# 1. Overview
- 定位:In-Process OLAP DBMS
- “The SQLite for Analytics"
- 类似一个 Library
- 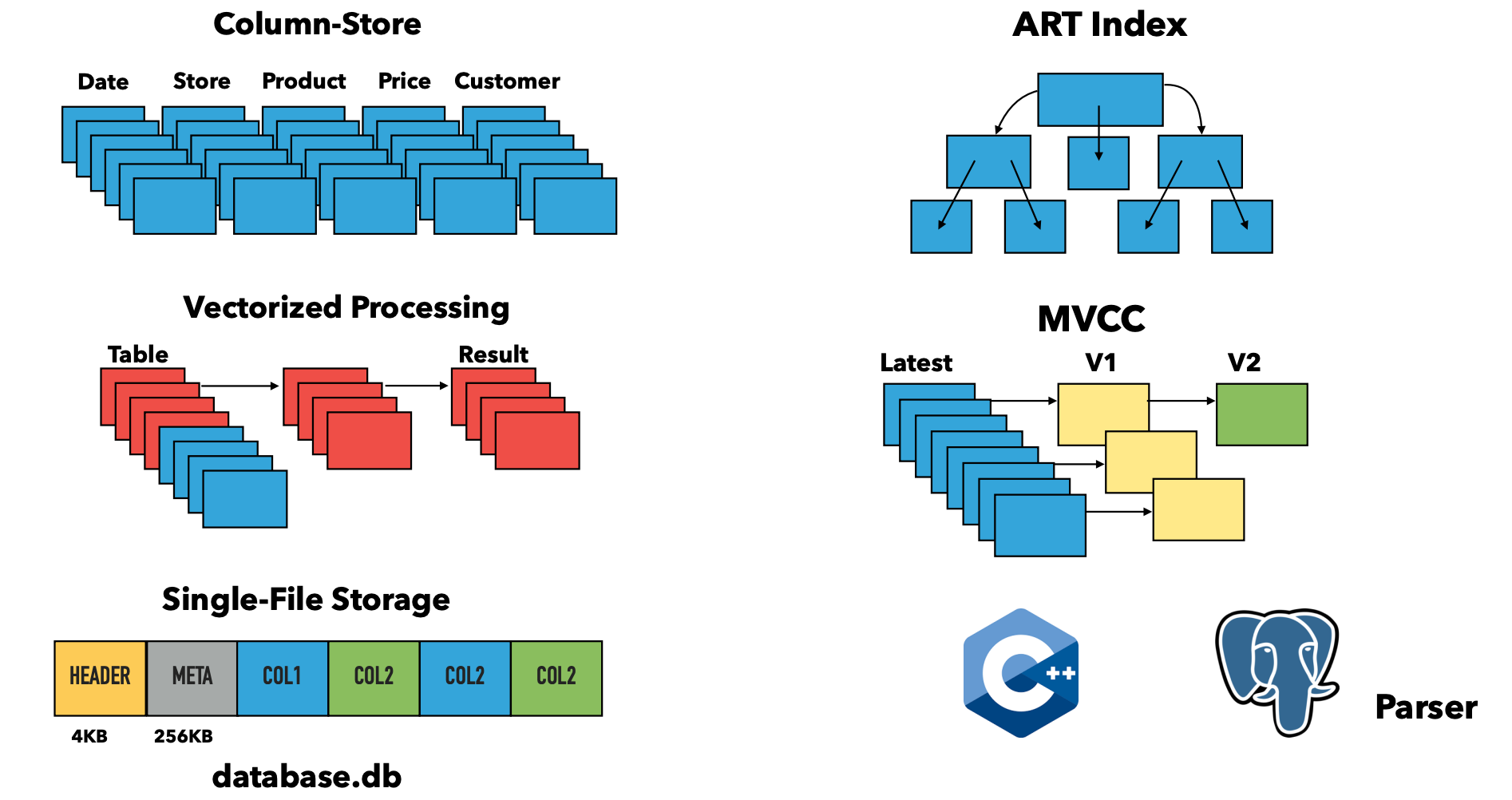
- **Single-File Storage**:类似 sqlite,database 的数据都在一个文件内
- **MVCC**:transaction management
---------
# 2. Vectors
- DuckDB 使用了 **vectorized push-based model**
- vectors 在 operators 间流动
- Vectors 是引擎的基本要素
- DuckDB 有一个定制的 **vector format**
- 类似 Arrow,但是更关注执行效率
- 与 Velox team 一起设计
## 2.1 Format
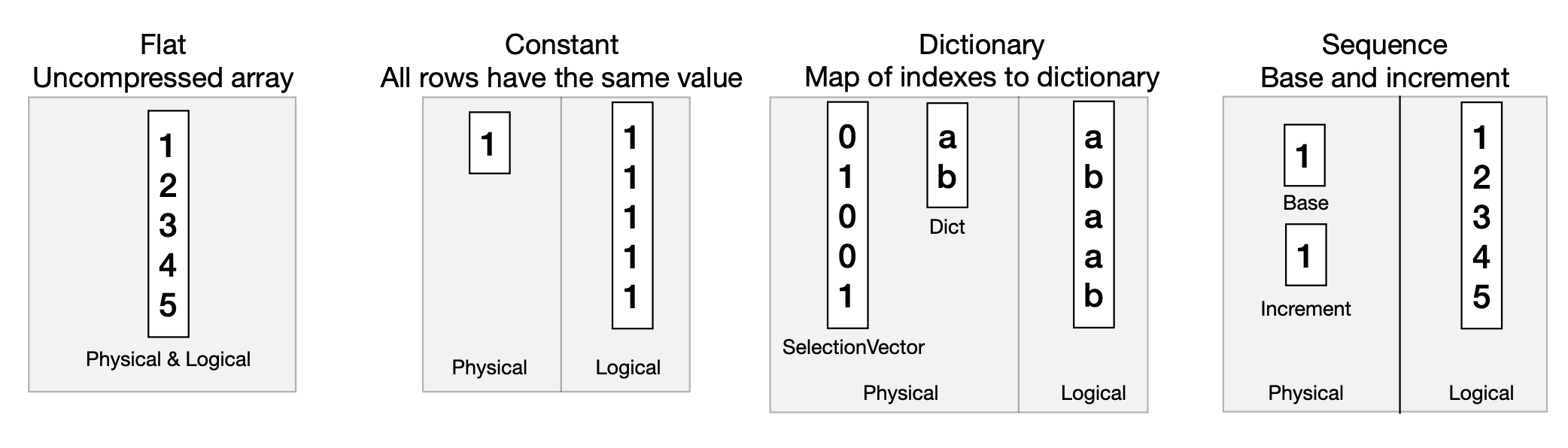
- Vector 保存单一类型的数据
- 对于 scalar types,vector 逻辑上等同于 arrays
- `VectorType` 决定了 physical representation
- 可以向 engine push 压缩后的数据
- 
## 2.2 Process
- 可以在压缩后的Vectors上**直接执行**、操作
- 问题:combinatorial explosion
- Giant code footprint(处理不同类型)
- **Flatten**:将 vector 转换成 Flat Vector(未压缩的)
- 需要 move/copy data
- **ToUnified*** :将 vector 转换成 **unified format**
- 
- Unified:不同类型 Vector 的格式都一样,可以统一处理
## 2.3 Strings
^59b3ab
- 
- 存储格式与 Umbra 一样
- 16 字节(无论是 short 还是 long string)
- Short string 是 inlined(小于 12 字节)
- Long string:prefix + pointer // 4 字节前缀,
