# 1. Background
- [Compilation in the Microsoft SQL Server Hekaton Engine](http://sites.computer.org/debull/A14mar/p22.pdf)
- 减少指令数的一种方式就是 **code specialization**
- 生成一个 task / query 特定的代码
## Code Specialization
- DBMS 为执行模式相似、inputs 不同的 CPU-intenseive tasks 生成代码
- Access Methods
- Stored Procedures
- Query Operator Execution
- Predicate Evaluation(最常见)
- Logging Operators

- 方式一:**Transpilation**
- Write code that converts a relational query plan into imperative language **source code** and then run it through a conventional compiler to generate native code.
- 方式二:**JIT Compilation**
- 生成 intermediate representation(IR)
- DBMS 编译成 native code
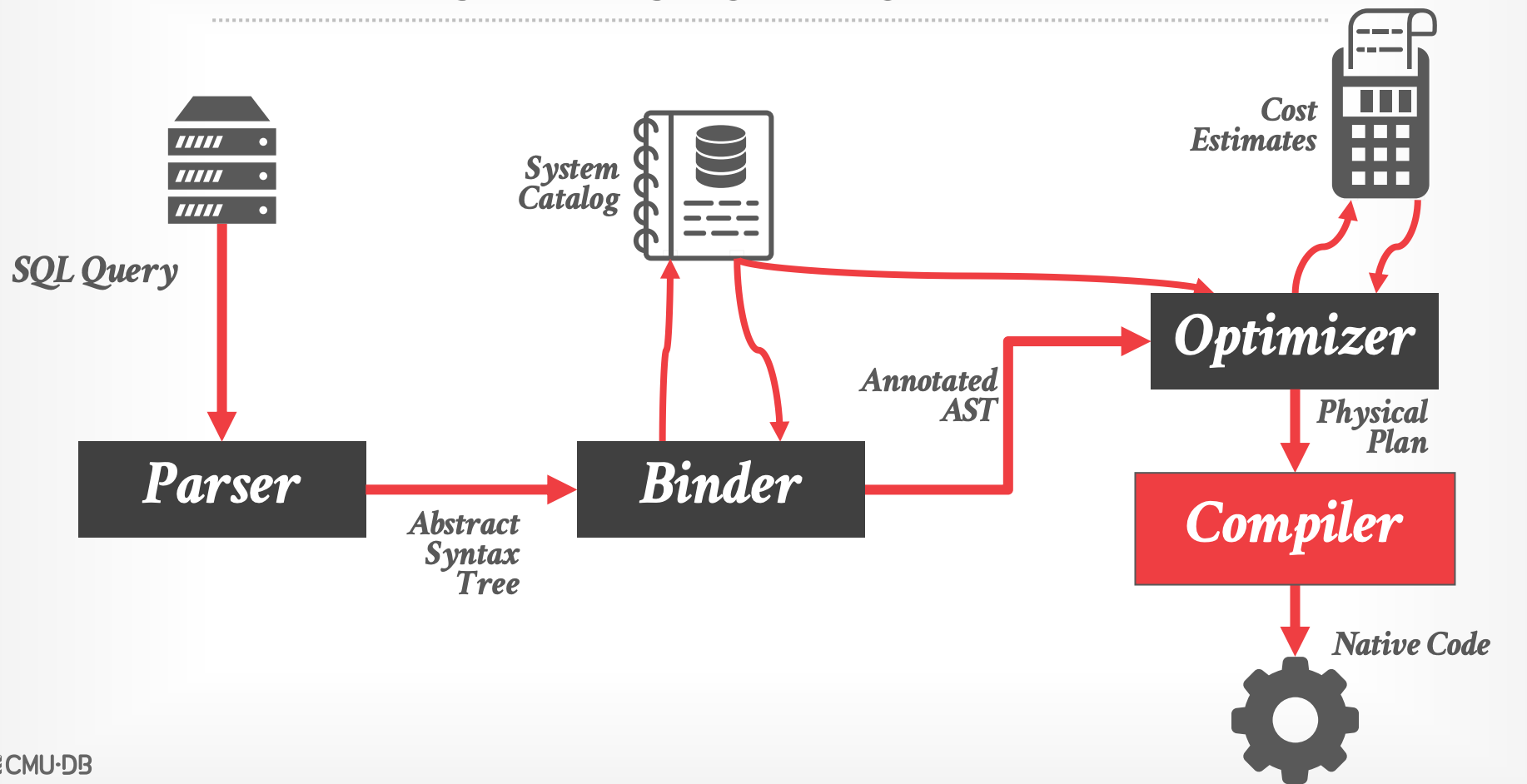
## Architecuture Overview
--------
# 2. Code Generation / Transpilation
## HIQUE - Code Generation
- [Generating code for holistic query evaluation](https://15721.courses.cs.cmu.edu/spring2020/papers/14-compilation/krikellas-icde2010.pdf)
- 针对给定的查询计划,创建一个C/C++程序来实现该查询的执行。
- Bake in all the predicates and type conversions
- 使用现成的 compiler 将 code 转换为 shared object,链接到 DBMS 进程,然后调用执行。
