- **Redshift pillars**
1. Security and Availabilty
- Access control
- Cross-AZ cluster recovery
2. Performance
3. Storage and Compute Elasticity
4. Autonomics
5. Serverless
5. Integrations
- 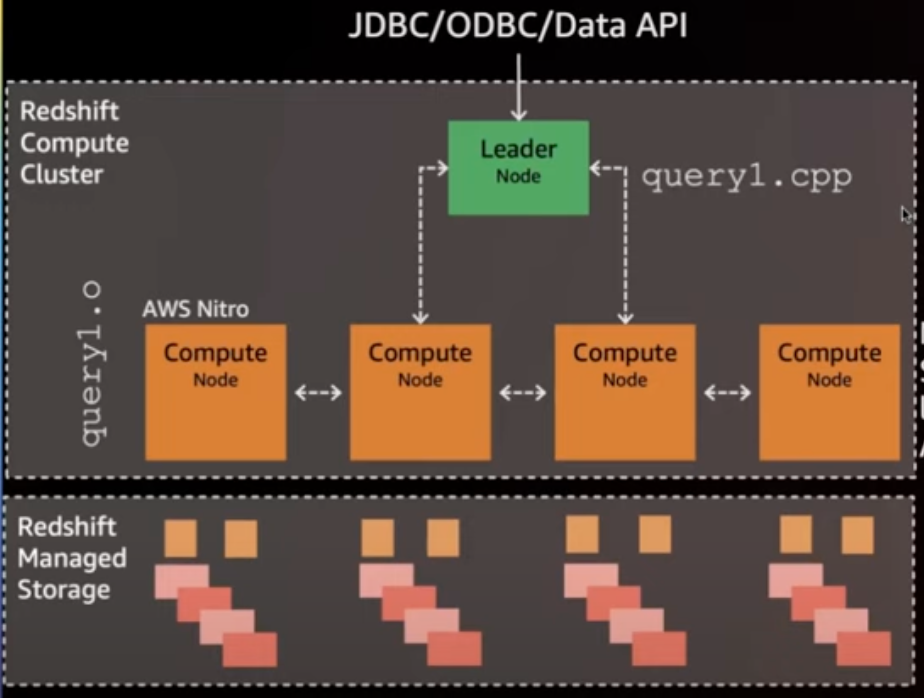
- 两层架构:计算 + 存储
- leader node:接收用户请求、管理 catalog
- 生成C++代码,编译发完 compute node
- Min/max pruning
- SIMD scans from load-attached SSDs
- push-based
- collocated join
- Code generation, Prefetching, Vectorization
- **Compilation-as-a-Service**
- 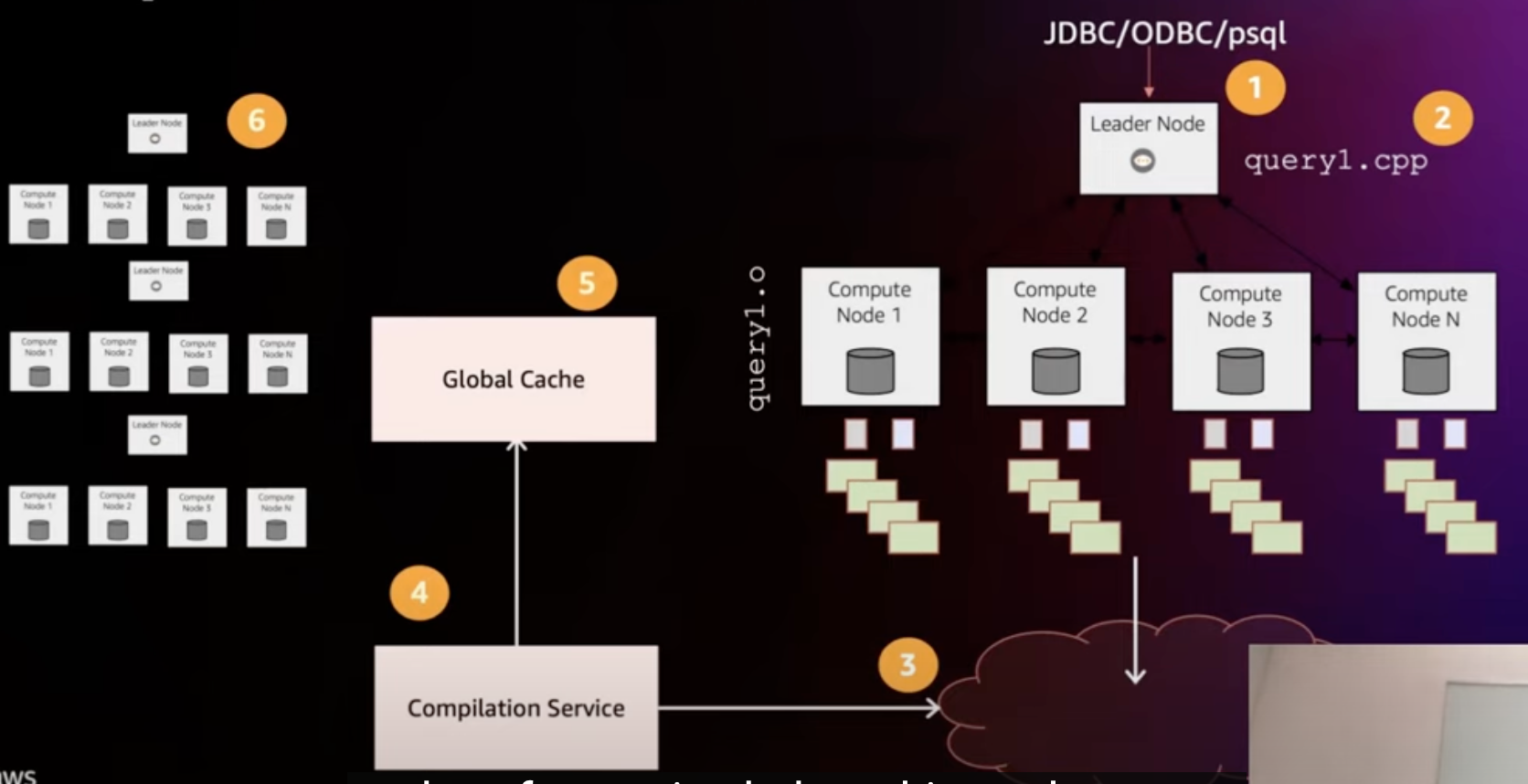
- global cache(用户查询重复读高,命中率 99.5%,跨用户,跨环境)
- 没见过的 query fragment 放到 S3 上,然后编译放到 cache 中
- **Continuous telemetry and benchmarking**
- short query acceleration
- query result caching
- query rewrites for selective joins
- cache line prefetching for HashJoins and HashAggregations
- late materialization
- **Redshift String Processing**
- BYTEDICT encoding 适合 low-cardinality string columns
- **Redshift Managed Storage**
- Large high speed cache
- High-bandwidth networking
- Disaggregated compute and storage
- **Compute Elasticity**
- Re-assign buckets to new nodes, then resume operations
- Concurrency scaling
- 超载后,将队列里的查询路由到新增的节点
- **Data sharing**
- 通过 managed storage,不同的 cluster 间共享数据
- 比如某个 cluster 负责 produce,另外一个 cluster 消费数据
- tranactionally consistent
- 可以跨 AZ region
- **Auto Manitenance Operations**
- Automatic Table Optimization
- Self-tuning
- Optimize the physical design without DBS intervention
- Apply sort and distribution keys
- Auto-Analyze
- Start with the tables that are more outdated and used more
- Auto-Vacuum {Delete, Full}
- Priority-based and incremental
- 从最经常使用的 tables 开始
- Auto-Materialized View Refresh
- Refresh the MVs that are more likely to be used next
