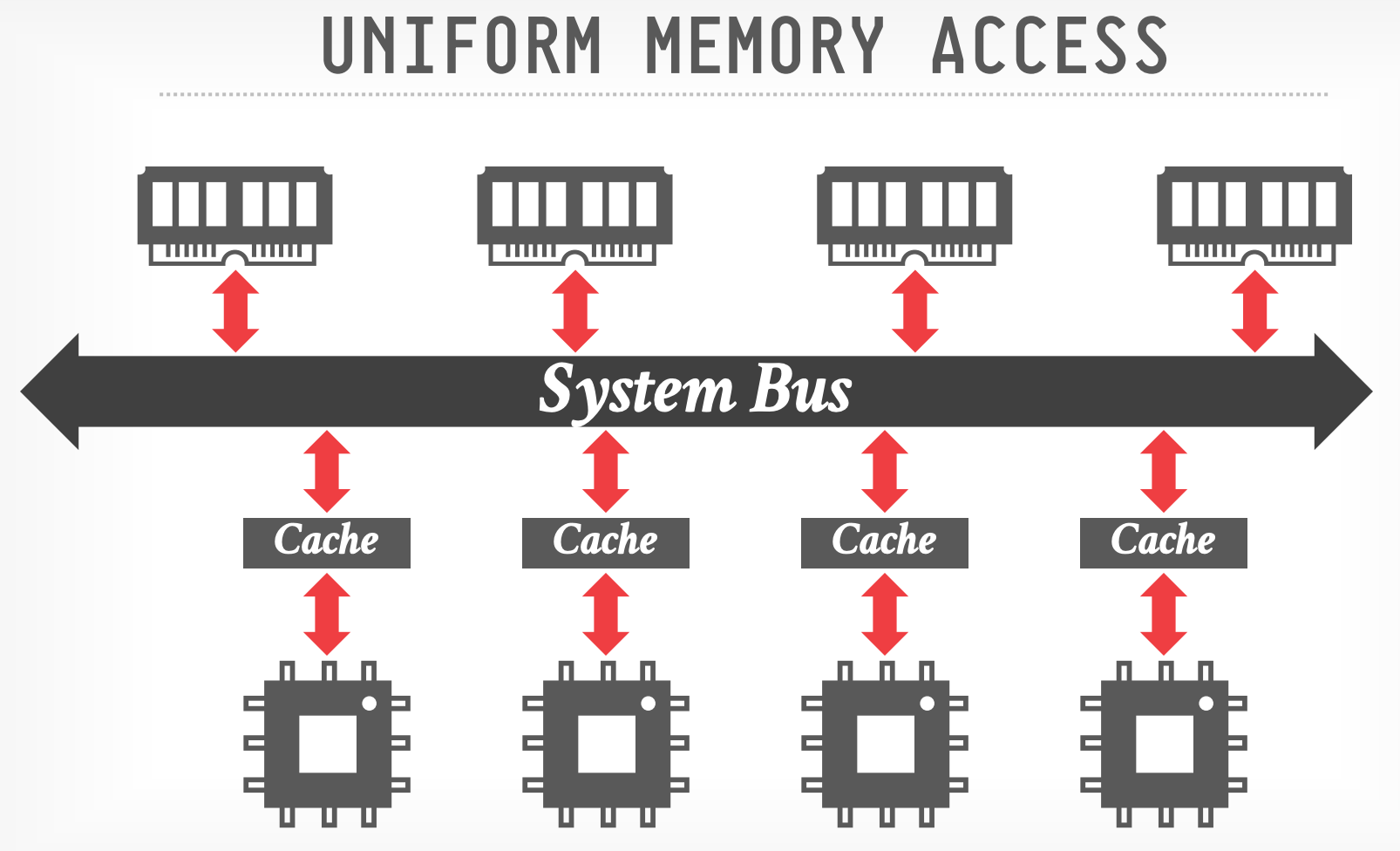
- 通过 System Bus 来访问内存
<br>
- 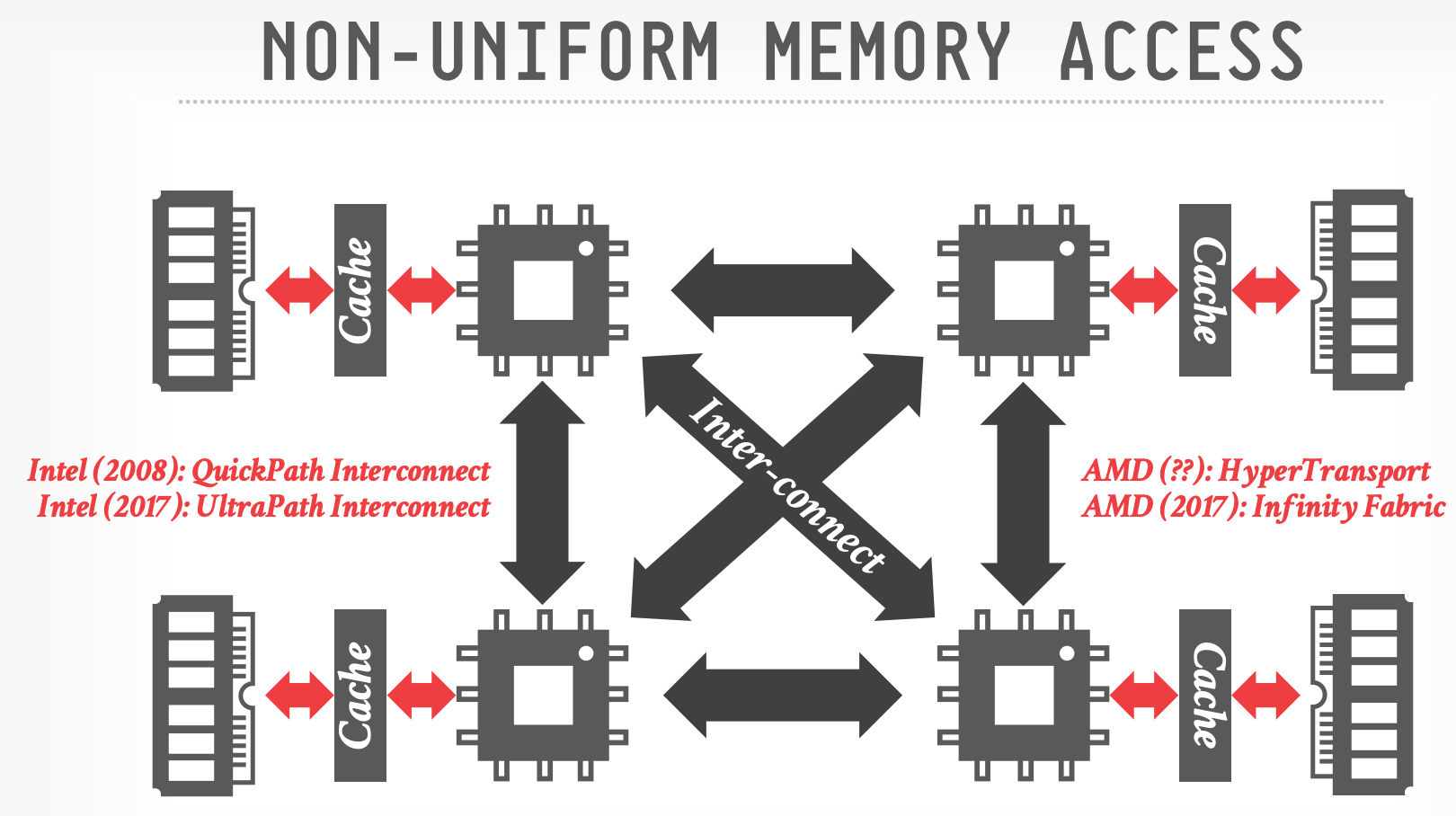
- 每个 socket 有 local memory
- 访问 remote memory 需要通过主板上的 Inter-connect(2x slower)
- Inter-connect:intel 称为 QPI / UPI
--------
# 2. Data Placement
- DBMS 可以对数据库的内存进行分区,并将每个分区分配给一个 CPU。
- 类似将数据分配到不同的机器上
- 通过控制和跟踪分区的位置,它可以将 operators 调度到最近的 CPU core 的 worker 上执行。
- 尽可能保证读的内存都是 local 的
- OS接口:Linux [move_pages](https://man7.org/linux/man-pages/man2/move_pages.2.html) 、[numactl](https://linux.die.net/man/8/numactl)
## 2.1 Memory Allocation
- 当 DBMS 调用 malloc 时:
- allocator 扩展进程的 data segment(`brk`)
- 新的 virtual memory 不会分配物理内存
- 只有访问时发生 page fault 后才会分配物理内存
- 问题:NUMA 系统中 当 page fault 后,OS 从哪里分配物理内存
### Memory Allocation Location
- 方式一:**Interleaving**
- Distribute allocated memory uniformly across CPUs.