## HIQUE - Operator Templates
- `SELECT * FROM A WHERE A.val = ? + 1`
- 
- 不再需要 traverse expression tree
## HIQUE - DBMS Intergration
- generated query code 可以调用 DBMS 中的其他任意代码(可以跟 interperted queries 一样使用所有相同的组件)
- Network Handlers
- Bufer Pool Manager
- Concurrency Control
- Logging / Checkpoints
- Indexes
- Debugging 相对来说比较容易(调试的是 C++ 代码)
## Observation
- relational operators 是推理查询的有用方式,但不是执行查询的最有效方式。
- 将 C/C++ 代码 compile 成可执行代码,需要耗费相对**较长**的时间
- HIQUE 不支持 full pipelining。
------
# 3. JIT Compilation
## Hyper - JIT Query Compilation
- [Efficiently Compiling Efficient Query Plans for Modern Hardware](https://15721.courses.cs.cmu.edu/spring2020/papers/14-compilation/p539-neumann.pdf)
- 使用 LLVM toolkit 在内存中将查询编译成 native code。
- Hyper 输出的不是 C++ 代码,而是 LLVM IR。
- 在管道内进行积极的 **operator fusion**,以尽可能长时间地将 tuple 保留在CPU寄存器中。
## Push-based Execution
- 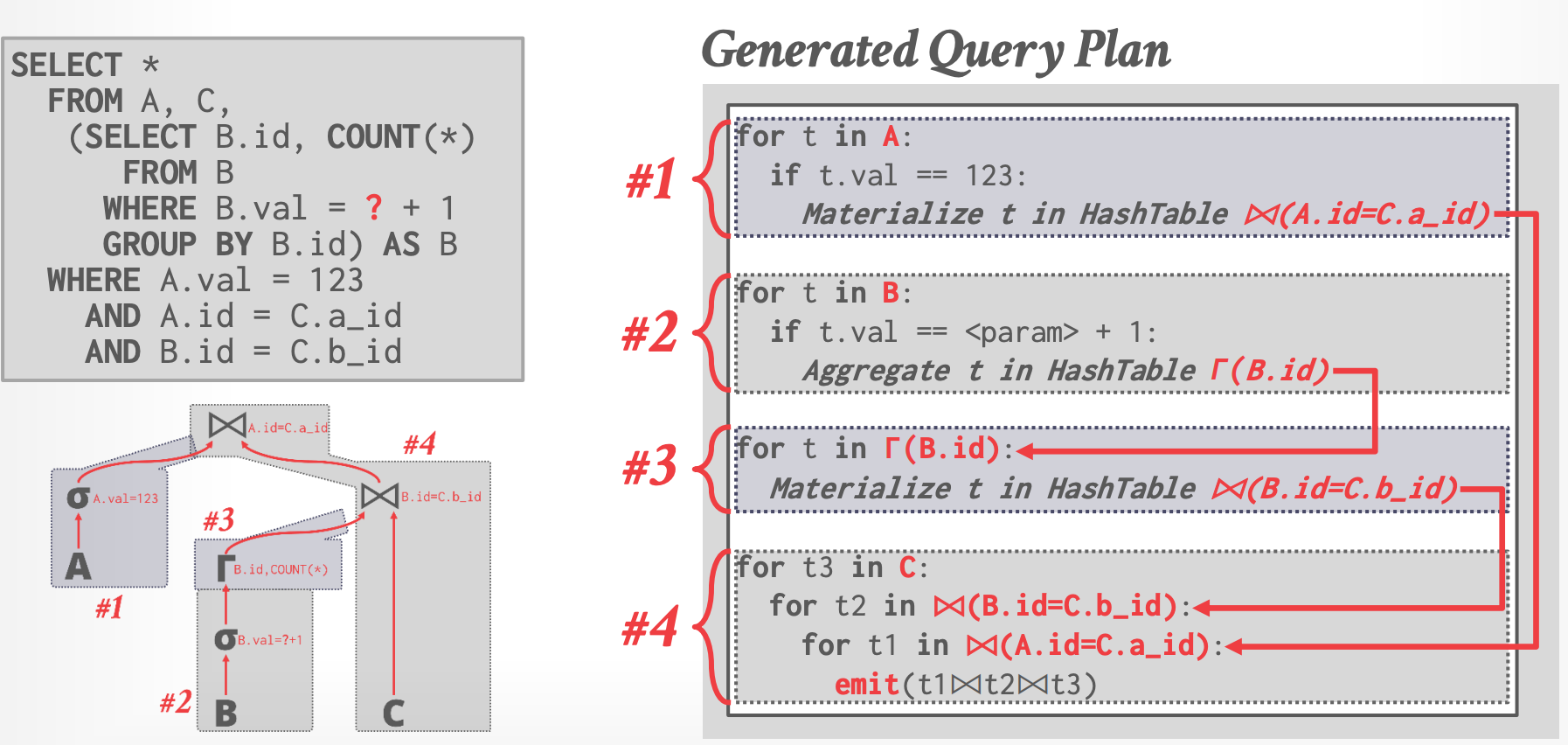
- 从 leaf node 开始,在 pipeline 中尽可能地往上 push tuple
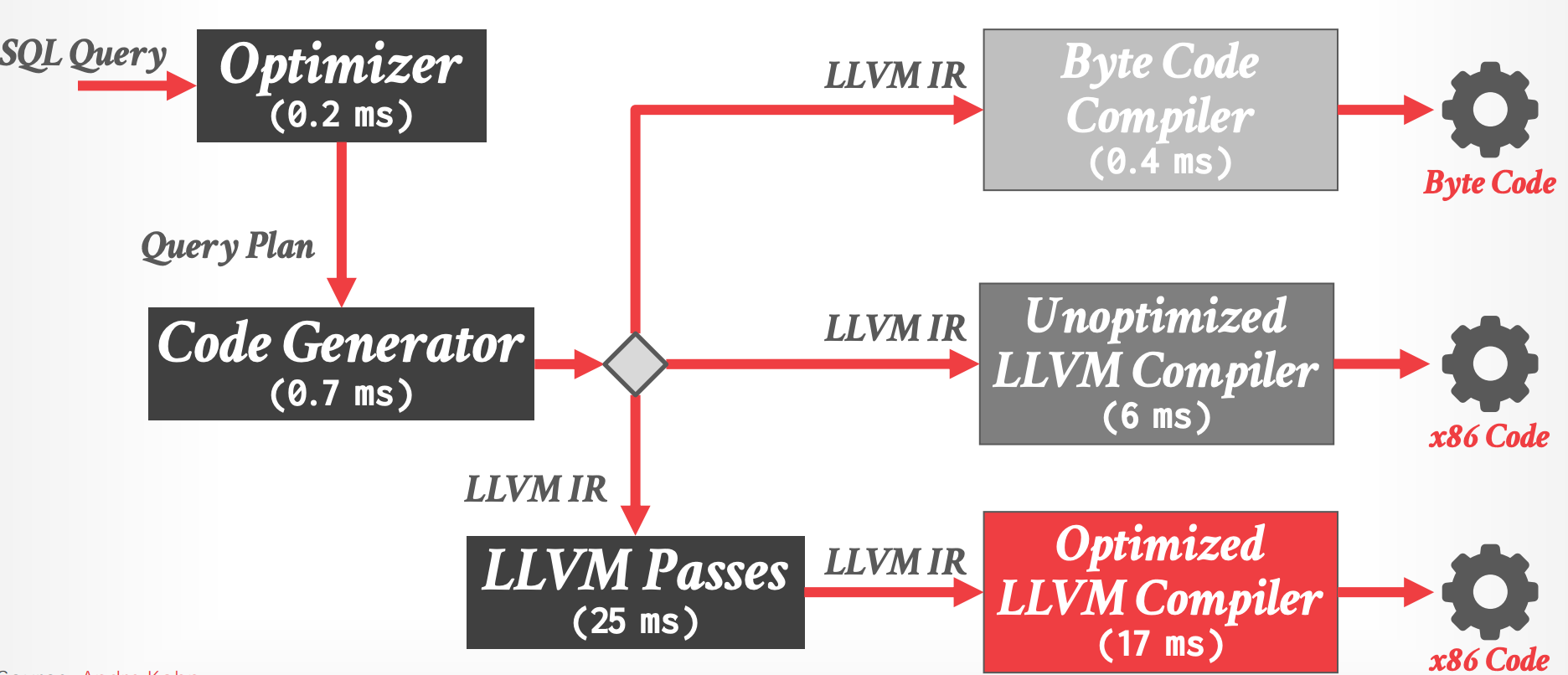
## Query Compilation Cost
- Hyper 的 query compilation time 与查询大小呈超线性增长。
- joins 的数量
- predicates 的数量
- aggregations 的数量
- 对于 OLTP 应用问题不大
