# 1. Background
## 1.1 Query Optimization
- 给定一个 query,找出 cost 最低的**正确的**执行计划
- DBMS 中最难实现好的部分(已被证明是 NP-Complete)
- 没有一个 optimizer 能真正产生最优的 plan
- 使用 estimation 技术来猜猜真实的 plan cost
- 使用 heuristics 来限制 search space
## 1.2 Architecture Overview
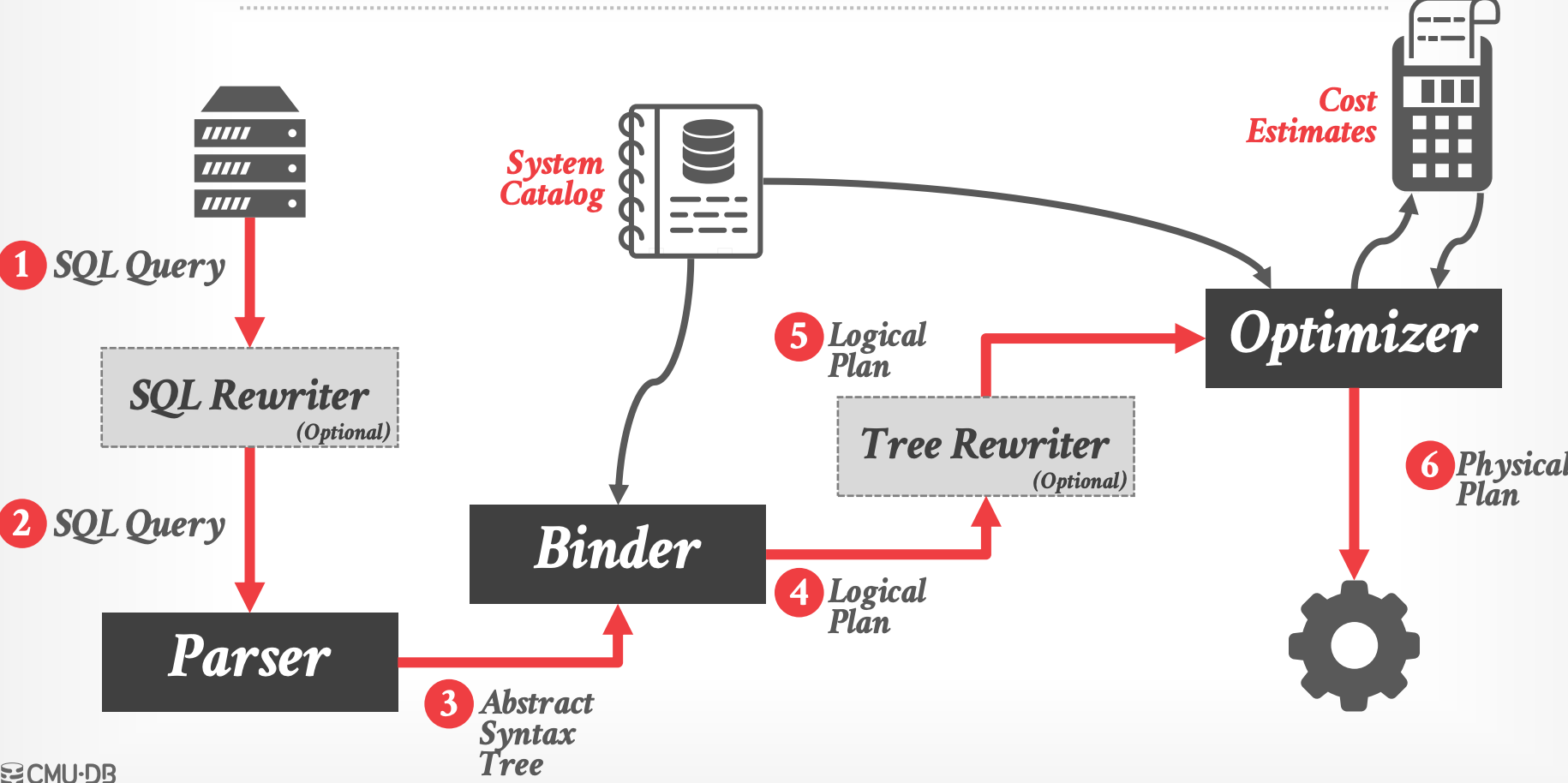
- **Logical vs. Physical Plans**
- optimizer 生成从 **逻辑关系表达式** 到 **优化的等价的物理关系表达式** 之间的映射。
- physical operator 定义了特定的执行策略
- 取决于数据的物理格式(sorting,compression)
- logical 到 physical 之间不总是一一对应的 (比如 join + order-by 对应 sort-merge-join)
- 两个关系代数表达式是等价的,如果它们的每个合法的 database 实例都生成 the same **set** of tuples。
> relation model is unordered
## 1.3 Observation
- OLAP 查询的 query planning 比较简单,因为它们是 sargable(Search Argument Able)
- 它通常使用简单的启发式方法选择最佳索引
- Joins 几乎都是基于 foreign key,且基数很小
## 1.4 Cost Estimation
- 在 database 当前 state 下,估算执行一个 plan 的 cost
- 与 DBMS 其他工作的交互
- 中间结果的大小
- 算法、access methods 的选择
- 资源利用(CPU、IO、network)
- Data properties(skew、order、plancement)
------------
# 2. Design Decisions
## 2.1 Optimization Granularity
- **Choice #1: Single Query**
- search space 更小
- DBMS 通常不会跨 queries 重用结果
- 考虑到资源竞争,cost model 必须考虑当前在运行什么
- **Choice #2: Multiple Queries**
- 如果有很多相似的查询,则更高效
- serach space 更大
- 可以共享 data / intermediate result
## 2.2 Optimization Timing(优化时机)
- **Choice #1: Static Optimization**
- 执行开始**前**选择最佳的 plan
- plan 的质量依赖 cost model 的准确性
- 可以基于 prepared statements 均摊开小
- **Choice #2: Dynamic Optimization**
- 在查询执行时即时选择 operator 的 plan
- 多次执行会重新优化
- 很难实现和调试(non-deterministic)
- 在 cloud systems / data lake 中更常见(缺少统计信息)