- 方式二:**First-Touch**
- 分配在发生 page fault 时访存线程所在的 CPU
- OS 根据观测到的访问模式,可以尝试将已经分配的内存移动到其他 NUMA region。
## 2.2 Partitioning VS. Placement
- **Partitioning** 机制是基于某种策略来水平拆分 database
- Round-robin
- Attribute Ranges
- Hashing
- Partial / Full Replication
- **Placement** 机制是告诉 DBMS 这些 partitions 放到哪里
- Round-robin
- Interleave across cores
## Observation
- 目前已经讨论过:
- Task Assignment Model
- Data Placement Policy
- 下一步问题:如何从一个逻辑计划创建一组 tasks
- OLTP 相对比较容易:一个 pipeline 一个 task
- OLAP 相对困难:Pipelines 之间的依赖、task instance 更多
--------
# 3. Scheduler Implementations
## 3.1 Static Scheduling
- DBMS 在生成 plan 时决定使用多少线程来执行查询。
- **Static**:query 执行期间不会变动
- 最简单方式:使用与 CPU 核心数量相同的任务数
- 仍然根据 data location 来分配线程,最大化 local data processing
<br>
## 3.2 Morsel-Driven Scheduling
- 论文:[Morsel-driven parallelism](https://dl.acm.org/doi/10.1145/2588555.2610507)
- 实现在 Hyper 系统中
- **Morsel**:一片数据(大于 block,小于 partition)
- 动态将操作 morsels 的 tasks 调度分布到不同的核心上
- 一个 core 对应一个 worker
- 一个 task 一个 morsel
- Pull-based task assignment
