- 原文:[Dynamic Filters: Passing Information Between Operators During Execution for 25x Faster Queries](https://datafusion.apache.org/blog/2025/09/10/dynamic-filters)
- 优化技术:TopK 和 dynamic filters
# Motivation and Results
- 典型 query:observability 场景,展示最新的 K 个 traces
```sql
SELECT * FROM records ORDER BY start_timestamp DESC LIMIT 1000;
```
- 即使使用了传统的 Topk 优化,查询仍然很慢。
- 采取了 dynamic filter 之后,性能提升了 10x。
- 类似的 query:[ClickBench q23](https://github.com/apache/datafusion/blob/main/benchmarks/queries/clickbench/queries/q23.sql)
```sql
SELECT * FROM hits WHERE "URL" LIKE '%google%' ORDER BY "EventTime" LIMIT 10;
```
----
# Background
- TopK 优化:
```sql
-- ClickBench Q23 的简化版
SELECT *
FROM hits
ORDER BY "EventTime"
LIMIT 10
```
1. **Naive execution**
- 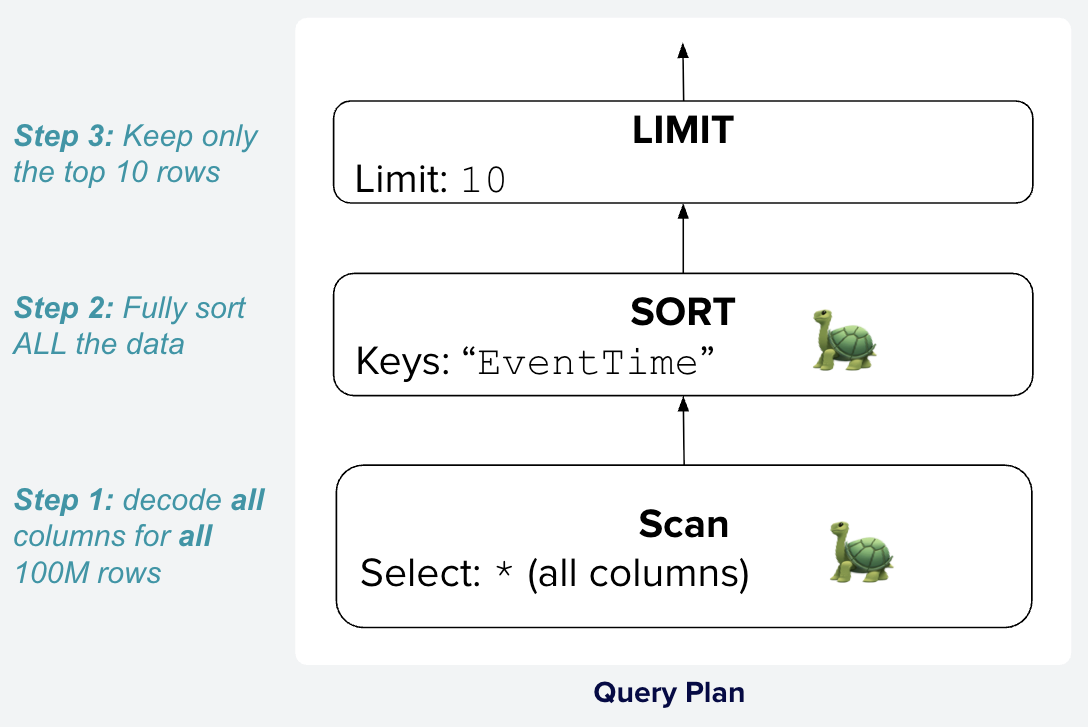
- 问题:
- 需要扫描 hits 表的所有数据,例如 100 M rows
- full sort:内存占用、慢
2. **heap 优化**:
- 
- 使用 min/max heap,内存中只有 10 行
- DataFusion [TopK](https://docs.rs/datafusion/latest/datafusion/physical_plan/struct.TopK.html)
- 优化了 full sort,仍然需要扫描全表。
3. **TopK + dynamic filter**
- 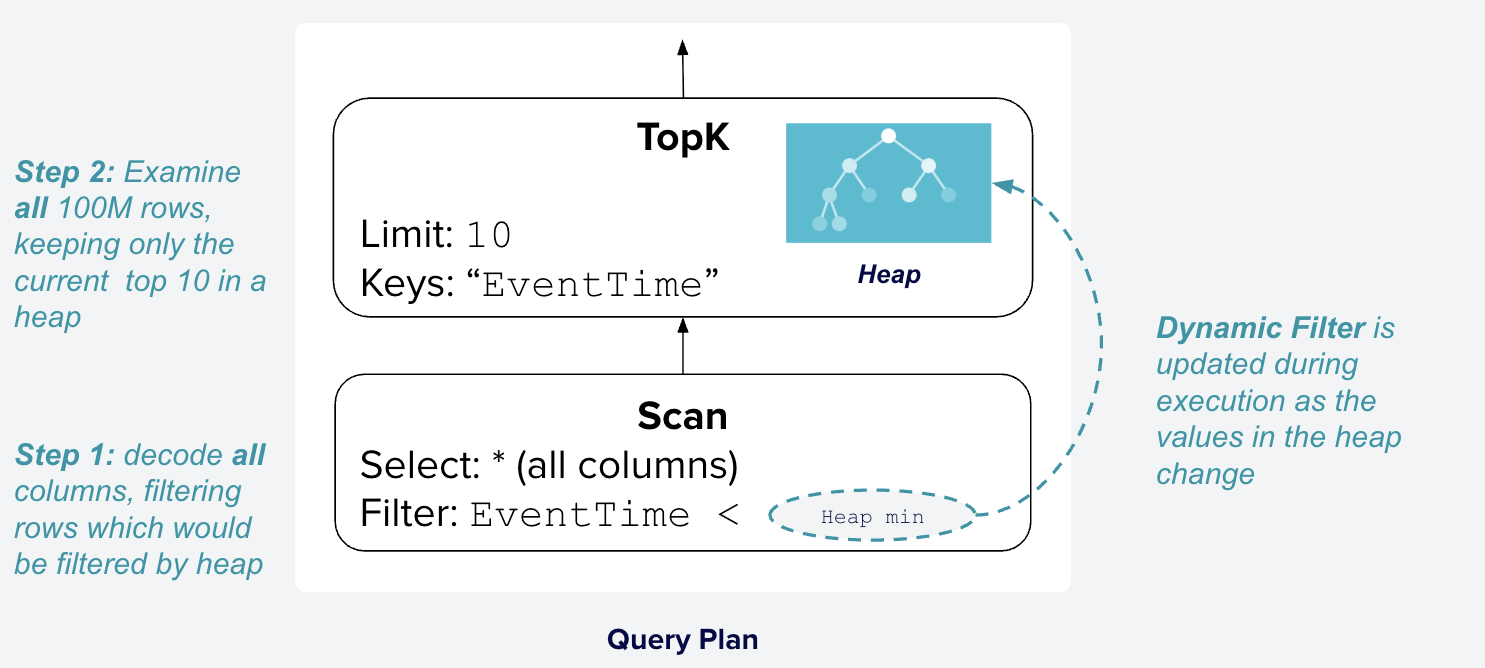
- 小于堆顶的不需要扫描
- 由 TopK 给 scan 算子提供一个 mini EventTime,用于==跳过扫描==小于此值的数据。
----
# TopK + Dynamic Filters
- dynamic filter 初始为 true,后续随着 TopK 执行不断更新
> [!NOTE]- Q23 plan
> - 初始 `DataSourceExec` operator 的 dynamic filter 为 true
> ```text
┌───────────────────────────┐
│ SortExec(TopK) │
│ -------------------- │
│ EventTime@4 ASC NULLS LAST│
│ │
│ limit: 10 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ DataSourceExec │
│ -------------------- │
│ files: 100 │
│ format: parquet │
│ │
│ predicate: │
│ CAST(URL AS Utf8View) LIKE│
│ %google% AND true │
└───────────────────────────┘