- **Fast early-out in comparsion**
- 先比较前8个字节,如果不一样则整个字符串都不一样
- 计算 start_with
## 2.4 Nest Types
- Nest types 对于分析场景很重要
- Nest types are stored **recursively using vectors**
- 处理效率更高(相比存储为 blobs / strings))
- 两个主要的 nest types:
- **structs**
- **lists**
### Structs
- structs 存储它们的 child vectors 和 一个 validity mask
- 
- child vectors 的个数为 struct fields 的个数
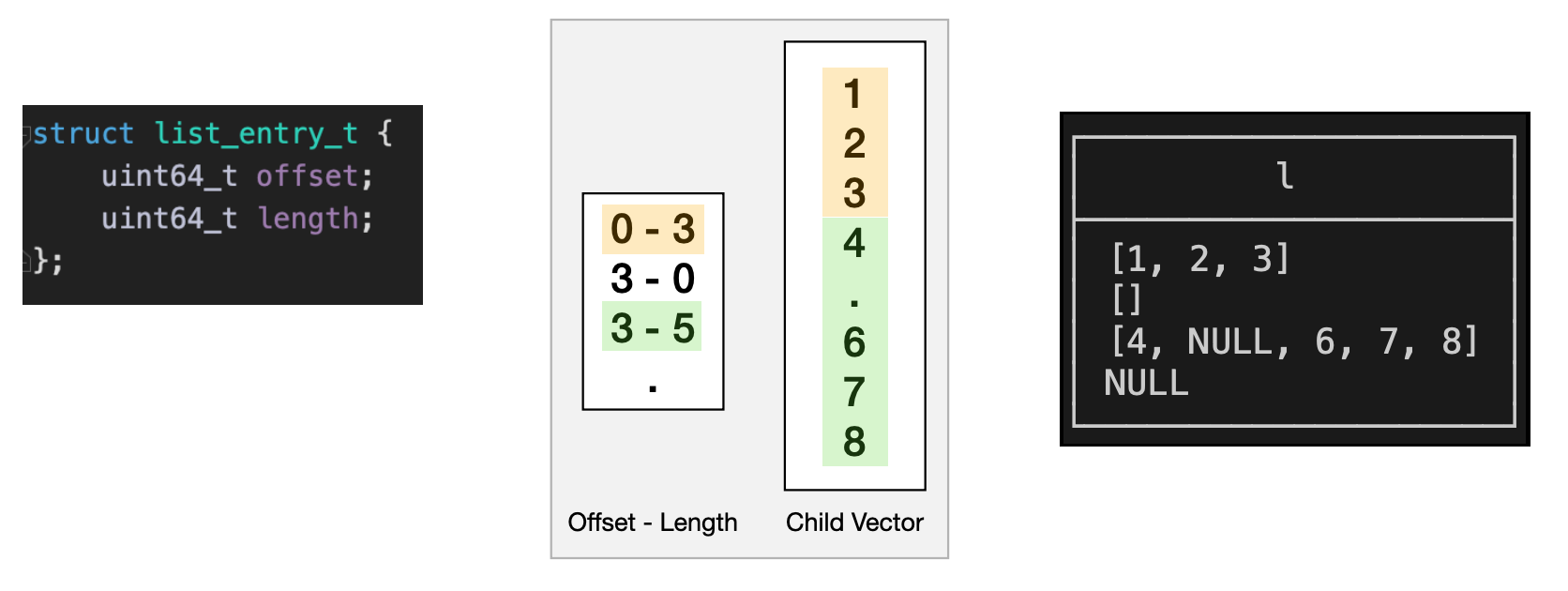
### Lists
- Lists 存储为 offset / lengths 和 一个 child vector 的组合
- child vector 的长度可能不一样
- 
-------
# 3. Query Execution
## 3.1 Pull-Based Model
- DuckDB 最初使用了 **pull-based model**
- “Vector Volcano”
- 每个 operator 实现了 `GetChunk`
- 查询从 root 调用 `GetChunk` 开始
- Nodes 递归调用 children 的 `GetChunk`
- Hash Join 示例:
```cpp
void HashJoin::GetChunk(DataChunk &result) {
if (!build_finished) {
// build the hash table
while(right_child->GetChunk(child_chunk)) {
BuildHashTable(child_chunk);
}
build_finished = true;
}
// probe the hash table left_child->GetChunk(child_chunk);
ProbeHashTable(child_chunk, result); }
```