- 经常使用 prepared 语句,相同的语句(不同输入)反复查询
- redshift:compiled query cache(缓存 fragment 级别)
## Hyper - Adaptive Execution
- [Adaptive Execution of Compiled Queries](https://15721.courses.cs.cmu.edu/spring2020/papers/14-compilation/kohn-icde2018.pdf)
- 为查询生成 LLVM IR 后,使用 interpreter 马上开始执行 IR;
- DBMS 在后台 compiles the query
- 当 compiled query 完成后,无缝替换掉 interpiretive execution
- 针对每个 morsel,检查是否有可用的 compiled version
- 
---------
# 4. Real-world Implementations
- **Custom**
- IBM System R
- Actian Vector
- Amazon Redshift
- Oracle
- Microsoft Hekaton
- SQLite
- TUM Umbra
- **JVM-based**
- Apache Spark
- Neo4j
- Splice Machine
- Presto / Trino
- **LLVM-based**
- SingleStore
- VitesseDB
- PostgreSQL(2018)
- CMU Peloton
- CMU NoisePage
## IBM System R
- [A history and evaluation of System R](https://dl.acm.org/doi/10.1145/358769.358784)
- IBM 在1970年代使用了一种原始的代码生成和查询编译形式
- 通过为每个 operator 选择 code templates,将编译后的 SQL 语句转换成汇编代码。
- IBM 在1980年代构建 SQL/DS 和 DB2 时废弃了该项技术
- 外部函数调用带来的很高开销(调用segments)
- 可移植性差
- 工程实现复杂
## Actian Vector
- [Micro adaptivity in Vectorwise](https://dl.acm.org/doi/10.1145/2463676.2465292)
