# 1. Background
## VectorWise - PreCompiled Primitives
- 预编译 primitives
- primitive:在 typed data 上执行简单的操作
- 操作简单意味着更容易向量化
- DBMS 在执行 query plan 时运行时调用 primitives(通过函数调用)
- 一次处理多个 tuples 来均摊函数调用的开销
- primitive 的输出:满足 predicate 的 tuple offsets(类似 bitmap)
- 
## Hyper - Holistic Query Compilation
- 使用 LLVM 将查询编译成 native code
- Push-based query processing
- 尽可能地将 tuple 保持在 CPU 寄存器中
--------
# 2. Vectorization vs. Compilation
- [Everything you always wanted to know about compiled and vectorized queries but were afraid to ask](https://dl.acm.org/doi/abs/10.14778/3275366.3284966)
## Implementations
- 方式一:**Tectorwise**
- 将操作分解为 pre-compiled primitives
- 每一步必须 materialize primitives 的输出,再传递给下一个 primitive
- 方式二:**Typer**
- Push-based processing mode,加上 JIT 编译
- 不物化中间结果,Process a single tuple up entire pipeline
## TPC-H Workload
- [TPC-H Analyzed: Hidden Messages and Lessons Learned from an Influential Benchmark](https://homepages.cwi.nl/~boncz/snb-challenge/chokepoints-tpctc.pdf)
- [cmu-db/benchbase](https://github.com/cmu-db/benchbase/tree/main/src/main/java/com/oltpbenchmark/benchmarks/tpch/procedures)
- Java TPC-H queries
## Main Findings
- 两种模型都很高效,达到差不多相同的性能
- 比行存 DBMSs 快了 100 倍
- Data-centric 更适合 calculation-heavy 的查询,cache misses 更少
- Vectorization 在 hiding cache miss latencies 方面稍微好一些
- 一次处理多个 tuples
## SIMD Preformance
- AVX-512 有专门的 bitmask registers,适合 selective operations
## Auto-Vectorization
- 评估编译器在自动向量化 Vectorwise primitives 时的表现
- 目标:GCC v7.2,Clang v5.0,ICC v18
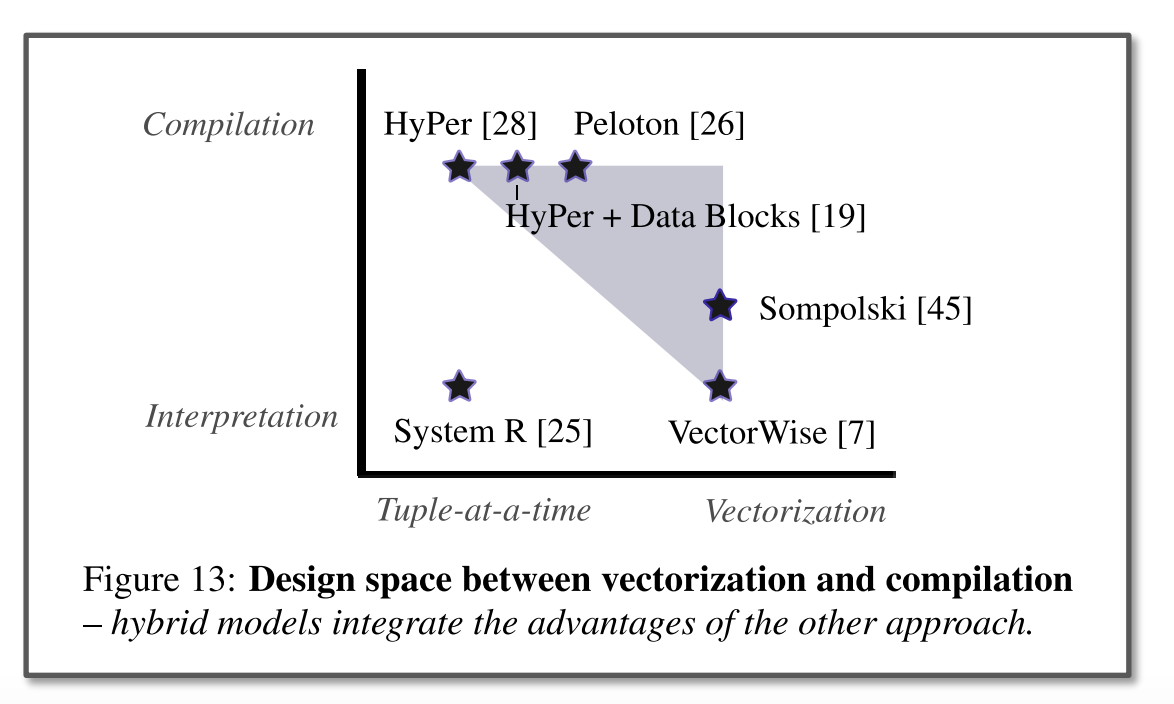
## Vectorization VS. Compilation
- 
------------
# Parting Thoughts
> No major performance difference between the Vectorwise and HyPer approaches for all queries.
- 大多数 OLAP 数据库都选择了向量化,更容易实现、Debug