- **Choice #3: Adaptive Optimization**
- 使用静态算法 compile(static optimization)
- If the estimate errors > threshold, change or re-optimize.
## 2.3 Prepared Statements
- 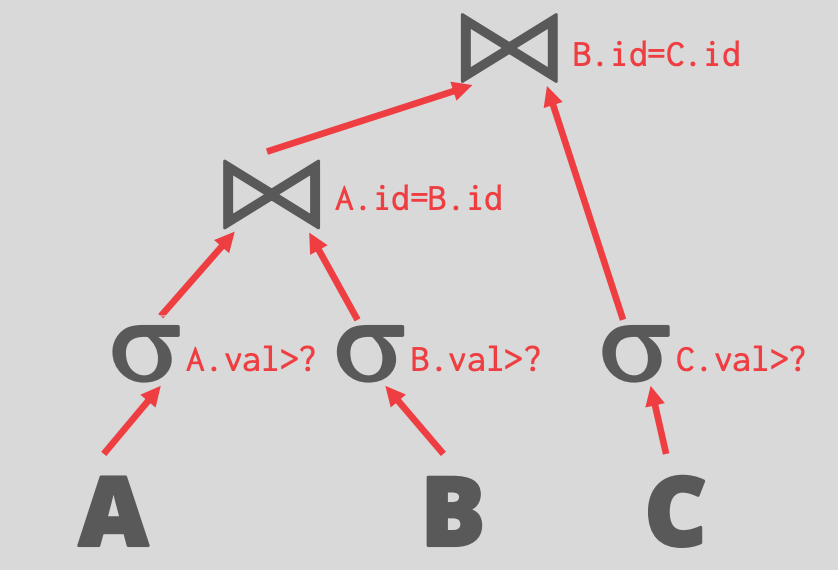
- 问题:不同的参数 join order 可能不一样
- **Choice #1: Reuse Last Plan**
- 使用上次调用生成的 plan
- **Choice #2: Re-Optimize**
- 每次查询调用时都重新运行 optimizer
- 重用已有的 plan 作为起始点很棘手(理想情况下 aware of last plan)
- **Choice #3: Multiple Plans**
- 为参数不同的 values 生成不同的 plans(比如 buckets)
- **Choice #4: Average Plan**
- 为参数挑选一个平均值,然后使用平均值来生成所有 invocations 的 plan
## 2.4 Plan Stabilty
- 问题:相同查询生成的 plan 不一样,造成性能的波动起伏
- **Choice #1: Hints**
- 允许 DBA 向 optimizer 提供 hints(plan 长成什么样子)
- PostgreSQL hint 示例:
```SQL
/*+
NestLoop(t1 t2)
MergeJoin(t1 t2 t3)
Leading(t1 t2 t3)
*/
SELECT * FROM table1 As t1
JOIN table2 As t2 ON (t1.key = t2.key)
JOIN table3 As t3 ON (t2.key = t3.key);
```
- **Choice #2: Fixed Optimizer Versions**
- 新版本的 DBMS 可能会为某个查询生成 bad plan,可以设定该查询使用旧版本的 optimizer
- 设定 optimizer 的版本号,一个一个地将查询迁移到新的 optimizer
- **Choice #3: Backwards-Compatible Plans**
- 保存旧版本生成的 query plan,将它提供给新版本的 DBMS
- SQL Server 可以做到
## 2.5 Search Termination
- 问题:何时停止 searching
- **Approach #1: Wall-clock Time**
- optimizer 运行一段时间后就停止
- **Approach #2: Cost Threshold**
- 当 optimizer 找到一个 cost 低于某个阈值的 plan 时停止
- **Approach #3: Exhaustion**
- 枚举完所有 target plan 后停止
-----------
# 3. Optimization Search Strategies
## 3.1 Heuristics
- 最简单的形式,基于规则
- [Query Processing In A Relational Database Management System](https://ieeexplore.ieee.org/document/718156)
