- 原文:[A Practical Dive Into Late Materialization in arrow-rs Parquet Reads](https://arrow.apache.org/blog/2025/12/11/parquet-late-materialization-deep-dive/)
- 主题: arrow-rs 的 ParquetReader 如何实现延迟物化
- 需要复杂的逻辑来 evaluate predicates,实际上已经变成了一个 tiny query enigne。
----
## 1. Why Late Materialization
- Column reads:constant battle between I/O bandwidth and CPU decode costs
- skipping data 自身也会带来计算开销。
- 对于能过滤掉许多 rows 的 predicates,延迟物化能最最小化 reads 和 decode work。
- pipleline-style late materialization:
1. evalute predicate
2. access projected columns
- interleaving predicates and data column access
- Paper:[Materialization Strategies in a Column-Oriented DBMS](https://www.cs.umd.edu/~abadi/papers/abadiicde2007.pdf)
- 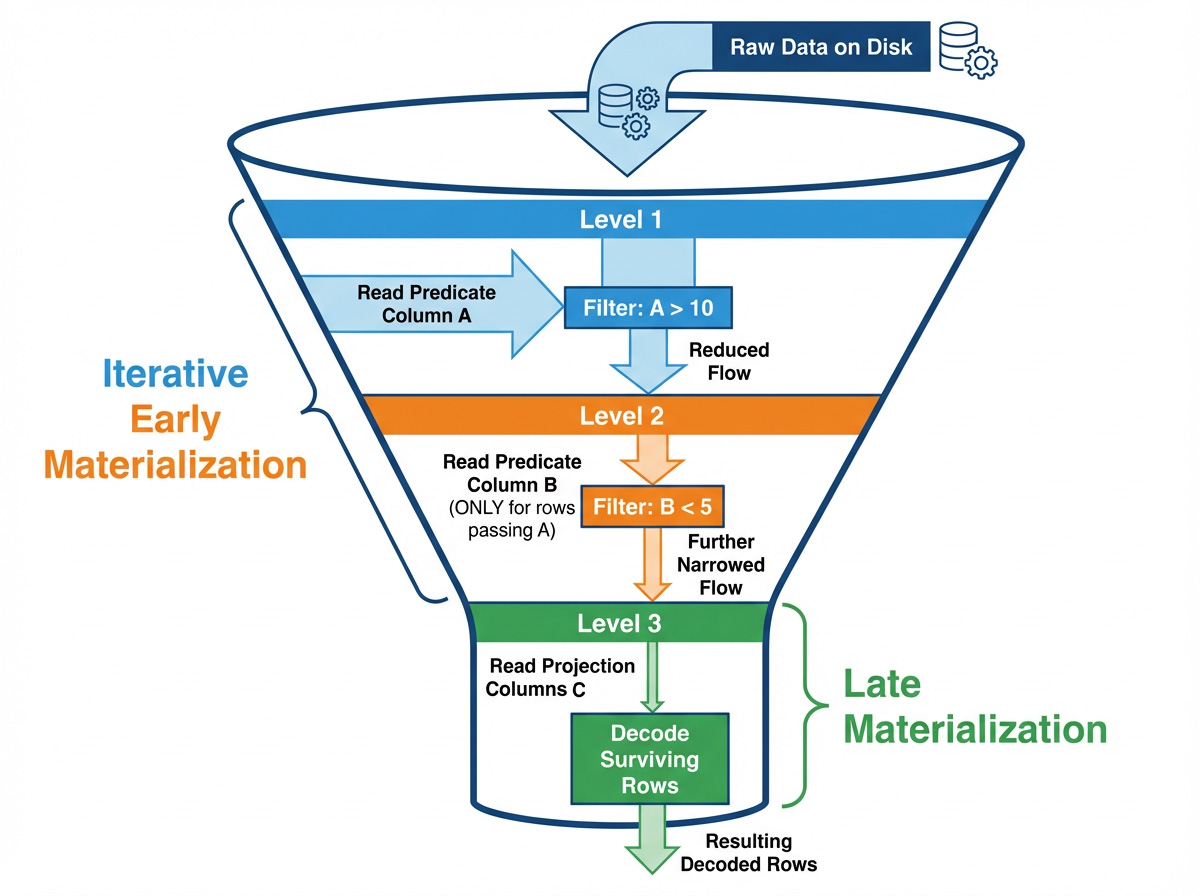
- 示例查询:`SELECT B, C FROM table WHERE A > 10 AND B < 5`
1. 读 A 列,evaluate `A > 10`,构建一个 `RowSelection`(a sparse mask),代表初始的有效 rows
2. 使用上面的 `RowSelection`,读 B 列并 evaluate `B < 5`,然后更新 `RowSelection`,使其变得更稀疏
3. 使用更新后的 `RowSelection` 读 C 列,只 decode 最终有效的 rows(未被过滤掉的)
---
## 2. Late Materialization in the Rust Parquet Reader
### 2.1 LM-pipelined
- 两种策略:
1. **pipelined** strategy
```mermaid
graph LR
A[Read Predicate Column] --> B[Generate Row Selection]
B --> C[Read Data Column]