### 3.1.1 Parallelism Model
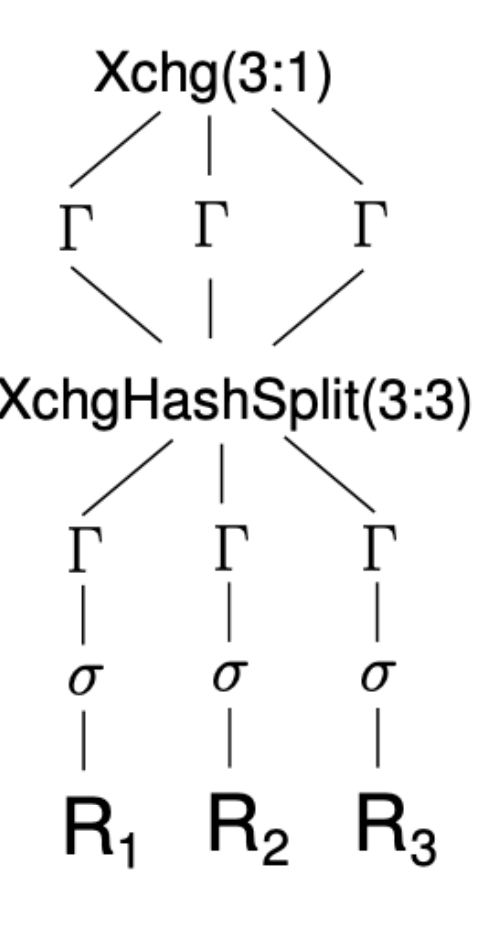
#### Exchange Model
- **Exchange** operator
- optimizer 将 plan 分成多个 partitions
- partitions 独立执行
- 
- operator 不需要感知 parallelism,非常适合将单线程系统扩展成并行
- **问题**
- Plan exposion
- Load imbalance issues
- Added materialization costs
#### Morsel driven paralism
- Individual operators are **parallelism-aware**
- Input data is distributed **adaptively**
- Parallelism 没有侵入到 plan 中
#### Pipelines
- 
## 3.2 Push-Based Model
- DuckDB 后续切换到了 **push-based model**
- 分布为 **sink**,**source** 和 **operator** 提供独立的接口
- source 和 sink 是 **parallelism aware** 的 // 有 global 和 local 两种 state,local 是线程本地的
```cpp
// Source
void GetData(
DataChunk &chunk,
GlobalSourceState &gstate,
LocalSourceState &lstate);
// Operator
OperatorResultType Execute(
DataChunk &input,
DataChunk &chunk,
OperatorState &state);
// Sink
void Sink(
GlobalSinkState &gstate,
LocalSinkState &lstate,
DataChunk &input);
void Combine(
GlobalSinkState &gstate,
LocalSinkState &lstate);
void Finalize(