- 定义 static rules,将 logical operators 转换成 physical plan
- 尽可能早地执行 most restricitive selection
- 在 joins 前执行所有的 selections
- Predicate / Limit / Projection pushdowns
- 基于 simple rules 或者 cardinality estimates 进行 join ordering
- **Example:**
- INGRES(直到 1980s)
- Oracle(直到 1990 年代中期)
- MongoDB
- 大多数新的 DBMSs
### Ingres Optimizer
- 没有 join
1. Decompose into single-value queries
2. 将各个 query 的执行结果按依赖顺序依次替换 values
### Review
- **Advantages:**
- 容易实现和调试
- 工作地相当不错,并且对于简单的查询很快
- **Disadvantages:**
- 依赖 magic constants 来预测 plan 决策的效果
- 当 operators 之间有复杂的内部依赖时,几乎不可能产生好的 plans
- transmations 之间有依赖(比如如果这个 transformation 应用了,才可以尝试另外一个 transformation)
## 3.2 Heuristics + Cost-based Join Order Search
- [Access path selection in a relational database management system](https://dl.acm.org/doi/10.1145/582095.582099)
- 先使用 static rules 进行初始优化, 然后使用 DP 来决定最佳的 join order
- 第一个 cost-based query optimizer
- Bottom-up planning(forward chaining),使用分而治之的搜索方法
- **Examples**:
- System R
- 早期的 IBM DB2
- 大多数开源的 DBMSs
### System R Optimizer
- 将 query 拆分成 blocks,然后为每个 blocks 生成 logical operators
- 对于每一个 logical operator,生成一组实现它的 physcial operators
- 所有 join 算法 和 access paths 的组合
- 然后迭代地构建一个 **left-deep join tree** 来最小化执行 plan 所估计的工作量。
1. Step #1: Choose the best access paths to each table(sequential scan、index scan等)
2. Step #2: Enumerate all possible join orderings for tables
3. Step #3: Determine the join ordering with the lowest cost(dynamic programming)
- 
- 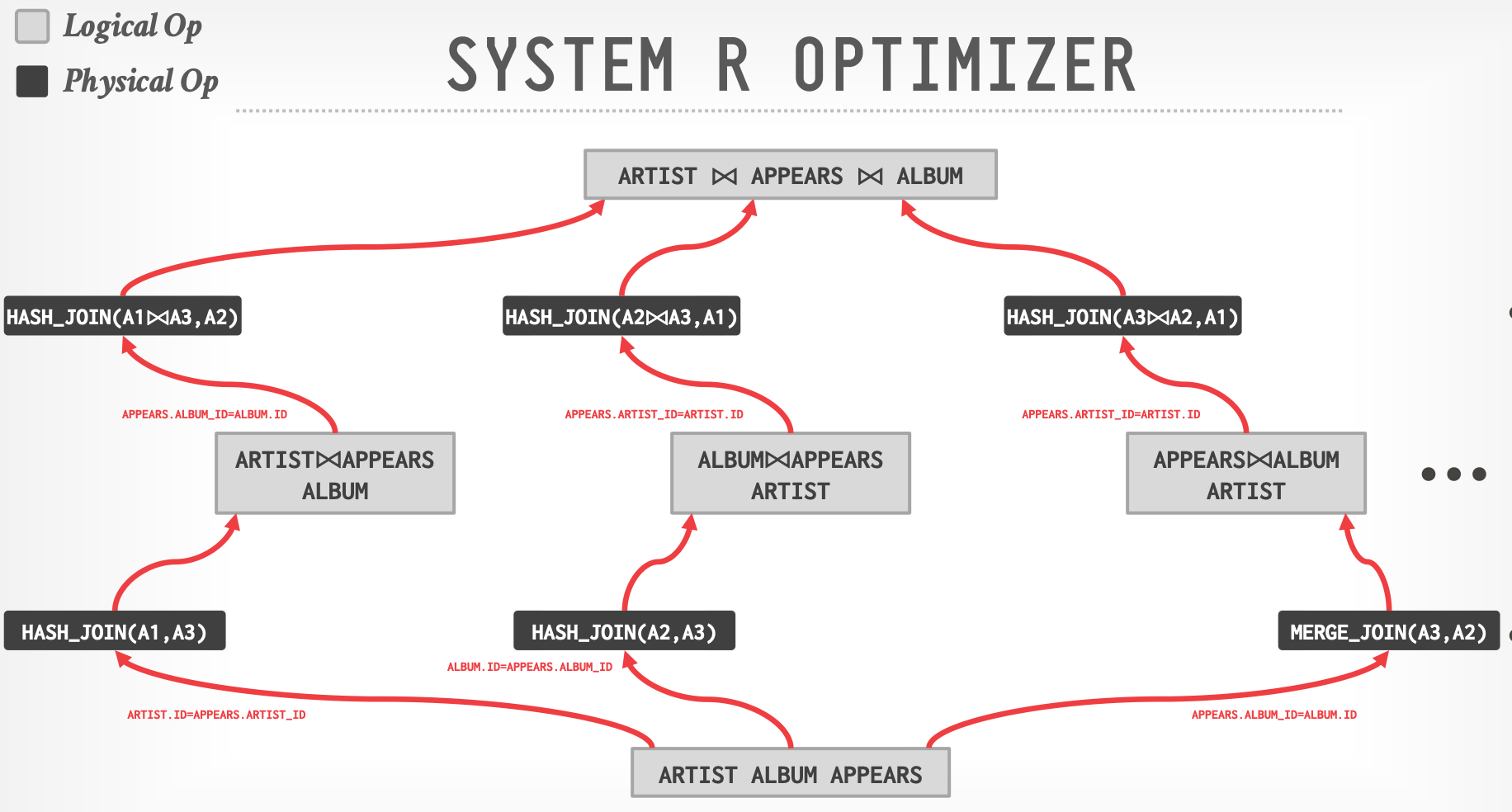
- Bottom-up
- 挑选 cost 最小的路径