```
- 顺序性依次读取 predicate columns
2. **parallel** strategy:并行读取所有 predicate columns
- 能最大化利用多核 CPU
- 通常 ==pipelined 更优==,因此每个 filter 能大量减少后续步骤需要读取的数据。
- 代码结构中的 core roles:
- **[ReadPlan](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/read_plan.rs#L302) / [ReadPlanBuilder](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/read_plan.rs#L34)**
- 将读取哪些列和哪些 row 子集组织成一个 plan
- **[RowSelection](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/selection.rs#L139)**
- 两种实现:
- RLE(通过 RowSelector)来 skip/select N rows
- Arrow BooleanBuffer bitmask 来 filter rows
- 可以动态切换。
- bitmask:适合 tiny gaps 和 high sparsity
- RLE:适合 large,page-level skips
- **[ArrayReader](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/array_reader/mod.rs#L85)**
- 负责 decoding。
- 接收 `RowSelection` ,决定读取哪些 pages 和 decode 哪些 values
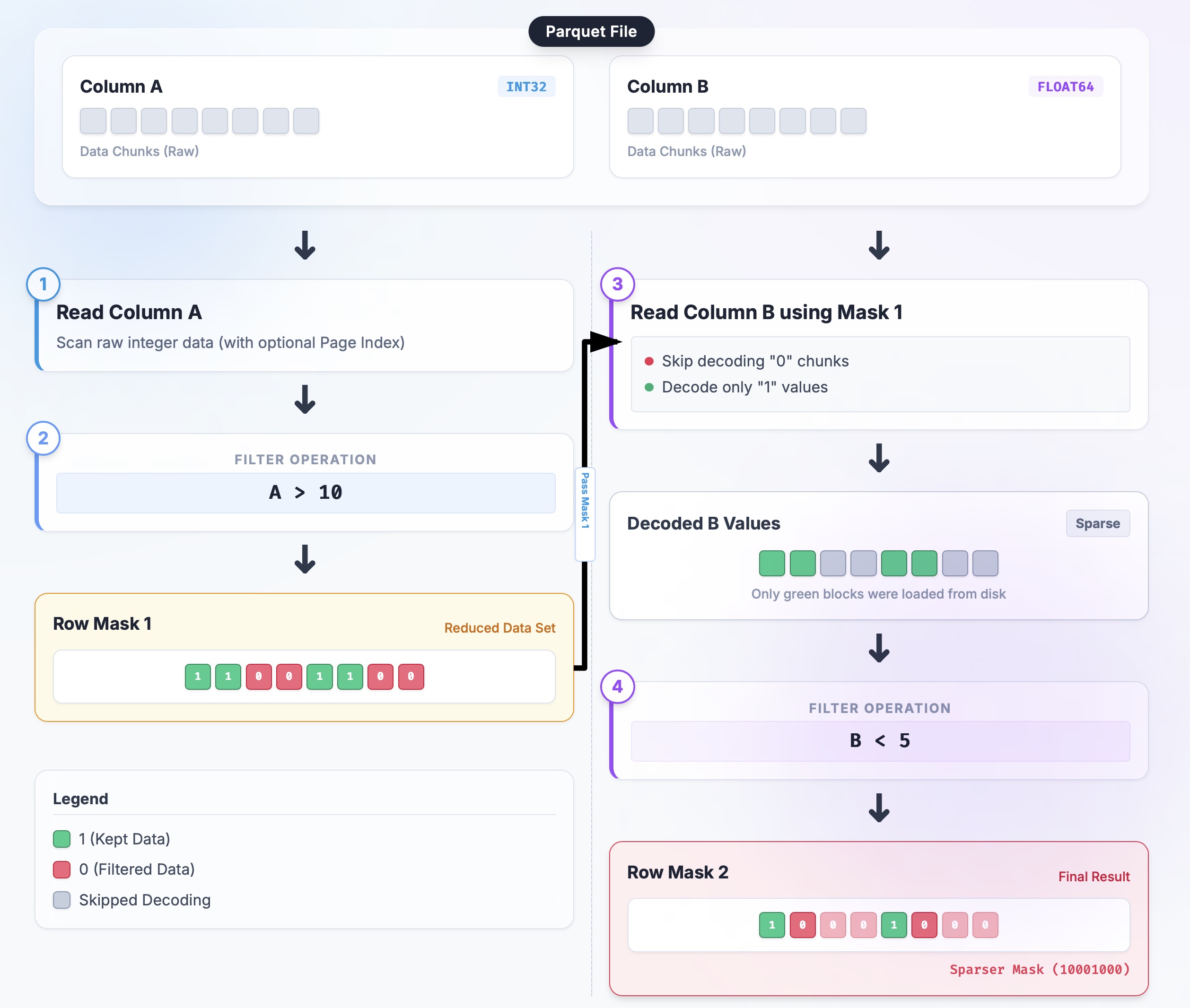
- 示例查询:x `SELECT B, C FROM table WHERE A > 10 AND B < 5`
1. 初始化:`selection = None`(select all)
2. Read A:
1. ArrayReader 读 A 列;
2. 利用 predicate 构建一个 boolean mask;
3. 使用 [`RowSelection::from_filters`](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/selection.rs#L149)转换为一个 sparse selection
3. Tighten:
- 将上面的 selection 传递给 ReadPlan