- **Redshit Advisor: Dist-Key Recommendation**
1. Monitors query workload and builds a graph to represent joins
2. Uses combinatorial optimization techniques to solve a novel graph theoretical problem optimally
3. Optimizes data distribution to minimize network communication among CNs
- [Fast and Effective Distribution-Key Recommendation for Amazon Redshift](http://www.vldb.org/pvldb/vol13/p2411-parchas.pdf)
- **Automated Materialized views**
- Accelerate predictable workloads
- MVs can be based on one or more Redshift tables or external tables (Spectrum, Federated Query)
- Incremental updates, auto refresh, auto query rewrite
- Automated MVs: Automatically create or delete MVs with incremental refresh
- **Automated workload management**
- Short Query Acceleration
- Short queries do not get stuck behind long running ones
- Customized on the running workload, at runtime
- Query Predictor
- Predict with confidence the resource needs of each query
- Determine the number of queries to process in parallel to optimize throughout, performance and resource utilization
- Used for scheduling decisions
- **Amazon Redshift: 10 years of innovation**
- Tens of thousands of customers process exabytes of data daily with Amazon Redshift
- Industry-leading security and access control, out-of-the box at no additional cost
- Continuous focus on performance and scalability
- Ability to elastically support 10s of PBs of data and 1000s of users
- Autonomics that make Redshift easy to use
- Serverless experience with intelligent compute management
- Tight integration with the broad AWS environment
- Data Mesh with Amazon Redshift Provisioned and Serverless