- **预编译**几千个 primitives(在 typed data 上执行基础操作)
- 示例:通过在特定类型的某一列上应用小于运算符来生成 a vector of tuple ids。
- 执行查询计划时,在运行时调用这些 primitives
- 一次处理多个 tuples 来摊销函数调用
- primitives示例:
```c
size_t scan_lessthan_int32(int *res, int32_t *col, int32_t val) {
size_t k = 0;
for (size_t i = 0; i < n; i++)
if (col[i] < val) res[k++] = i;
return (k);
}
```
## Amazon RedShift
- [AMAZON REDSHIFT RE-INVENTED](https://dl.acm.org/doi/10.1145/3514221.3526045)
- 将 query fragments 转换为 templated C++ code
- Push-based execution with vectorization
- DBMS 检查每个 templated fragment 是否在客户的 local cache 中存在 compiled version
- 如果 local cache 中不存在,会再检查 global cache(**所有客户的**)
## Oracle
- 将 PL/SQL 存储过程转换为 `Pro*C` 代码,然后编译成本地的C/C++代码。
## Microsoft Hekaton
- [Compilation in the Microsoft SQL Server Hekaton Engine](http://sites.computer.org/debull/A14mar/p22.pdf)
- 可以编译 procedures 和 SQL
- 从 imperative syntax tree 生成 C 代码,编译成 DLL,在运行时链接
- 采用安全措施防止有人在查询中注入恶意代码。
## SQLite
- DBMS 将 query plan 转换为 opcodes,然后在一个自定义的 VM(bytecode engine)中执行。
- 也称为 Virtual Database Engine(VDBE)
- opcode 的标准可能随着版本而变化
- [The SQLite Bytecode Engine](https://www.sqlite.org/opcode.html)