- Round-robin data placement
- 支持 parallel、NUMA-aware operator implementations
### Hyper - Architecture
- 没有单独的 dispatcher 线程
- 使用一个 task queue(global),workers 执行 cooperative scheduling
- 每个 worker **优先**挑选数据(morsels)在本地的 local tasks
### Data Partitioning
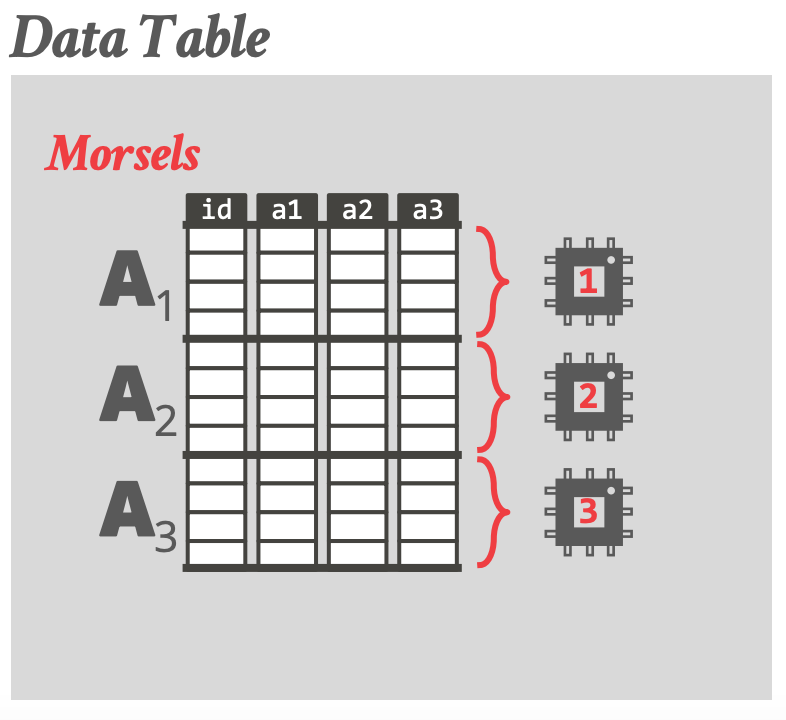
### Execution Example
- 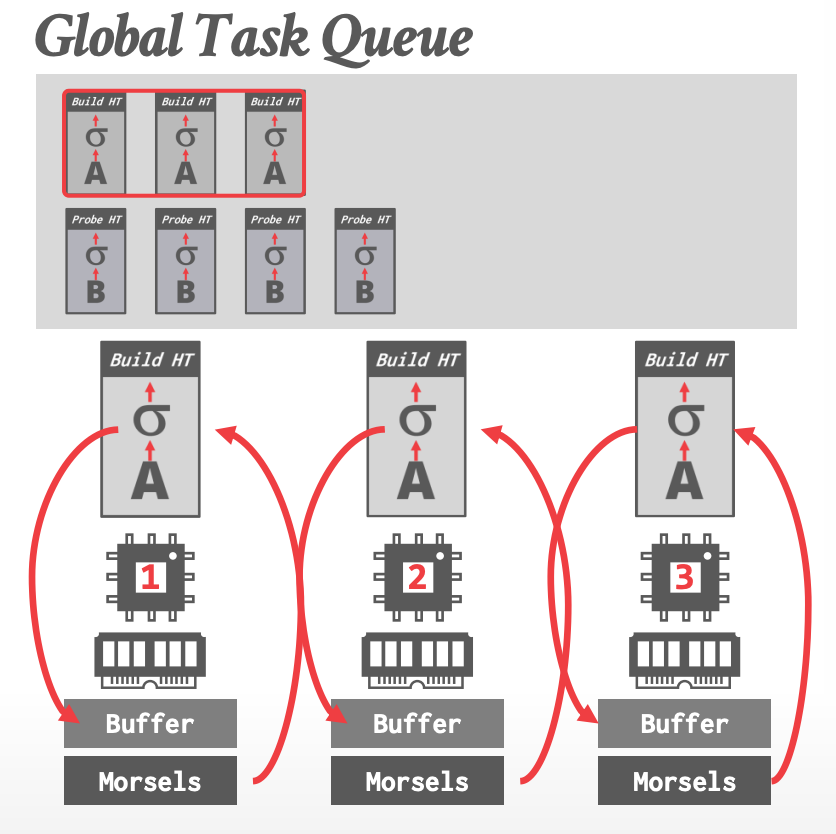
- Buffer:写入中间结果
- 读、写都是 local buffer
<br>
- 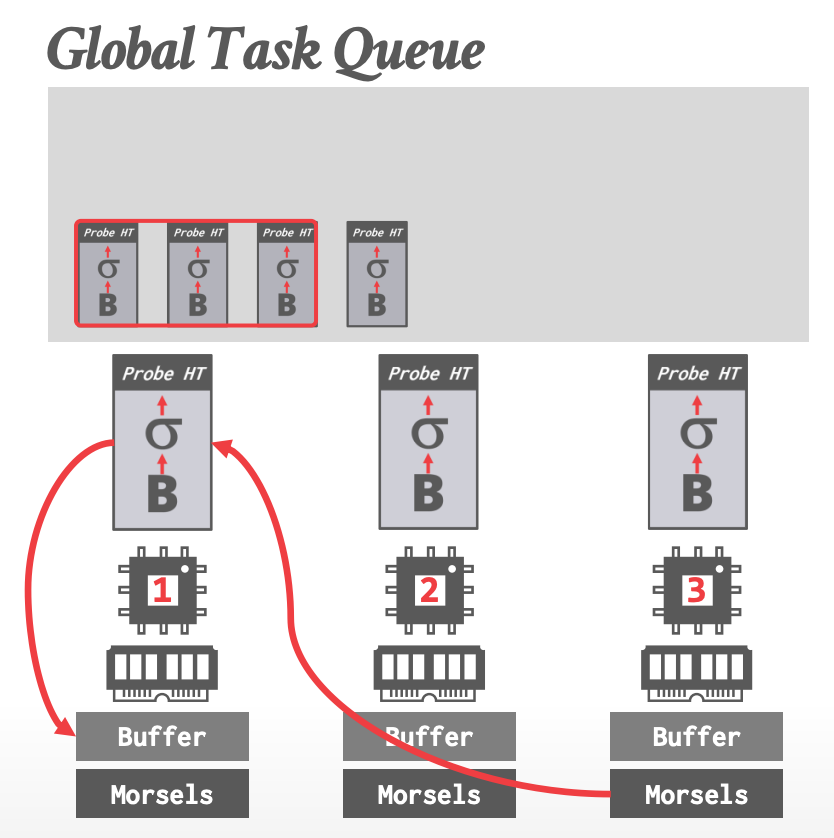
- 读 remote、写 local buffer
### Morsel-Driven Scheduling
- 每个 core 只有一个 worker,每个 task 只负责一个 morsel,Hyper 必须使用 **Worker stealing**,否则线程可能一直 idle(为了等待落后者)。
- DMBS 需要使用一个 **lock-free hash table** 来管理 global work queue。
### Observation
- Tasks 的 **每 tuple 执行成本**(execution costs per tuple)可能不同
- 虽然 morsel 是一样的(比如包含相同数量的 tuples)
- 比如 Simple Selection 与 String Matching
- Hyper 同时也没有**执行优先级**的概念
- shorting-running queris 可能被 long-running queris 阻塞
<br>
## 3.2 Umbra - Morsel Scheduling 2.0
- Tasks 不是在运行时静态创建的(not created statically at runtime).
