# 1. Background
## 1.1 Architecture Overview
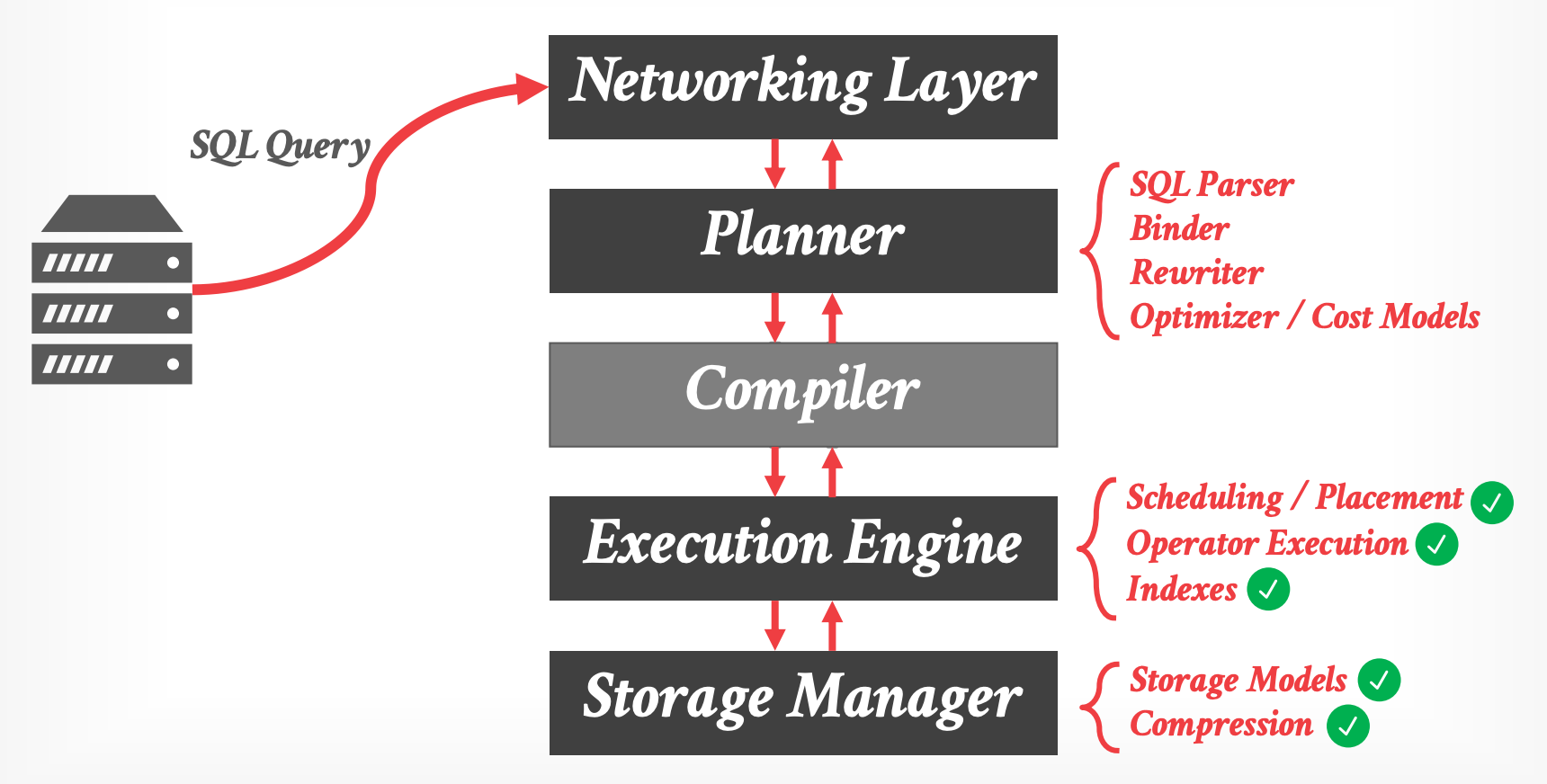
- 
---------
# 2. Database Access APIs
- 现实中的程序往往通过 API 来访问 database
- Direct Access(DBMS特定的),比如 MySQL 的 C 客户端
- ODBC([Open Database Connectivity](https://en.wikipedia.org/wiki/Open_Database_Connectivity))
- JDBC([Java Database Connectivity](https://en.wikipedia.org/wiki/Java_Database_Connectivity))
## 2.1 ODBC
- 访问 DBMS 的标准 API,设计成独立于 DBMS 和 OS。
- 最初在 1990s 初由 Microsoft 和 Simba Technologies 开发
- 每个主流的关系型数据库现在都有 ODBC 的实现
- ODBC 基于 [device driver](https://en.wikipedia.org/wiki/Device_driver)模型
- driver 负责将标准命令转换成 DBMS 特定的调用
- 
- driver 可以模拟一些 DBMS 没有提供的特性,如 Cursor
## 2.2 JDBC
- 由 Sun 在 1997 年开发,为 Java 程序连接数据库提供了标准的 API
- JDBC 可以认为是 Java 版本的 ODBC(ODBC 是 C 语言编写的)
- JDBC 支持不同的 client 侧的配置,因为可能有些 DBMS 没有 native 的 Java driver
- 不同的实现方式:
- ~~**JDBC-ODBC Bridge**(~~2014年移除)
- 将 JDBC 的方法调用转换成 ODBC 的方法调用(适用于没有 jave native driver 的情况)
- **Natvie-API Driver**(JNI 调用 C library)
- 将 JDBC 方法调用转换成目标 DBMS 的 native calls
- **Network-Protocol Driver**
- Driver 连接到一个单独进程中的中间件,该中间件将 JDBC 调用转换为 DBMS 特定的协议
- **Database-Protocol Driver**(最好的方式)
- 纯 Java 实现,将 JDBC 调用直接转换成 DBMS 特定的协议
--------
# 3. Database Network Protocols
- 所有主流的 DBMSs 都在 **TCP/IP** 上实现了自己专有的客户端通信协议。
- 如果应用也运行在相同的机器上,可以使用 Unix domain sockets
- 一个典型的 client/server 交互:
- client 连接到 DBMS 后开始认证流程,可能会需要 SSL / TLS handshake
- client 发生一个 query
- DBMS 执行 query,然后序列化结果,返回给 client
## 3.1 Existing Protocols
- 大多数**新的系统**实现了一种开源的 DBMS wire protocols,这样可以重用现有的 client driver 而不用再单独开发一个。
- MySQL
- PostgreSQL
- Redis
- 实现协议不意味着完全兼容
- 需要支持 catalogs、SQL dialect 和其他功能
## 3.2 Protocol Design Space
- [Don't hold my data hostage: a case for client protocol redesign](https://dl.acm.org/doi/10.14778/3115404.3115408)
- Design Space:
- Row vs. Column Layout
- Compression
- Data Serialization
- String Handling
- 重新设计意味着需要更改 / 开发新的 Driver
### 3.2.1 Row vs. Column Layout
- ODBC / JDBC 都是 row-oriented APIs
- server 逐个将 tuple 打包到 messages 中
- client 逐个反序列化 tuple
```C++
String sql = "SELECT * FROM xxx";
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) { // Do something magical row by row!
rs.getInt(1);
rs.getString(2);
rs.getDate(3);
}
stmt.close();
```
- 但是切换成 column-oriented API 也不高效,因为 client 可能需要访问一个 tuple 的多个列
- **Soluntion:Vector-oriented API**
- 行列混合
- Apache Arrow(ADBC)
### 3.2.2 Compression
- **方式一:Naive Compression**
- 传输 message chunks 之前应用通用压缩方案(lz4、gzip、zstd)
- 只有很少的系统支持这个 ([Oracle](https://blogs.oracle.com/dbstorage/post/advanced-network-compression-a-lessor-known-feature-of-advanced-compression), [MySQL](https://dev.mysql.com/doc/refman/8.0/en/connection-compression-control.html)).