## TUM UMBRA
- [Tidy Tuples and Flying Start: fast compilation and fast execution of relational queries in Umbra](https://dl.acm.org/doi/10.1007/s00778-020-00643-4)
- "FlyingStart" adpative execution framework
- 从 custom IR 直接生成 x86 汇编
- DBMS 基本上是一个 compiler
## Apache Spark
- [Spark SQL: Relational Data Processing in Spark](https://dl.acm.org/doi/10.1145/2723372.2742797)
- 2015 年引入新的 Tungsten engine
- 将查询的 **WHERE** 从句的表达式树转化为 Scalar ASTs
- 然后编译这些 ASTs,来生成 JVM bytecode,再执行(natively)。
- 2010年 Databricks 在新的 Photon engine 中废弃了这种方式
## Java Databases
- JVM-based DBMSs,输出 JVM bytecode
- Neo4j
- Splice Machine
- Presto / Trino
- Derby
- 类似于生成 LLVM IR
## SingleStore(Pre-2016)
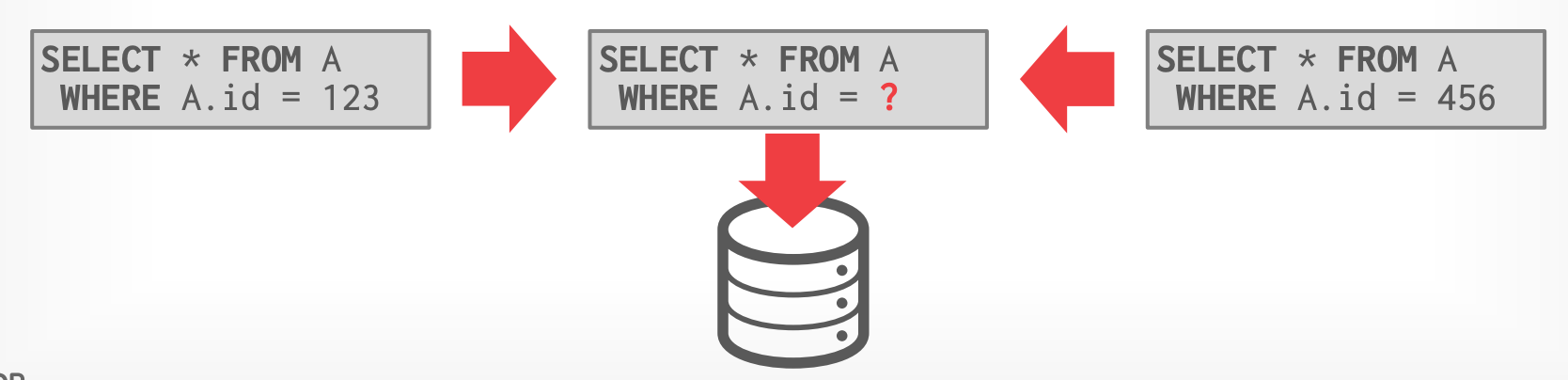
- 跟 HIQUE 一样生成 C/C++ 代码,然后调用 GCC
- 将所有查询转换为 parameterized 形式,并**缓存**编译后的查询计划
- 
## SingleStore (2016-Present)
- 将 query plan 转换为使用高级 imperative DSL 表达的 imperative plan
- [MPL](https://docs.singlestore.com/managed-service/en/query-data/code-generation.html)
- 可以将它看作是一种 C++ 方言
- DBMS 接着将 DSL 转换为 custom opcodes
- MemSQL Bit Code(BMC)
- 可以认为是 JVM byte code
