# 1. Background
- Data Systems At Meta
- Scirbe (2008)
- Cassandra (2008) -> DataSta, FaunaDB,Scylla
- Hive (2010)
- RocksDB (2012)
- Scuba (2013). // 未开源
- PrestoDB (2013) -> Ahana, Trino / Starburst
- WebScaleSQL (2014)
- Gorilla / Beringei (2015)
- LogDevice (2017)
- Velox (2021)
-------
# 2. Velox
- [[meta-velox-paper]]
- 可扩展的 C++ library,支持高性能的单节点查询执行
- 没有 SQL parser
- 没有 meta-data catalog
- 没有 cost-based optimizer
- 输入:**physical plan**(DAG of operator)
- 输出到指定位置
## 2.1 Overview
- Push-based Vectorized Query Processing
- Precompiled Primtives + Codegen Expressions(C++,实验特性)
- Arrow Compatible (extended)
- Adaptive Query Optimization
- Sort-Merge + Hash Joins
## 2.2 Components
- Type System
- Vector Internal Representation
- Expression Engine
- Function API
- Operator Engine
- Storage Connectors / Adaptors
- 没有自己的存储格式,通过 connectors / adaptors 来获取数据
- S3, HDFS
- Parquet, ORC/DWAR, Alpha
- Resource Manager
- [ ] [Video: Velox: An Open-Source Unified Execution Engine](https://www.youtube.com/watch?v=HgNP3d93Jb4)
## 2.3 Vector
- 使用 in-memory vector 在 operators 之间传递数据。
- 扩展了 Arrow 列存布局,支持更多的 encoding / compresson 机制
- Optimizations
- Lazy Vector Materialization
- German-style String Storage [[22-duckdb#^59b3ab|DuckDB Strings]]
- Out-of-order Writes / Population
## 2.4 Expression Engine
- [ ] Velox 将 expression trees 转换成 **flattened** intermediate representation,再去执行
- 类似函数指针数组,指向 precompiled(untemplated) primitives
- [Experimental branch](https://github.com/facebookincubator/velox/tree/main/velox/experimental/codegen)将 IR 转换成 C++ 代码,然后通过 exec 编译成机器码。
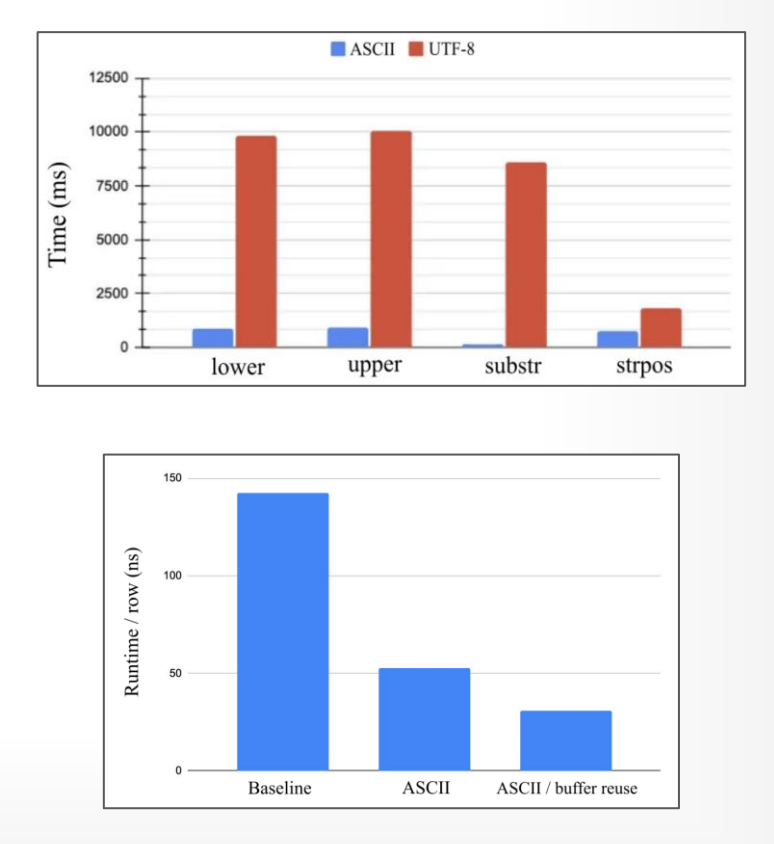
## 2.5 Query Adaptivity
- **Predicate Reordering**
- [ ] Column Prefetching
- Elide ASCII Encoidng Checks
- Bonus: Reuse buffers for output! // substr
- 
## 2.6 Prestissimo
- 将 PrestoDB 的 java runtime engine 替换为 Velox
- 类似 [[20-databricks#^d56cfa | Photon]]
- 使用 Velox API 重写实现 SQL functions 和 operators(Velox 不具备的),来兼容 PrestoDB。
- Trino 的选择:提升方向为 Query optimizer
- [Will Trino be making a vectorized C++ version of Trino workers?](https://www.youtube.com/watch?v=vuY7fGMLAfI&t=1162s)
-----
# 3. Additional Projects
## 3.1 Substrait (2021)
- 表示 realational algebra query plans 的开源标准
- 类似 Arrow,但是目标是 query plans
- **设计目标**:系统之间可以共享 physical query plans,不需要转换成 native API / DSL。
## 3.2 DataFusion (2019)
- Extensible vectorized execution library for Apache Arrow data
- 相比 Velox,支持了更多的 front-end 功能来构建一个完整的 DBMS
- SQL 和 DataFrame APIs
- Query Optimizer
- Examples:
- InfluxDB
- CeresDB
- CnosDB
- Seafowl
## 3.3 Polars (2020)
- 与 DataFusion 非常相似
- 更倾向于 DataFrame
--------
# Parting Thoughts
- 与其从头开始实现一个 OLAP DBMS,不如复用类似 Velox 这样的产品来扩展它。
- 这意味着 DBMS 之间的差异因素将是 用户界面/用户体验方面 和 查询优化。