- [`ReadPlanBuilder::with_predicate`](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/read_plan.rs#L143)通过 [`RowSelection::and_then`](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/selection.rs#L345) chains new mask
4. Read B:
- 使用当前 `selection` 构建 B 列的 reader;
5. Merge:
- `selection = selection.and_then(selection_b)`
```rust
// Close to the flow in read_plan.rs (simplified)
let mut builder = ReadPlanBuilder::new(batch_size);
// 1) Inject external pruning (e.g., Page Index):
builder = builder.with_selection(page_index_selection);
// 2) Append predicates serially:
for predicate in predicates {
builder = builder.with_predicate(predicate); // internally uses RowSelection::and_then
}
// 3) Build readers; all ArrayReaders share the final selection strategy
let plan = builder.build();
let reader = ParquetRecordBatchReader::new(array_reader, plan);
```
- 
### 2.2 Combining row selectors
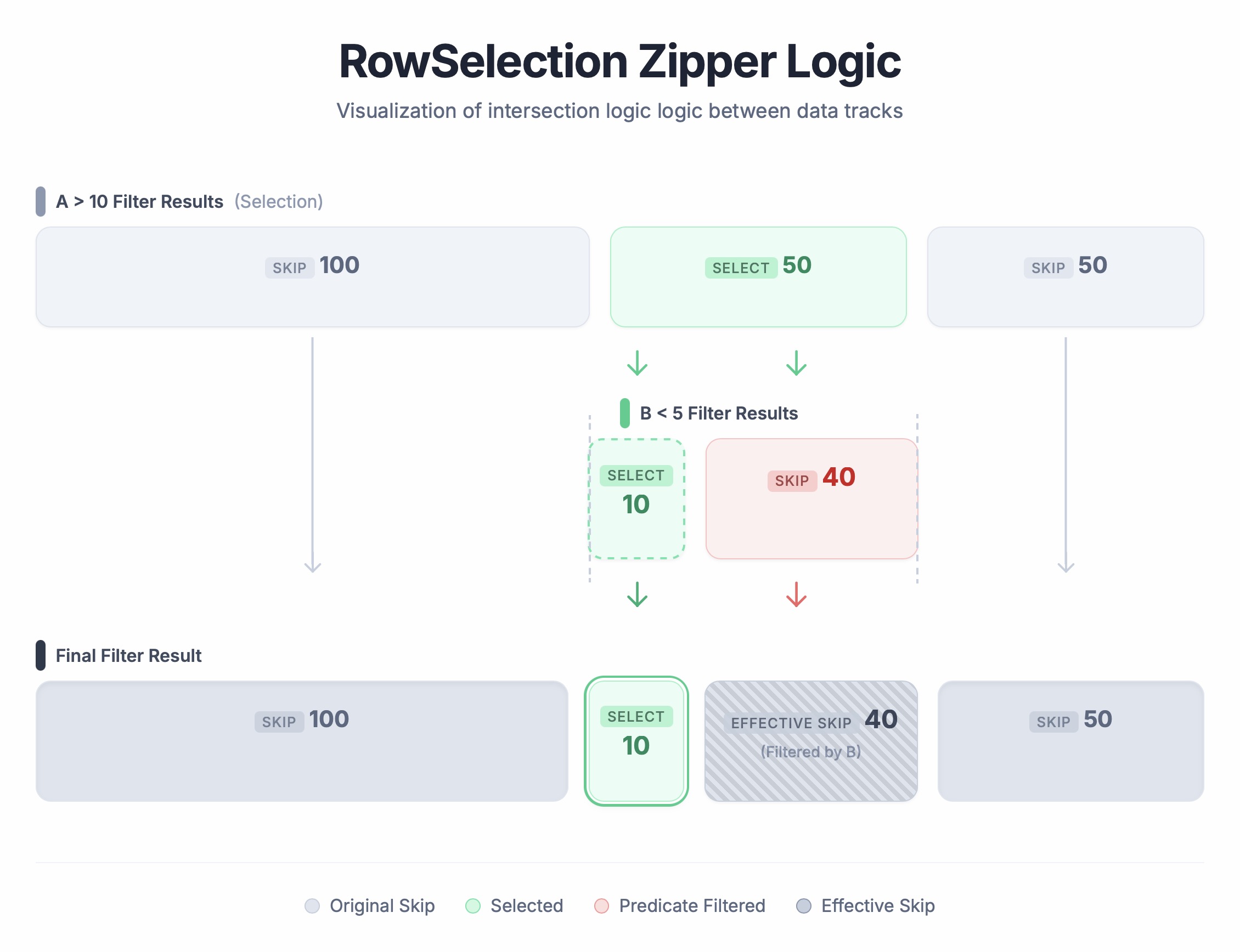
- [`RowSelection::and_then`](https://github.com/apache/arrow-rs/blob/bab30ae3d61509aa8c73db33010844d440226af2/parquet/src/arrow/arrow_reader/selection.rs#L345)
- 对两个 RowSelection 做 AND 操作,用于串联两个 filter 的结果
- 示例:
- Input Selection A:`[Skip 100, Select 50, Skip 50]`
- 只选中 rows 100-150
- Selection B(在 A 之上继续 filter):`[Select 10, Skip 40]`
