- https://www.influxdata.com/blog/querying-parquet-millisecond-latency/
# Optimizing queries
- 优化查询性能的通用技术(也适用于 Parquet):
1. reduce IO:减少从存储传输的数据
2. reduce CPU:减少 decode data 的计算开销
3. improve parallelism:interleave/pipeline reading & decoding
----
# Decode optimization
- decoding:CPU-bound,主导了查询延迟。
## Vectorized decode
- vectorized/colunmnar processing
- 一次将==多个 values== 解码成 columnar memory format(如 Arrow),而非逐行处理:
- 好处:
- 均摊 switch on types of column 的开销(类型分支)
- cache locality
- SIMD
- 避免 small heap allocation
- 尤其是变长类型如 strings 和 byte arrays
## Streaming decode
- 背景知识:
- 同一个 row,在不同的 ColumnChunks 中可能位于==不同的 pages==。
- 例如:第 10000 行位于 column A 的第一个 page,在 Column B 中位于第三个 page
- 最简单的 decode 方式:一次 decode 整个 RowGroup 或者 ColumnChunk
- 问题:
- 内存占用大:需要大量 internediate RAM
- 增加查询延迟:后续的处理(如 filter / aggregation)只有当整个 RowGroup
- streaming decode:
- 每次按需输出 batches of rows
- batch size 可配置
- 必须足够大来均摊 decode 的开销