GlobalSinkState &gstate);
```
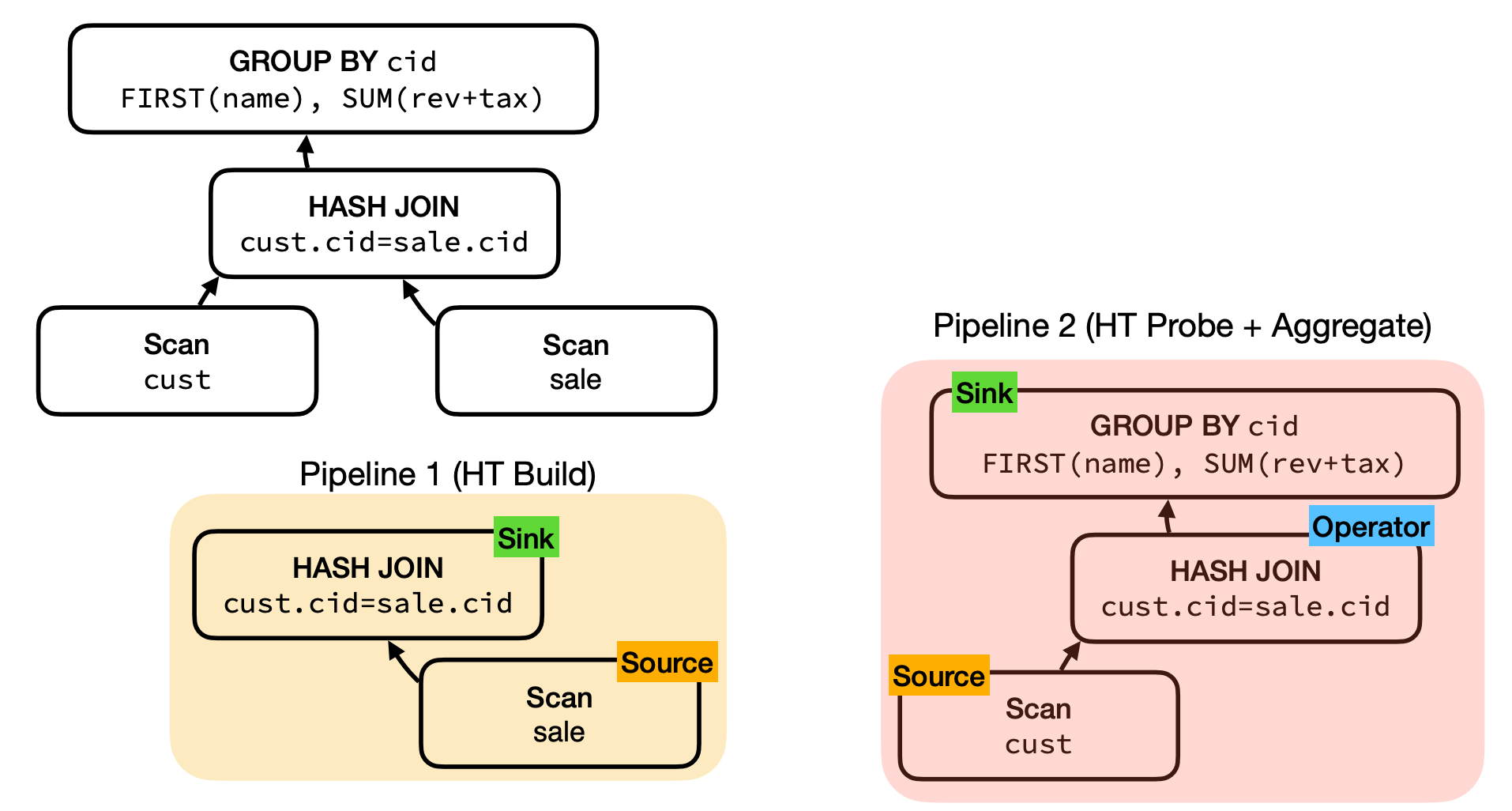
- Push-based Pipelines
- 
### Control flow
- Pull-based:control flow 存在于 operator **内部**
- 非常灵活
- 基于递归调用,call stack 保存了所有 state
```cpp
void Projection::GetChunk(DataChunk &result) {
// get the next chunk from the child
child->GetChunk(child_chunk);
if (child_chunk.size() == 0) {
return;
}
// execute expressions
executor.Execute(child_chunk, result);
}
// call stack
HashAggregate::GetChunk(DataChunk &result)
HashJoin::GetChunk(DataChunk &result)
Projection::GetChunk(DataChunk &result)
Table::GetChunk(DataChunk &result)
```
- Push-based:control flow 发生在 **a central location**
```cpp
void Projection::Execute(DataChunk &input, DataChunk &result) {
executor.Execute(input, result);
}
```
```cpp
class PipelineState {
public:
//! Intermediate chunks for the operators
vector<unique_ptr<DataChunk>> intermediate_chunks;
}
```
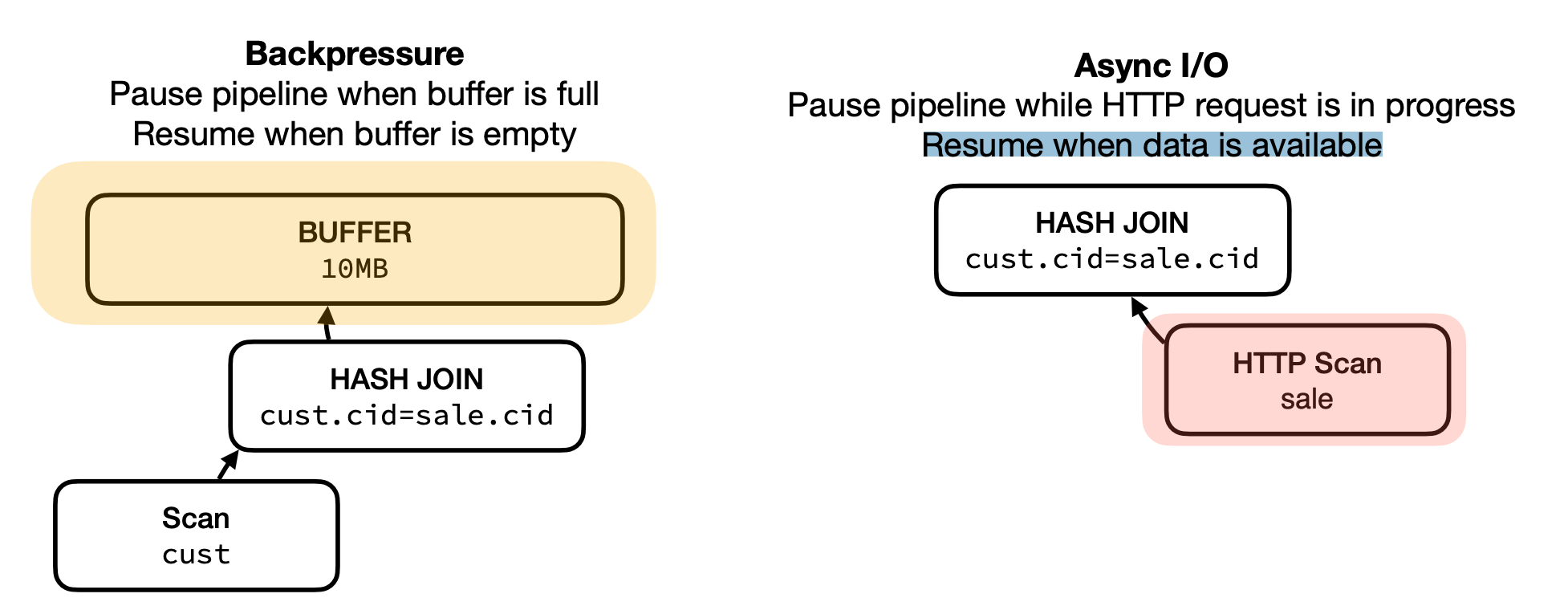
- Handling control flow in a central location **enables optimizations**
- 