- 每个 task 可以包含 **多个 morsels**
- stride scheduling 现代实现
- Priority decay(随着运行时间的增加降低 task 的优先级)
- 论文:[Self-Tuning Query Scheduling for Analytical Workloads](https://dl.acm.org/doi/10.1145/3448016.3457260)
### Stride Scheduling
- 每个 worker 维护自己 thread-local 的 metadata(哪些 tasks 可以执行)
- 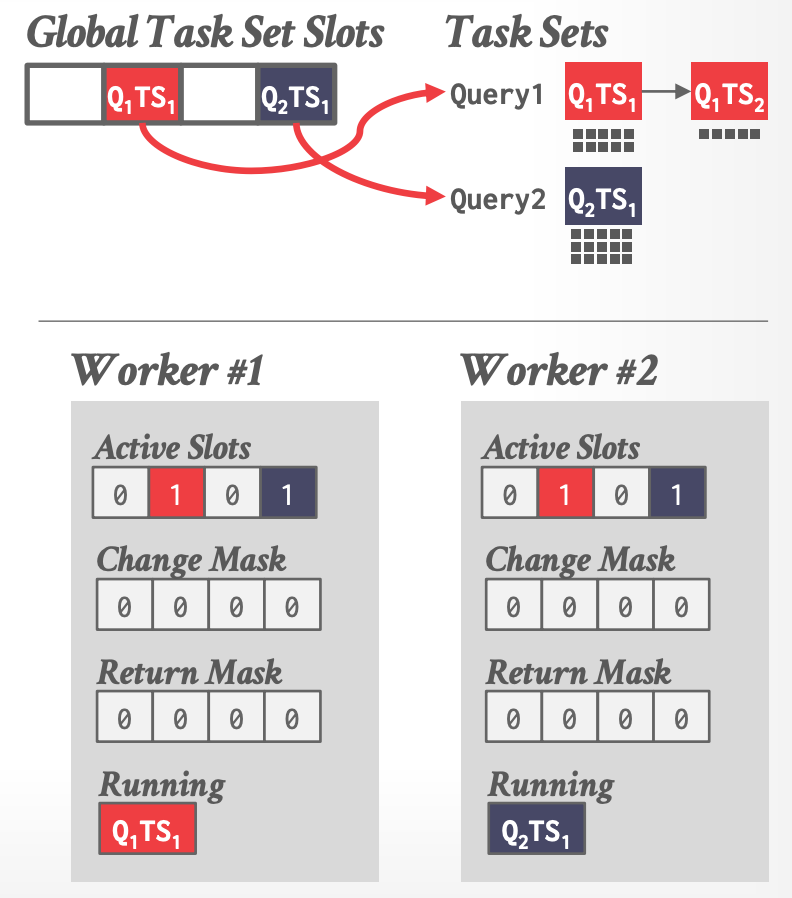
- **Active Slots**:global slot array 中哪些位置有可执行的 task
- **Change Mask**:通知新的 task set 添加到了 global slot array (比如新的查询到来 )
- **Return Mask**:通知某个 worker 完成了一个 task set
- 仍然是 pull-based 的
- Works 通过 CAS 操作 TLS metadata 来 broadcast changes。
- 当一个 worker 完成某个 task set 的最后一个 mosel 时,它负责将下一个 task set 插入到 global slot array 中,并且更新所有 workers 的 return mask。
- 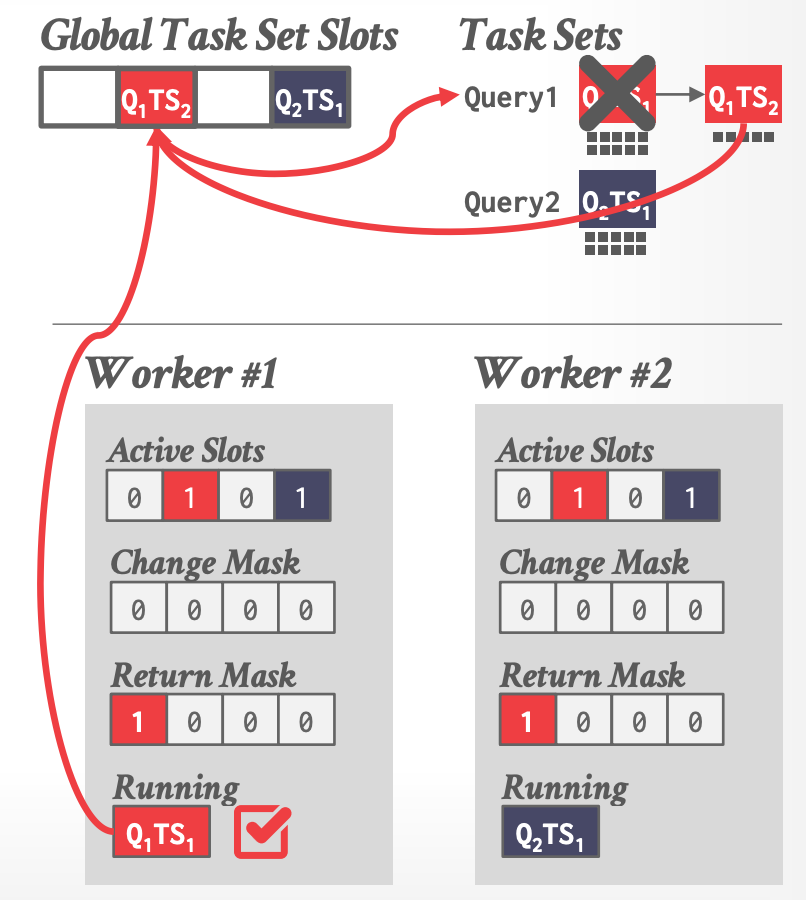
- 每个线程维护自己 local 的 task priority 信息
## 3.3 SAP HANA : Numa-Aware Scheduler
- 论文:[Scaling Up Concurrent Main-Memory Column-Store Scans: Towards Adaptive NUMA-aware Data and Task Placement](https://dl.acm.org/doi/pdf/10.14778/2824032.2824043)
- Pull-based scheduling,多个 worker threads 组织成 groups / pools。
- 每个 CPU 可以有多个 groups
- 每个 group 有一个 soft 和 hard priority queue
- **soft**:可以被 steal
- **hard**:不可以,强制运行在该 NUMA region