- 也要足够小来减少内存占用和 pipeline 延迟
- 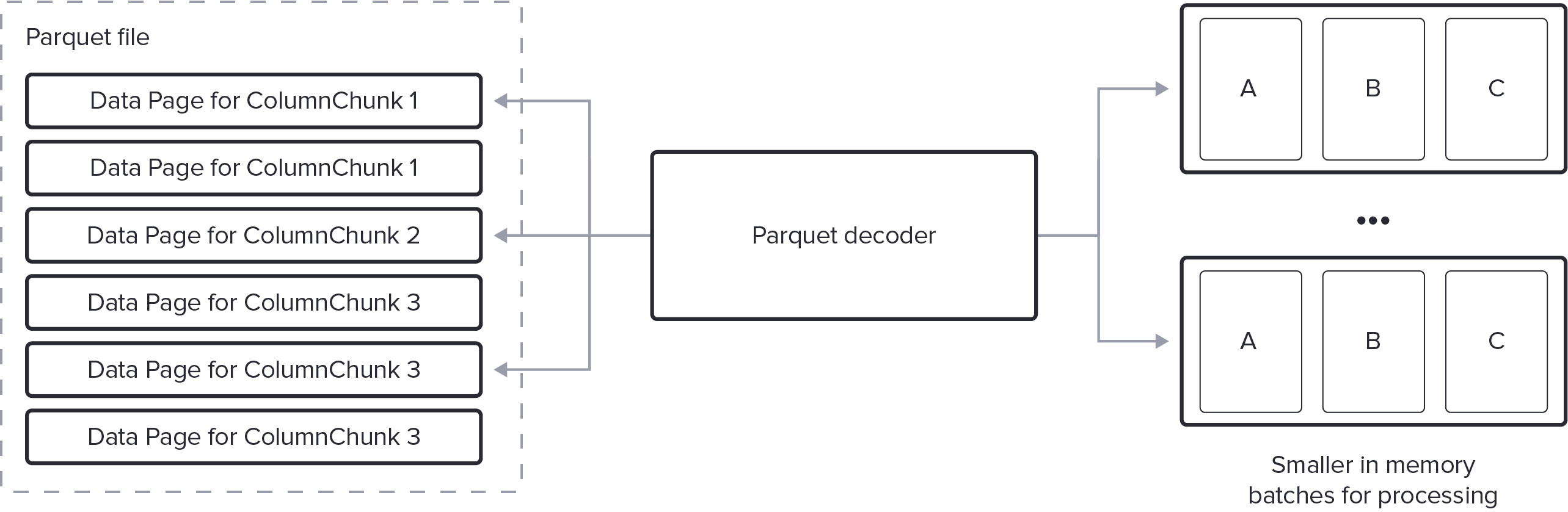
- 实现复杂性:
- across multiple columns and [arbitrarily nested data](https://arrow.apache.org/blog/2022/10/05/arrow-parquet-encoding-part-1/)
- rows 和 values 的关系不固定
## Dictionary preservation
- Dictionary Encoding
- ColumnChunk 的 first page 是一个 dictionary page
- 包含了 column values 列表
- 后续的 pages 编码了到 dictionary 的 indices,而非 column values
- dictionary preservation:
- decode 时不还原 column values,否则会低效地重复相同的 values
- 使用 Arrow [DictionaryArray](https://docs.rs/arrow/27.0.0/arrow/array/struct.DictionaryArray.html),解码后的内存格式仍然使用 dictionary encoding
- 可以极大提升性能(一些 cases 60x)
- 复杂性:
- 处理 dictionary 可能跨多个 RowGroups 的情况(dictionary 是 per-rowgroup 独立的)
- 并且要针对 RowGroup 是 batch size 整数倍的情况,进行特例优化
- [partly dictionary encoded](https://github.com/apache/parquet-format/blob/111dbdcf8eff2e9f8e0d4e958cecbc7e00028aca/README.md?plain=1#L194-L199)
