- 原文:[https://datafusion.apache.org/blog/2025/03/21/parquet-pushdown](https://datafusion.apache.org/blog/2025/03/21/parquet-pushdown/)
# Why filter pushdown in Parquet?
- 示例 SQL:
```sql
SELECT val,
location
FROM sensor_data
WHERE date_time > '2025-03-11'
AND location = 'office';
```
- 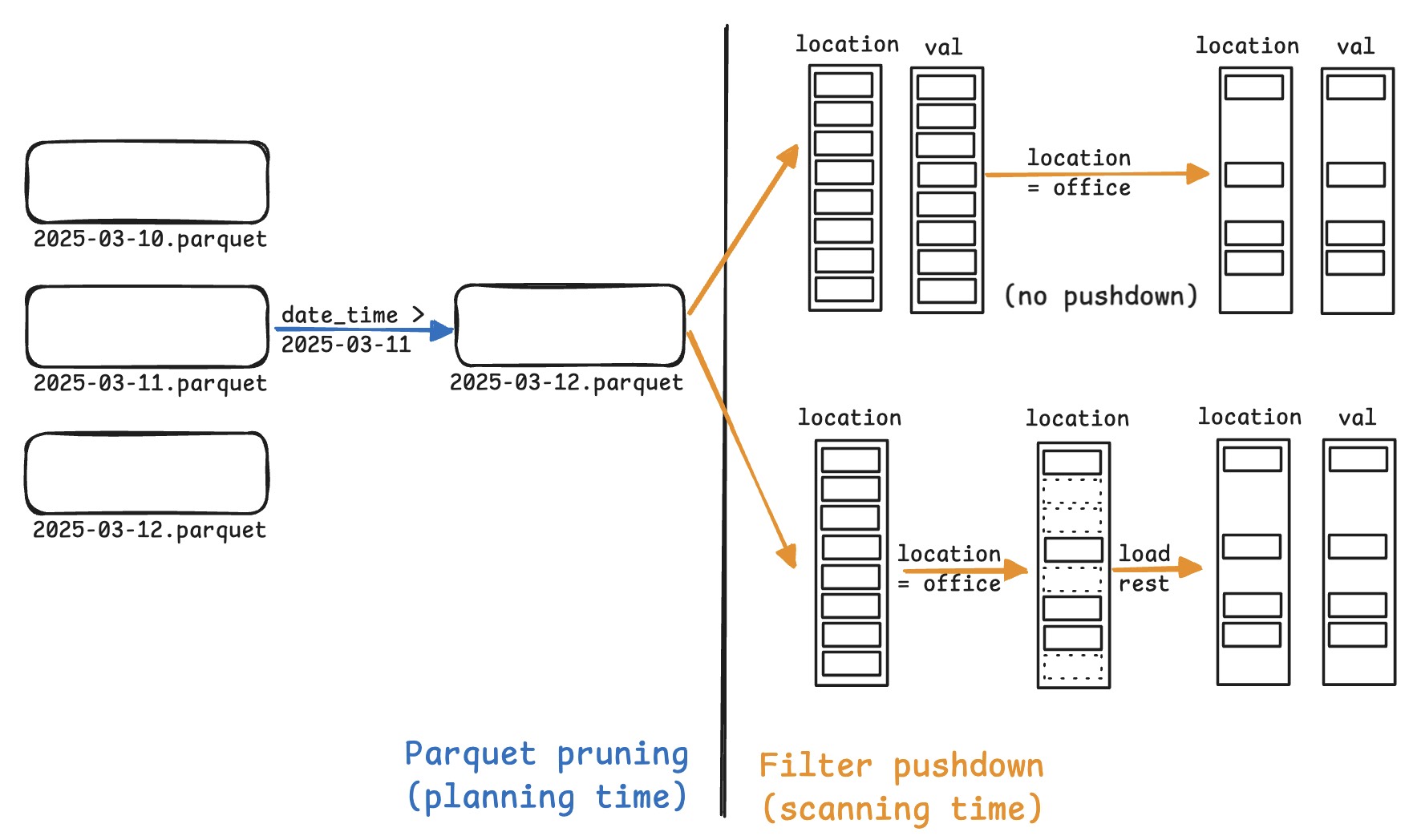
- 如果没有 filter pushdown,会解码所有 rows 的所有 columns,然后再求值 filter。
- filter pushdown with late materialization
- 先 evalute filter conditions,只 decode 通过的数据。
1. 只处理 filter colums,构建满足条件的 rows boolean mask
2. 使用 mask 选择性地 decode 相关 rows
----
# How can filter pushdown be slower?
- filter pushdown 实现:
- 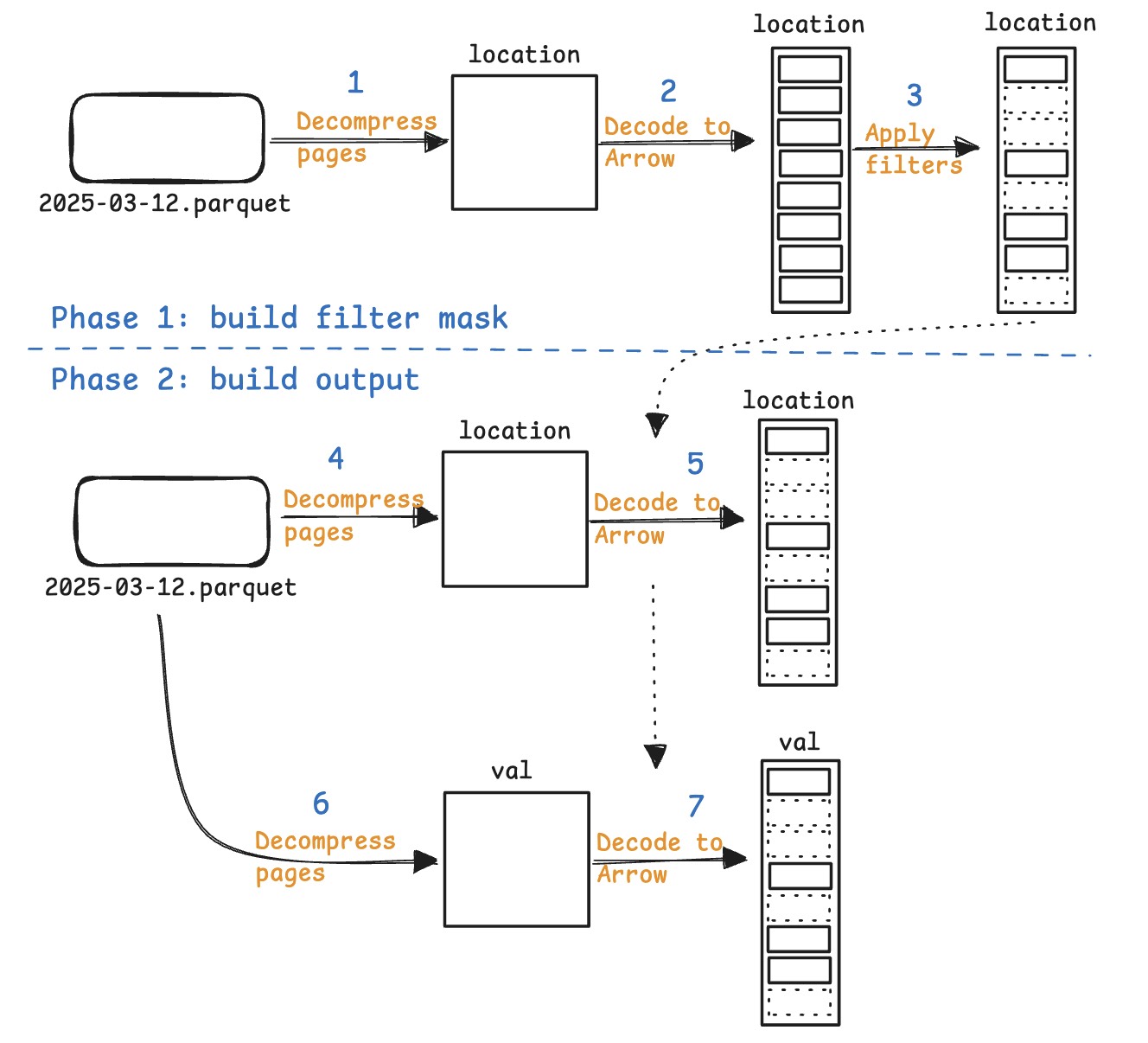