- 使用一个单独的 watchdog 线程来检查哪个 groups 饱和,然后可以动态重新分配 tasks。
### Thread Groups
- 每个 group 包含四种不同的 pools:
- **Working**:Actively executing a task
- **Inactive**:由于 latch 阻塞在 kernel 内
- **Free**: Busy loop,sleep 一小会儿,唤醒后查看是否有新任务要执行
- **Parked**:等待 task(类似 free thread),但是阻塞在 kernel 内,直到 watchdog 线程唤醒
### NUMA-Aware Scheduler
- 基于 task 是 CPU 还是 Memory bound 的,动态调整 thread pinning
- 如果 DBMS 是 CPU-bound 的,允许更多的 cross-region stealing
- SAP 发现对于有大量 sockets 的系统,work stealing 并不那么有利。
- 使用 thread groups,可以让 CPU cores 执行其他 task(不仅仅只是 queries)。
## 3.4 SQL Server:SQLOS
- **SQLOS** 是一个用户态的 NUMA-aware OS layer,它运行在 DBMS 内部,管理硬件资源(CPU,Disk,Memory)
- 决策哪些 tasks 运行在 哪些线程上
- 也管理 IO 调度和 high-level 的概念(如 logical database locks)
- Non-preemptive thread scheduling
- SQLOS 的 quantum 是 4 ms,但不能保障(非抢占的)
- DBMS 开发者需要添加显式的 yield
- 其他例子:
- ScyllaDB
- FaunaDB
- [CoroBase](https://github.com/sfu-dis/corobase)
---------
# 4. Flow Control
- **Admission Control**
- 系统负载高时,拒绝新的请求
- **Throttling**
- 延迟回复给客户端,来增加请求的间隔
- 假定客户端是同步提交请求的
----------
# Parting Thoughts
- 没有考虑 Disk IO schduling
- DBMS 必须正确地使用硬件
- Data location 的考量 很重要
- 在单机 DBMS 中 tracking memory location 类似在分布式 DBMS 中 tracking shards