- 某个 column 可能部分使用 dictionary encoding,部分使用 raw values
- 
---
# Projection pushdown
- Parquet reader 只读取 query 需要的 columns。
----
# Predicate pushdown
- 利用 filter expressions 来 skip data,需要和查询引擎结合(scan 时对 predicates 进行求值)
- 使用 [RowSelection](https://docs.rs/parquet/27.0.0/parquet/arrow/arrow_reader/struct.RowSelector.html) API 解耦:上层引擎来指定 读取/skip 的范围
## RowGroup pruning
- 使用 footer 中存储的 statistics 来 skip ==整个 RowGroup==s。
- 例如:查询条件是 A > 35
- 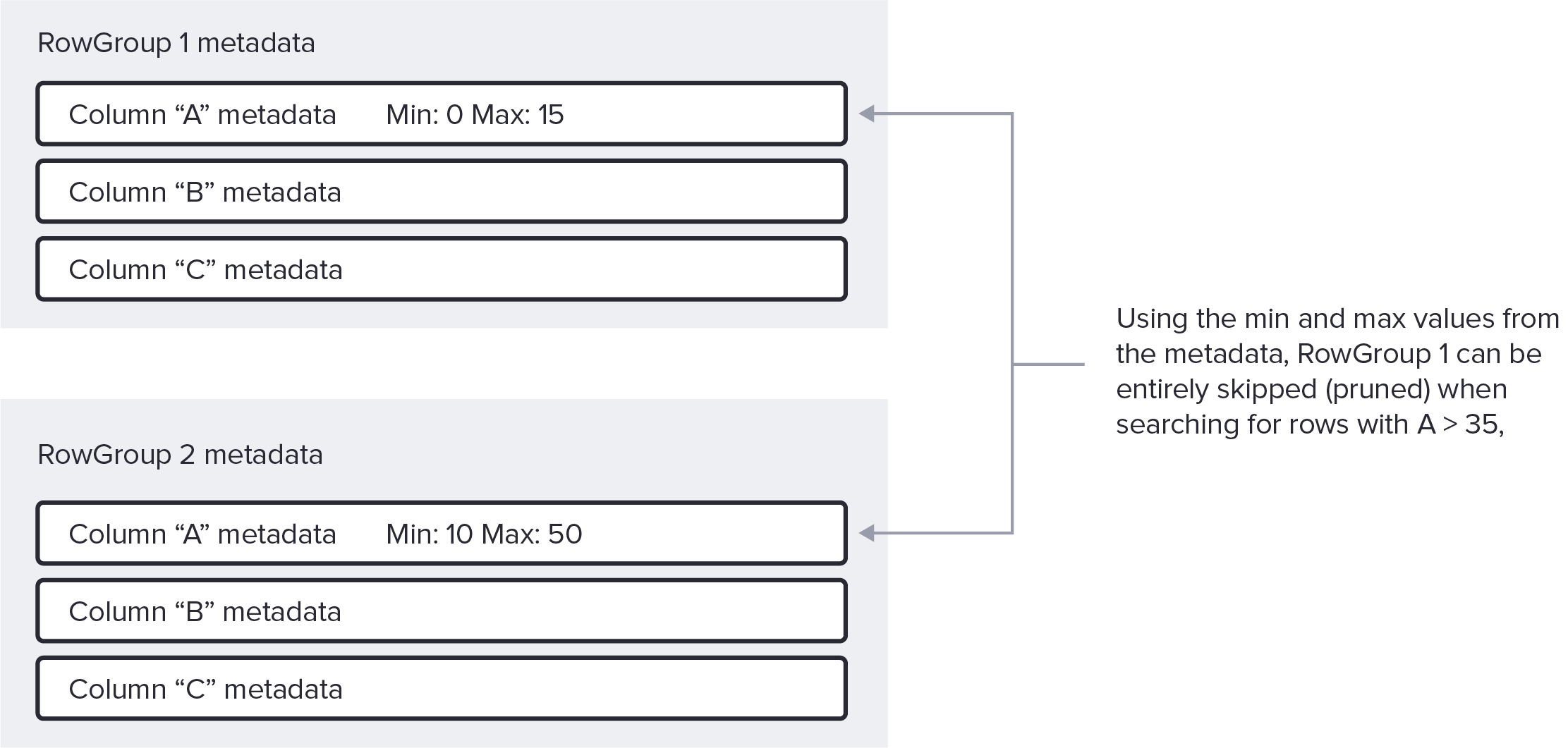
- RowGroup 1 的 列 A 最大值为 15,因此可以整个跳过。
- 支持 per ColumnChunk [Bloom Filters](https://github.com/apache/parquet-format/blob/master/BloomFilter.md)
## Page pruning
- 利用 footer metadata 中的 page index 来跳过某些 data pages。
- 实现的复杂性:
- 不同 ColumnChunks 的 page 经常包含不同数量的 rows
- 导致: pruning 某个 column 的一个 page 后并不会马上排除其他 column 的 page。
- page pruning 的流程:
1. 使用 predicates 结合 page index 来辨别哪些 page 需要 skip
2. 根据 offset index 来计算出需要读取的 row ranges(未被 skipped 的)