- **方式二:Columnar-Specific Encoding**
- 分析结果、为每列挑选特定的压缩编码(dictionary、RLE、delta)
- 没有系统实现这个
- 当网络慢时,使用重量级的压缩更好
- message chunks sizes 越大,压缩率越高
### 3.2.3 Data Serialization
#### Binary Encoding
- client 处理 endian conversion
- 序列化格式与 DBMS 的存储格式越接近,序列化的开销就越小
- DBMS 可以依赖现有的库(Protobuffer、Thrift、FlatBuffers)来实现自己的格式
#### Text Encoding
- 将所有 binary values(来自存储层的) 转换成 strings
- 比如使用 `atoi`, 123456 -> “123456”
- 不需要担心 endianness
### 3.2.4 String Handling
- **方式一:Null Termination**
- **方式二:Length-Prefixes**
- **方式三:Fixed Width**
- 填充每个 string 到该列的 max size
- 适合小 string
## 3.3 Apache Arrow
- Table 在内存中的标准列存格式
- 类似 Parquet / ORC,但是数据在内存中
- 最初的 Java 实现:[Apace Drill](https://drill.apache.org/)
- 允许系统间交互数据,而不需要(反)序列化成私有格式
- 将内存中的列存格式直接发送给 Client
- Arrow 项目包含了围绕这个格式的其他组件
- Write Protocols([ADBC](https://arrow.apache.org/blog/2023/01/05/introducing-arrow-adbc/),[Arrow Flight](https://arrow.apache.org/blog/2019/10/13/introducing-arrow-flight/))
- 执行引擎 Datafusion
---------
# 4. Kernel / User Bypass Methods
- DBMS 的 网络协议实现不是 slowdown 的唯一原因
- OS 的 TCP / IP stack is slow
- 昂贵的 context switch / interrupts
- Data copying
- 内核中的许多 latches
## 4.1 Kernel Bypass Methods
- 允许系统直接从 NIC 获取数据到 DBMS address space
- 不需要 data copying
- 没有 OS TCP/IP stack
- 不同的实现方式:
1. **Data Plane Developemnt Kit**
2. **Remote Direct Memory Access**
3. **io_uring**
### 4.1.1 DPDK
- 一组 libraries,可以让程序直接访问 NIC。将 NIC 视为 bare metal device。
- 需要 DBMS 来额外的开发去管理 network stack(layers 3+4)、memory 和 buffers
- TCP / IP in usercode(如 [F-Stack](http://www.f-stack.org/))
- 没有 data copying
- 没有系统调用
- Example
- [ScyllaDB's Seastar](https://seastar.io/)
- [Yellowbrick's ybRPC](https://yellowbrick.com/resources/executive-overviews/engineered-for-extreme-efficiency/)
### 4.1.2 RDMA
- 直接读写 remote host 的内存,不需要通过 OS
- client 需要知道目标数据的正确地址
- server 无法感知内存被远程访问了(no callbacks)
- Example
- [Oracle RAC](https://en.wikipedia.org/wiki/Oracle_RAC)
- [Microsoft FaRM](https://www.microsoft.com/en-us/research/publication/farm-fast-remote-memory/)(OLTP 系统)
- 同样需要特殊的硬件
### 4.1.3 io_uring
- Linux 的系统调用接口,用于 **zero-copy** **异步 IO** 操作
- 最初添加于 [2019](https://lwn.net/Articles/810414/) ,用于访问 storage devices
- [2022](https://github.com/axboe/liburing/wiki/io_uring-and-networking-in-2023)扩展支持 network devices
- Windows 上的类似实现:[ICOP](https://learn.microsoft.com/en-us/windows/win32/fileio/i-o-completion-ports)
- OS 暴露两个 circular buffers(queues)来存储 submission 和 completion I/O 请求
- DBMS 向 kernel 提交请求,读写到 DBMS 提供的 buffers(避免拷贝)
- 当 OS 完成请求,将事件放到 completion queue,然后调用 callback
- Example
- [A journey to io_uring, AIO and modern storage devices](https://clickhouse.com/blog/a-journey-to-io_uring-aio-and-modern-storage-devices) Clickhouse
- [Introduce io_uring support to ClickHouse](https://github.com/ClickHouse/ClickHouse/issues/10787) Clickhouse
- [Importing 300k rows/sec with io_uring](https://questdb.io/blog/2022/09/12/importing-300k-rows-with-io-uring/) QuestDB
- [A Programmer-Friendly I/O Abstraction Over io_uring and kqueue](https://tigerbeetle.com/blog/a-friendly-abstraction-over-iouring-and-kqueue/)
- [Mainlining Databases: Supporting Fast Transactional Workloads on Universal Columnar Data File Formats](https://www.vldb.org/pvldb/vol14/p534-li.pdf)
## 4.2 User Bypass Methods
- 通过 eBPF 当 packets 到达后在 OS kernel 内执行逻辑
- eBPF 由 DSL 编写,然后编译成 bytecode、verified、运行时 JIT-ed
- programming mode 受限(比如 no malloc,限制可以执行的指令数量)
- 只适合于 DBMS 操作 IO 的部分,不能处理数据太久
- [Tastes Great! Less Filling! High Performance and Accurate Training Data Collection for Self-Driving Database Management Systems](https://dl.acm.org/doi/10.1145/3514221.3517845)
-------------
# Parting Thoughts
- DBMS的网络协议是一个经常被忽视的性能瓶颈。
- Kernel bypass 能很大提升性能,但需要 more bookkeeping
- 可能对于 **DBMS 内部通信**更有用
- User bypass 是 DMBSs 中 ephemeral I/Os 的一个有趣方向。