- 两阶段:
1. build filter mask
2. use mask to selectively decode other columns
- 每个阶段中从 Parquet 到 Arrow 都需要三步:
1. Decompress parquet pages( LZ4,zstd 等)
2. Decode page content to Arrow formart
3. Evaluate the filter over Arrow data
- 问题:同时出现在 filter 和 ouput 中的 columns 被 decompressed 和 decoded 了==两次==。
- 例如示例中的 location 列
---
# Attempt: cache filter columns
- 直观地看,缓存 filter columns 并在以后重用它们可能会有所帮助。
- 但是简单地缓存 decoded pages 会耗费过高的内存:
1. 需要缓存 Arrow arrays,平均比 Parquet data ==大 4 倍==。
2. 需要在内存中缓存==整个 column chunk==
- 因此阶段 1 是在 column chunk 之上构建的 filters
3. 内存占用跟 filter columns 的数量成正比,可能无限大
- 另外,缓存 filter columns 意味着部分从 Parquet 中读取,部分从 cache 中读取,使得实现变得复杂。
---
# Real solution
- 设计目标:
- 易于实现
- 最小化内存开销
- PR:
- [Experimental parquet decoder with first-class selection pushdown support #6921](https://github.com/apache/arrow-rs/pull/6921#issuecomment-2718792433)
- **New pipeline**
- building filter mask and output columns are ==interleaved in a single pass==
- 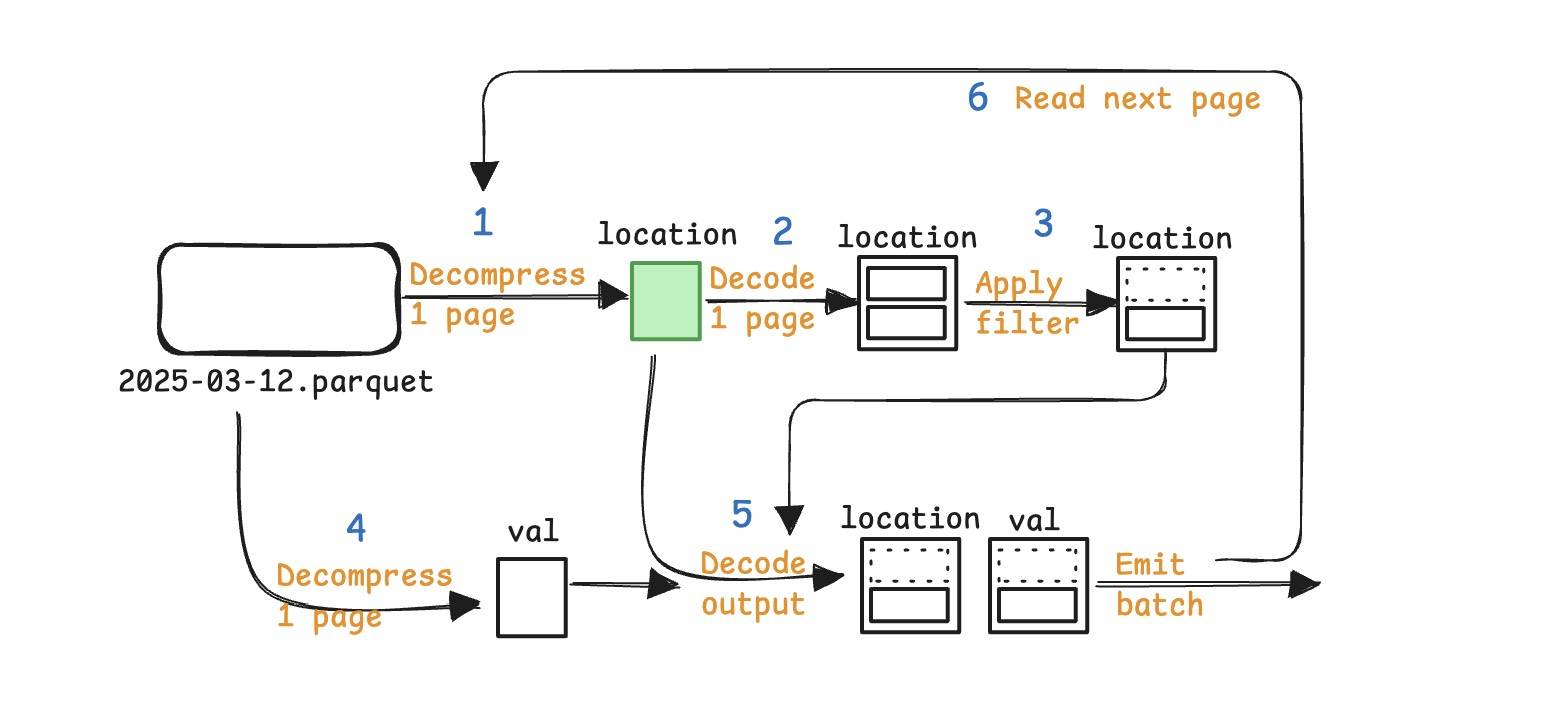
- The page being decompressed is immediately used to build filter masks and output columns
- 最多只缓存==一个 page==
- **What pages are cached?**
- 只有同时出现在 filters 和 output 中的 columns 才会被缓存。
- **Then why cache 2 pages per column instead of 1?**
- Dictionary Encoding
- 解码一个 page 时,会引用两个page:
- dictionary parge
- data page