- 
- Hack:给无序的 operator 一个很高的 cost 来避免选择它
### Top-Down VS. Bottom-Up
- **Top-down Optimization**
- 从查询想要的结果开始,然后向下处理 tree 以找到实现该目标的最佳 plan。
- Examples:Volcano,Cascades
- **Bottom-up Optimization**
- 从零开始,然后制定 plan 以达到您想要的结果。
- Examples: System R, Starburst
### Postgres Optimizer
- 强制实施了严格的查询优化 workflow
- 第一阶段:基于 heurtistics 执行初始的 rewriting
- 然后执行 cost-based search 来查找最优的 join ordering
- Everything else is treated as an "add-on"
- 然后递归地处理 sub- queries
- 修改和扩展困难,transformation rules 需要遵守正确的顺序。
### Review
- **Advantages:**
- 通常不需要穷举就能找到一个合理的 plan
- **Disadvantages:**
- 跟 heuristic-only 方式存在相同的问题
- left-deep join 不总是最优的
- cost model 必须考虑 data 的 physical properties(比如 sort order)
## 3.3 Randomized Algorithms
- 在查询的所有可能(有效)计划的 solution space 上执行随机游走。
- 持续搜索,直到到达 cost 阈值,或者运行了一定的时限。
- **Examples:** Postgres genetic alogrithm
### Simulated Annealing
- [Query optimization by simulated annealing](https://dl.acm.org/doi/10.1145/38714.38722)
- 以 heuristic-only 方式生成的 query plan 作为**起始**
- 计算 operators 的随机排列(例如:交互两个 tables 的 join order)
- 用于接收减少 cost 的变更
- 只接受在某种概率下增加 cost 的变更
- 拒绝违法正确性的变更(例如 sort ordering)
### Postgres Genetic Optimizer
- [Genetic Query Optimization (GEQO) in PostgreSQL](https://www.postgresql.org/docs/9.4/geqo-pg-intro.html)
- 更复杂的查询使用 genetic algorithm 来选择 join orderings
- 例如查询设计 13 个以上的 tables
- 每轮开始时,生成 query plan 的不同变种(variants)
- 选择具有最低成本的 plan ,并与其他 plan 进行排列组合。重复此过程。
- mutator函数只生成有效的plan
### Review
- **Advantages:**
- 随机在搜索空间中跳动可以让 optimizer 摆脱**局部最小值**
- 内存占用低(不需要保存历史)