- 最后,DBMS 将 bytecodes 编译成 LLVM IR,然后到 natvie code
## PostgreSQL
- 2018 年支持使用 LLVM JIT 编译 predicates 和 tuple 反序列化
- 依赖 optimizer estimates 来决定何时编译 expressions
## VitessDB
- [Vitesse DB: 100% PostgreSQL, 100 Times Faster for Analytics](https://www.youtube.com/watch?v=PEmVuYjhQFo)
- 使用 LLVM + intra-query parallelism 来加速查询 Postgres / Greenplum
- JIT predicates
- Push-based processing model
- Indirect calls 变为 direct 或者 inlined
- 利用硬件来检测 overflow
## Peloton(2017)
- 使用 LLVM,采取 Hyper 方式,编译整个 query plan
- Relax pipeline breakers,创建 min-batches 来向量化
- software pre-fetching to hiden memory stalls
- [Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last](https://15721.courses.cs.cmu.edu/spring2018/papers/22-vectorization2/menon-vldb2017.pdf)
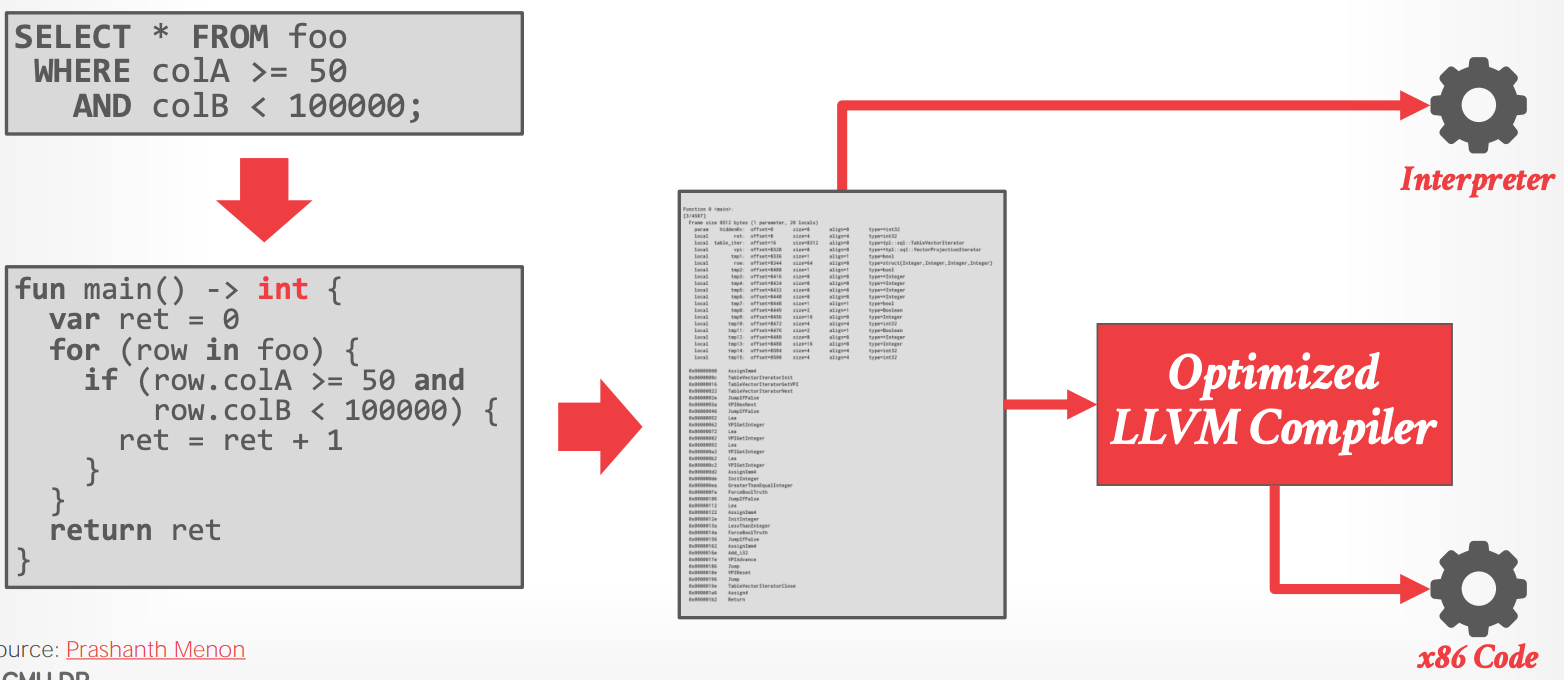
## CMU NoisePage(2019)
- SingleStore 的方式,将查询计划转换为面向 database 的 DSL
- DSL:更容易解释运行和后续编译
- DSL 编译成 opcodes
- interpret opcodes,同时在后台使用 LLVM 编译
- 
------
# Parting Thoughts
- Query compilations 有价值,但是不容易实现
- MemsQL 的 2016 版本是目前最好的查询编译实现
- 任何想要竞争的新DBMS都必须实现查询编译
---
# Note
- 编译的范围
- predicate
- 表达式
- 整个 query plan
- parametered + cache