- 只选择 A 中的 前 10 rows,即 100-110
- 结果:`[Skip 100, Select 10, Skip 90]`
```rust
// Example: Skip 100 rows, then take the next 10
let a: RowSelection = vec![RowSelector::skip(100), RowSelector::select(50)].into();
let b: RowSelection = vec![RowSelector::select(10), RowSelector::skip(40)].into();
let result = a.and_then(&b);
// Result should be: Skip 100, Select 10, Skip 40
assert_eq!(
Vec::<RowSelector>::from(result),
vec![RowSelector::skip(100), RowSelector::select(10), RowSelector::skip(40)]
);
```
- 
---
## 3. Engineering Challenges
### 3.1 Adaptive RowSelection Policy (Bitmask vs. RLE)
- Paper: [Filter Representation in Vectorized Query Execution](https://db.cs.cmu.edu/papers/2021/ngom-damon2021.pdf)
- no 'one-size-fits-all' format for `RowSelection`
- 最优的内部格式是一个==动态变化==的目标,会随着稀疏模式的不同而不断调整
- Ultra sparse:
- 例如每 1w 行选择 1 行。
- 使用 bitmask 会非常浪费;适合 RLE
- Sparse but tiny gaps:
- 例如重复的 "read 1, skip 1"
- RLE 会产生严重的碎片化,bitmask 会更高效
- **Adaptive strategy**
- PR: [Adaptive Parquet Predicate Pushdown #8733](https://github.com/apache/arrow-rs/pull/8733)
- 检查 selector 的 平均 run length,如果小于阈值 ==32==, 使用 bitmask;否则继续使用 RLE。
- 平均值计算:[resolve_selection_strategy](https://github.com/apache/arrow-rs/blob/2a77e106fd762692c30540a577a08a9825e22245/parquet/src/arrow/arrow_reader/read_plan.rs#L103)