- vector cache:案例:filter 后 rows 数量很少,可以 buffer 赞批
- scan sharing:如果有 back pressure 可能有问题
- Storing state in central location allow us to **pause execution**
- 
-----
# 4. Storage
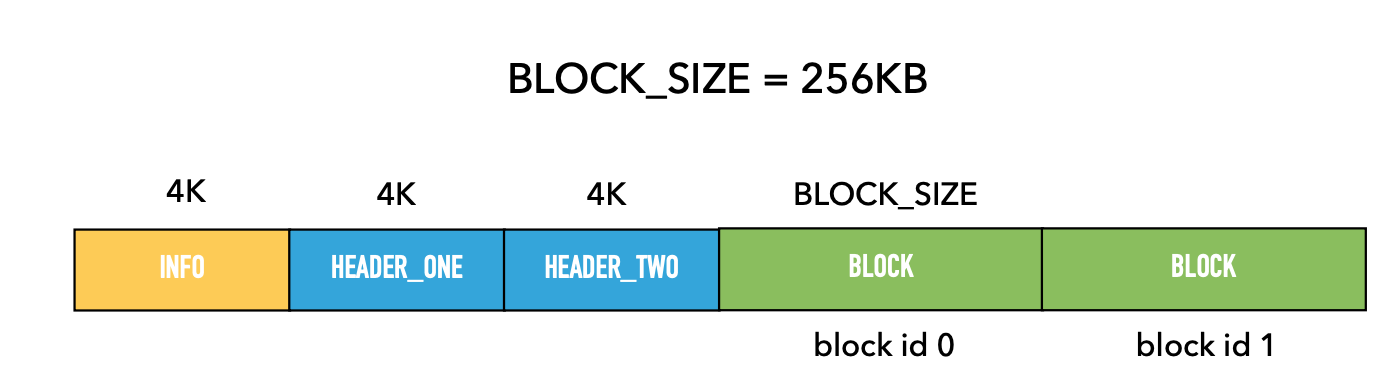
- DuckDB 使用了 **single-file block-based** storage format
- WAL 存储为一个独立的文件
- 使用 **headers** 来实现 ACID
- 文件头部有两个 headers 来回切换
- 
## 4.1 Table Storage
- Tables 切分为 row groups
- 每个 row group 有约 120k rows
- Row groups 是并行和 checkpoint 的 单元
- 支持压缩
- 加速 IO
- 加速执行(vectors)
- 数据更小、查询更快
- **General-purpose**、heavy-weight compression
- gzip,zstd,snappy,lz4
- Finds patterns in **bits**
- 节省空间,但高压缩率会减慢执行,没有 compressed execution
- **Special purpose**、lightweight compression
- RLE, bitpacking, dictionary, FOR, delta
- Finds specific patterns in **data**
- 快;劣势:可能无法找到特定的 patterns
- Compression works per-column per row-group
- 两个阶段:
- Analyze:找出最快的压缩方法
- Compress
---------
# 5. Lighting Round
## 5.1 Buffer Manager
- 定制的 **lock-free** buffer manager,inspired by lean-store
- 粒度:256KB blocks
- 典型的 buffer manager 功能:
- 设置内存限制
- pin blocks
- unpin blocks
## 5.2 Out-Of-Core
- 支持 **larger-than-memory execution**
- streaming engine
- 特殊的 join,sort & window 算法
- 目标:**Gracefully degrade** performance
- 避免 performance cliff
## 5.3 Transactions
- 多版本只存在内存中,不会写入到存储中
- 基于 Hyper MVCC model
- optimized for vectorized prcessing
- [ ] [Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems](https://dl.acm.org/doi/10.1145/2723372.2749436)
- 支持 snapshot isolation
- Optimistic concurrency control
- 更改相关的 rows -> transaction abort
## 5.4 External Formats
- 支持对许多格式的直接查询
- Parquet,CSV,JSON,Arrow,Pandas,SQLite,Postgres
- **pluggable catalog**
- 支持 attacing multiple databases
```shell
$ duckdb
D ATTACH 'sqlite.db' (TYPE sqlite);
D SELECT database_name, path, type FROM duckdb_databases(); ┌───────────────┬───────────┬─────────┐
│ database_name │ path │ type │
│ varchar │ varchar. │ varchar │
├───────────────┼───────────┼─────────┤
│ sqlite │ sqlite.db │ sqlite │
│ memory │ NULL │ duckdb │
└───────────────┴───────────┴─────────┘