- **Disadvantages:**
- 很难推测为什么 DBMS 挑选了这个 plan
- 需要做一些额外的工作来保证 plan 的 deterministic
- 仍然需要实现正确的 rules
## 3.4 Optimizer Generators
### Observation
- 使用 procedural language 来编写 transformation rules 很难且易错
- 没有简单的方法来验证规则的正确性,除非运行大量的 fuzz tests
- Generation of physical operators per logical operator is decoupled from deeper semantics about query
- 更好的方式是使用一个声明式的 DSL 来编写 transformation rules,然后在 planning 过程中由 optimizer 实施它们(编译和应用)。
### Optimizer Generators
- 一个 framework,可以允许 DBMS 实现者编写声明式的查询优化规则
- 将 data model 与 search strategy 分离
- Separate the transformation rules and logical operators from physical rules and physical operators.
- 实现可以独立于 optimizer 的 search strategy.
- **Examples**:Starbust、Exodus、Volcano、Cascades、OPT++,Calcite
- 使用一个 rule engine 允许 transformations 来修改 query plan operators。
- data 的 physical properties 内嵌到 operators 自己中
- **Choice #1: Stratified Search**
- planning 过程有多个 stages(heuristics 然后 cost-based search)
- **Choise #2: Unified Search**
- 一次性执行 query planning(RBO 和 CBO 一起执行)
## 3.4 Stratified Search
- 首先使用 transformation rules(DSL) 来 rewrite logical query plan
- transformation在应用前先由 engine 检测是否被允许
- 该步骤不考虑 cost
- 然后执行一次 cost-based search 将 logical plan 映射成 physical plan。
### Starburst Optimizer
- 使用了 declarative rules,实现了更好的 System R optimizer。
- [Grammar-like functional rules for representing query optimization alternatives](https://dl.acm.org/doi/10.1145/971701.50204)
- **Stage #1: Query Rewrite**
- Compute a SQL-block-level, relational calculus-like representation of queries.