3. 计算 non-skipped pages 对应 rows ranges 的交集(多个predicate计算出来的),只解码这些 rows
- 不易实现,特别是对于 nested lists(一行对应多个 values)
## Late materialization
- Only fields that are referenced by predicates and rows that are not filtered out by predicates are fully materialized.
- 示例 predicate:`A > 35 AND B = "F"`
1. 使用列 A 的 page index 确定 RowSelection 为 `[100-244]`(50 rows)
2. 解码 A 列的这 50 个 values
3. 只有 5 rows 匹配,生成新的 RowSelection
- `[205-206]`
- `[238-240]`
4. 只解码 B 列的 5 rows
> [!summary]
> - Projection pushdown 是 skip columns;
> - Predicate pushdown 是 skip rows。
---
# I/O pushdown
- Parquet 为 HDFS 而设计,但它也能很好地适配其他 blob storages 如 S3,因为它们拥有相同的特性:
- slow random read
- **首字节延迟**很大
- 每请求的成本高
- 通常按请求计费
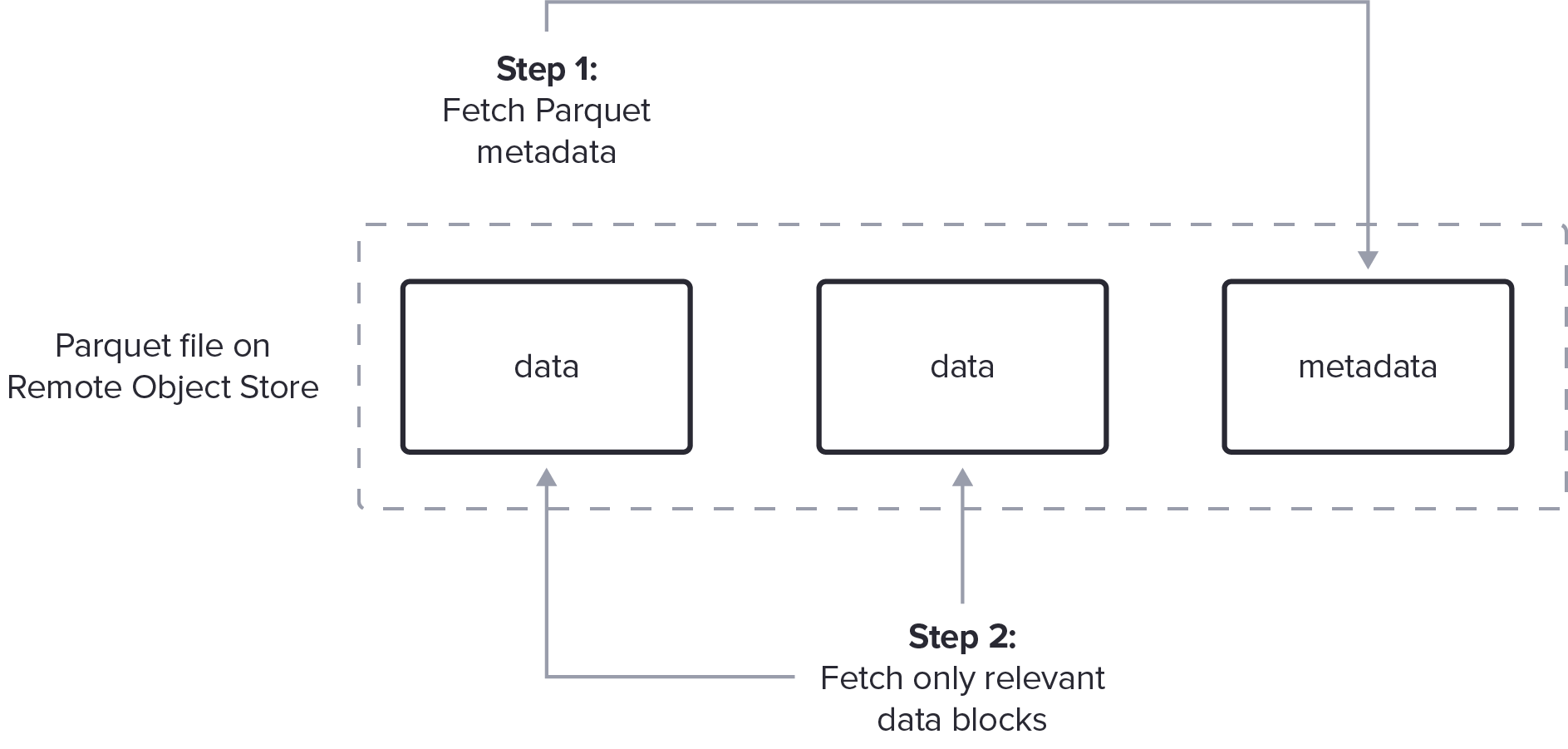
- 为了从此类系统中实现最优的方式读取,Parquet reader 必须:
- 最小化 IO 请求数量,同时也要利用 pushdown 技术来避免读取==无关==数据
- 合理的 task scheduling 机制:可以穿插执行 IO 和 计算(数据处理)。
- 读取==整个==文件然后再处理它们并不理想:
- 高延迟