D USE sqlite;
D CREATE TABLE lineitem AS FROM 'lineitem.parquet';
D CREATE VIEW lineitem_subset AS
SELECT l_orderkey, l_partkey, l_suppkey, l_comment FROM lineitem;
$ sqlite3 sqlite.db
sqlite> SELECT * FROM lineitem_subset LIMIT 3; ┌────────────┬───────────┬───────────┬─────────────────────────────────────┐
│ l_orderkey │ l_partkey │ l_suppkey │ l_comment │ ├────────────┼───────────┼───────────┼─────────────────────────────────────┤
│ 1 │ 155190 │ 7706. │ to beans x-ray carefull │
│ 1 │ 67310 │ 7311 │ according to the final foxes. qui │
│ 1 │ 63700 │ 3701 │ ourts cajole above the furiou. │ └────────────┴───────────┴───────────┴─────────────────────────────────────┘
```
- **pluggable file system** + HTTP / Object Store reads
```sh
$ duckdb
D LOAD httpfs;
D FROM 'https://github.com/duckdb/duckdbdata/releases/download/v1.0/yellowcab.parquet';
```
## 5.5 Extensions
- 支持扩展
- 通过 **INSTALL** 和 **LOAD** 命令
- 可以加载为一个 shared library
- 许多 core features 也实现为了扩展
- icu
- parquet
- geo
- WASM build