- **Stage #2: Plan Optimization**
- 执行 dynamic programming phase
- Example:IBM DB2 的最新版本
### Review
- **Advantages:**
- 实践中工作地很好,并且性能也很快
- **Disadvantages:**
- 很难给 transformations 分配优先级
- 一些 transformations 很难在没有计算多个成本估算的情况下进行评估。
- 维护 rules 很痛苦
## 3.5 Unified Search
- 将 logical -> logical 和 logical -> physical 转换统一到一起
- 不需要再有单独的阶段,因此所有的都是 transformations
- 这种方式生成了许多 transformations,因此它大量使用 memoization 来减少重复工作。
### Volcano Optimizer
- [The Volcano Optimizer Generator: Extensibility and Efficient Search](https://15721.courses.cs.cmu.edu/spring2017/papers/14-optimizer1/graefe-icde1993.pdf)
- 通用的 cost-based query optimizer,基于关系代数的等价 rules
- 容易添加新的 operations 和 等价 rules
- planning过程中将 data 的 pyhsical properties 视作一等公民(first-class entities)
- **Top-down 方式**(backward chaning),使用 branch-and-bound search
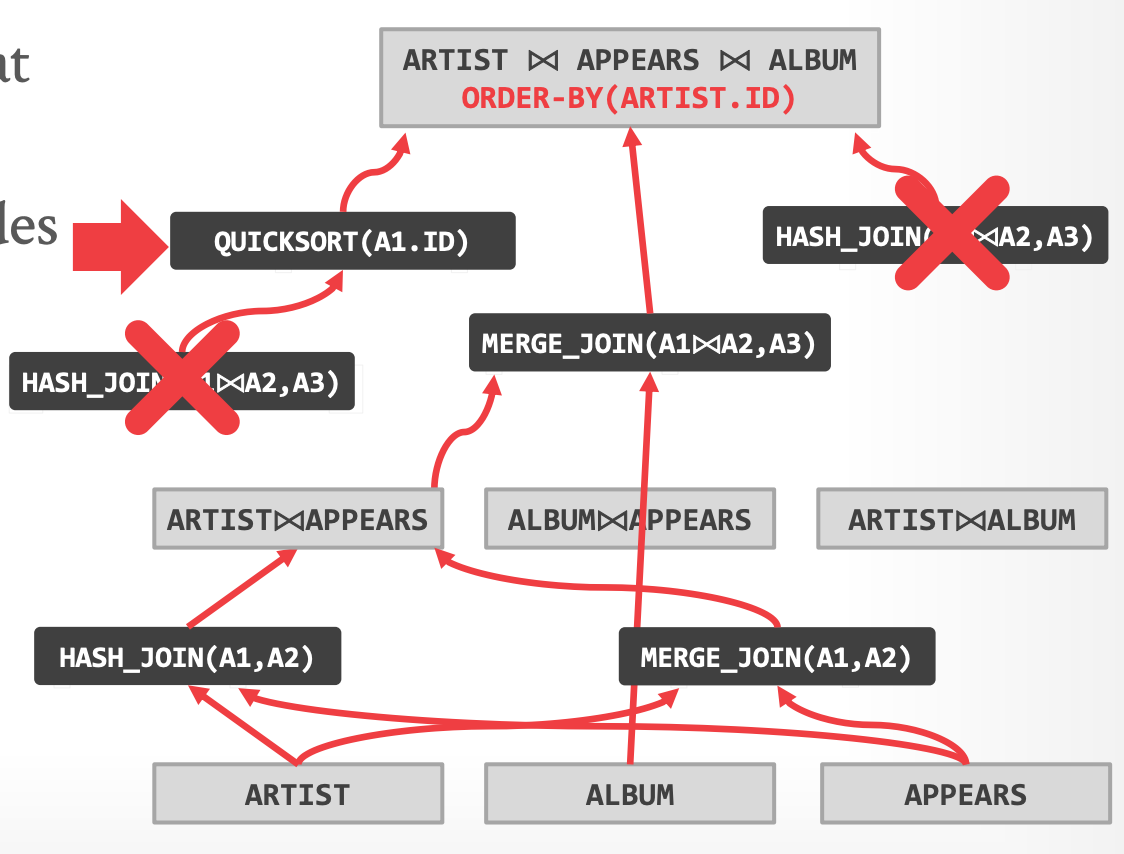
### Top-down Optimization
- 从我们期望的 logical plan 开始
- 调用规则来创建新的 nodes 、遍历 tree
- Logical -> Logical:如 JOIN(A,B) 到 JOIN(B,A)
- Logical -> Physical:如 JOIN(A,B) 到 HASH_JOIN(A, B)
- 可以创建 enforcer rules,来确保 input 拥有某些确定的属性
- 
### Review
- **Advantagses:**
- 使用了 declarative rules 来生成 transformations
- 使用高效的 search engine 提供了更好的扩展性
- 使用 memoization 来减少重复的 estimations
- **Disadvantages:**
- 在 optimization search 之前,所有等价类都完全展开以生成所有可能的 logical operators。
- 不容易修改 predicates
---------
# Parting Thoughts
- CMU-DB talks:[https://cmudb.io/youtube-optimizers](https://cmudb.io/youtube-optimizers)
- [The Cascades Framework for Query Optimization at Microsoft](https://www.youtube.com/watch?v=pQe1LQJiXN0)