- 在整个文件被读取完之前,无法解码(metadata 位于 footer)
- 无效工作
- 读取了很多不必要的数据
- 浪费本地磁盘/内存
- 许多云环境对于计算实例不提供 locally attached storage,需要依赖 network block storage( 如 AWS EBS) 或者将 local storage 限制在某些类别的 VM 中。
- 避免 buffer 整个文件,就需要一个复杂的 Parquet decoder:
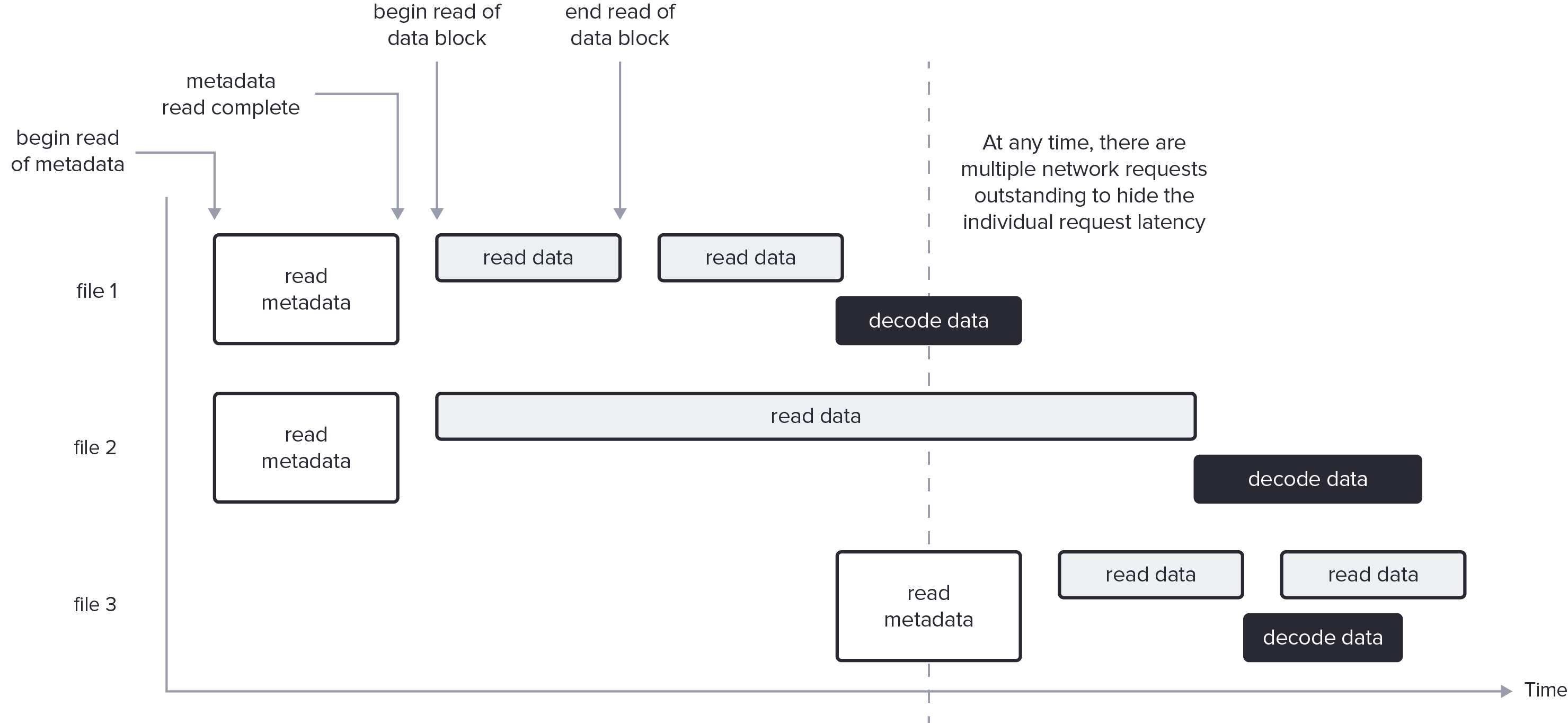
- fetch & decode metadata、ragned fetch 相关 data blocks、穿插数据解码
- 
- 需要仔细设计,从对象存储中获取足够大的 data bloock,使每次请求的开销不会超过减少传输字节所带来的收益。
- [Spark: Decouple CPU with IO work in vectorized Parquet reader](https://issues.apache.org/jira/browse/SPARK-36529)
- Rust Parquet [AsyncFileReader](https://docs.rs/parquet/latest/parquet/arrow/async_reader/trait.AsyncFileReader.html):
- 高效地读取任何支持 range requests 的存储介质
- 使用 [Async Tokio](https://www.influxdata.com/blog/using-rustlangs-async-tokio-runtime-for-cpu-bound-tasks/) 避免阻塞等网络 IO,可以 interleave CPU 和 network。
- 并行请求多个 ranges,合并相邻 ranges
- 使用 pushdown 尽可能消除无关数据
- 方便与 Arrow object_store create 集成
- timeline:
-