>```
>- TopK 更新 dynamic filter
>```text
┌───────────────────────────┐
│ SortExec(TopK) │
│ -------------------- │
│ EventTime@4 ASC NULLS LAST│
│ │
│ limit: 10 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ DataSourceExec │
│ -------------------- │
│ files: 100 │
│ format: parquet │
│ │
│ predicate: │
│ CAST(URL AS Utf8View) LIKE│
│ %google% AND │
│ EventTime < 1372713773.0 │
└───────────────────────────┘
> ```
---
# Hash Join + Dynamic Filters
- 使 dynamic filter 成为一种通用的优化/机制。
- 基于 dynamic filter 机制, 实现了 [sideways information passing](https://15721.courses.cs.cmu.edu/spring2020/papers/13-execution/shrinivas-icde2013.pdf) 技术来提升 hash joins 性能。
- 类似 Spark 的 [Bloom filter joins](https://issues.apache.org/jira/browse/SPARK-32268)
- https://github.com/apache/datafusion/issues/7955
- DataFusion 50.0.0 将 build side 存在哪里 keys ,通过 dynamic filter 推送给 probe side。
- 基于 ==min/max== join key values.
---
# Extensibility
- 自定义 ExecutionPlans 也可以使用 dynamic filters。
## Design of Scan Operator Integration
- 核心设计:将 dynamic filter 表示为 **`Arc<dyn PhysicalExpr>`**
- `DataSourceExec`和其他 scan 算子不需要特殊逻辑来处理 dynamic filters
- 已有的 filter pushdown logic 不需要修改
- `PhysicalExpr` 添加了一些新的功能
- `PhysicalExpr::generation() -> u64`: 用于跟踪 filter tree 是否有变更
- 类似于版本号,operators 用它检测是否需要对 static data 进行 re-evalute filter
- static data:如 file 或者 row group level statistics
- 以实现当 filter 更新后重新 skip file
- `PhysicalExpr::snapshot() -> Arc<dyn PhysicalExpr>`:返回当前版本的 inner static filter
- 可以用于序列号和跨网络传输 filter
- concurrency and information flow:
- push mode:
- write path 如TopK 算子负责更新 filter
- scan path:minimal locking
- dynamic filer:可以理解为 `Arc<RwLock<Arc<dyn PhysicalExpr>>>`
---