- `total_rows`:总共 selected 或 skipped 多少行
- `effective_count`:selectors 的数量
- avg:`total_rows / `effective_count`
- 32 的测试依据: [data-driven "face-off"](https://github.com/apache/arrow-rs/pull/8733#issuecomment-3468441165)
- **The Bitmask Trap: Missing Pages**
- 问题:bitmask 跟 page pruning 结合时,某个完整的 page 被跳过了
- RLE:
- 
- bitmask:
- 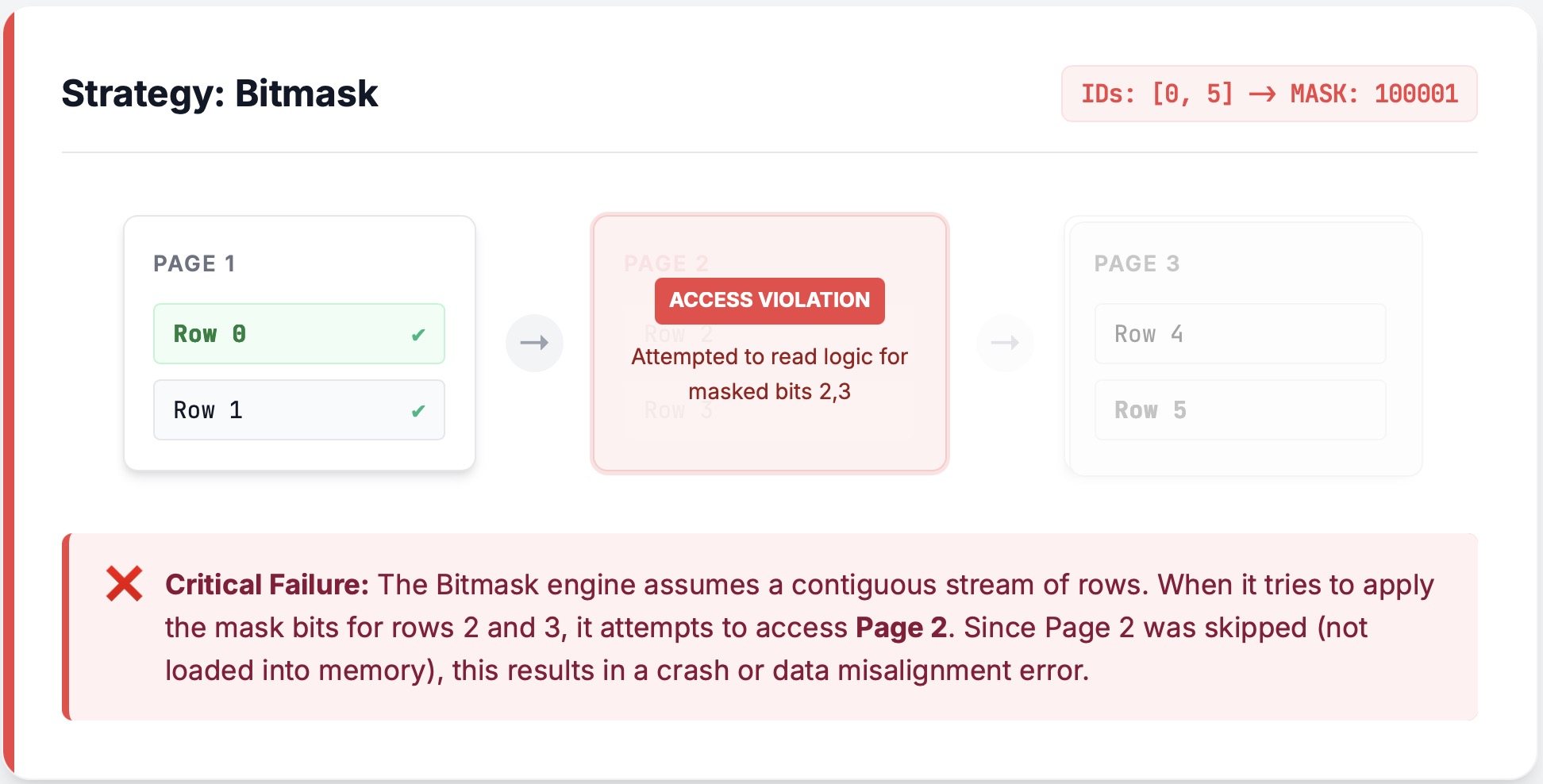
- bitmask 会==先读取== 6 行,再应用 bitmask。
- 解决:检查到这种情况后,回滚使用 RLE。
- [override_selector_strategy_if_needed](https://github.com/apache/arrow-rs/blob/2a77e106fd762692c30540a577a08a9825e22245/parquet/src/arrow/push_decoder/reader_builder/mod.rs#L700)
### 3.2 Page Pruning
> The ultimate performance win is **not doing I/O or decoding at all**.
- 使用 PageIndex 来 skip pages,节省 IO 和 CPU(decompression & decoding).
- ⚠️:即使 RowSelection 只 select page 中的一行,也需要解压缩整个 page 。
- 实现:
- [`RowSelection::scan_ranges`](https://github.com/apache/arrow-rs/blob/ce4edd53203eb4bca96c10ebf3d2118299dad006/parquet/src/arrow/arrow_reader/selection.rs#L204) 结合每个 page 的 metadata 计算出需要读取的 pages
- page metadata:
- `compressed_page_size`:page 大小
- `first_row_index`:page 起始行号
- 输出:**byte ranges** 即 `(offset, length)` list
- 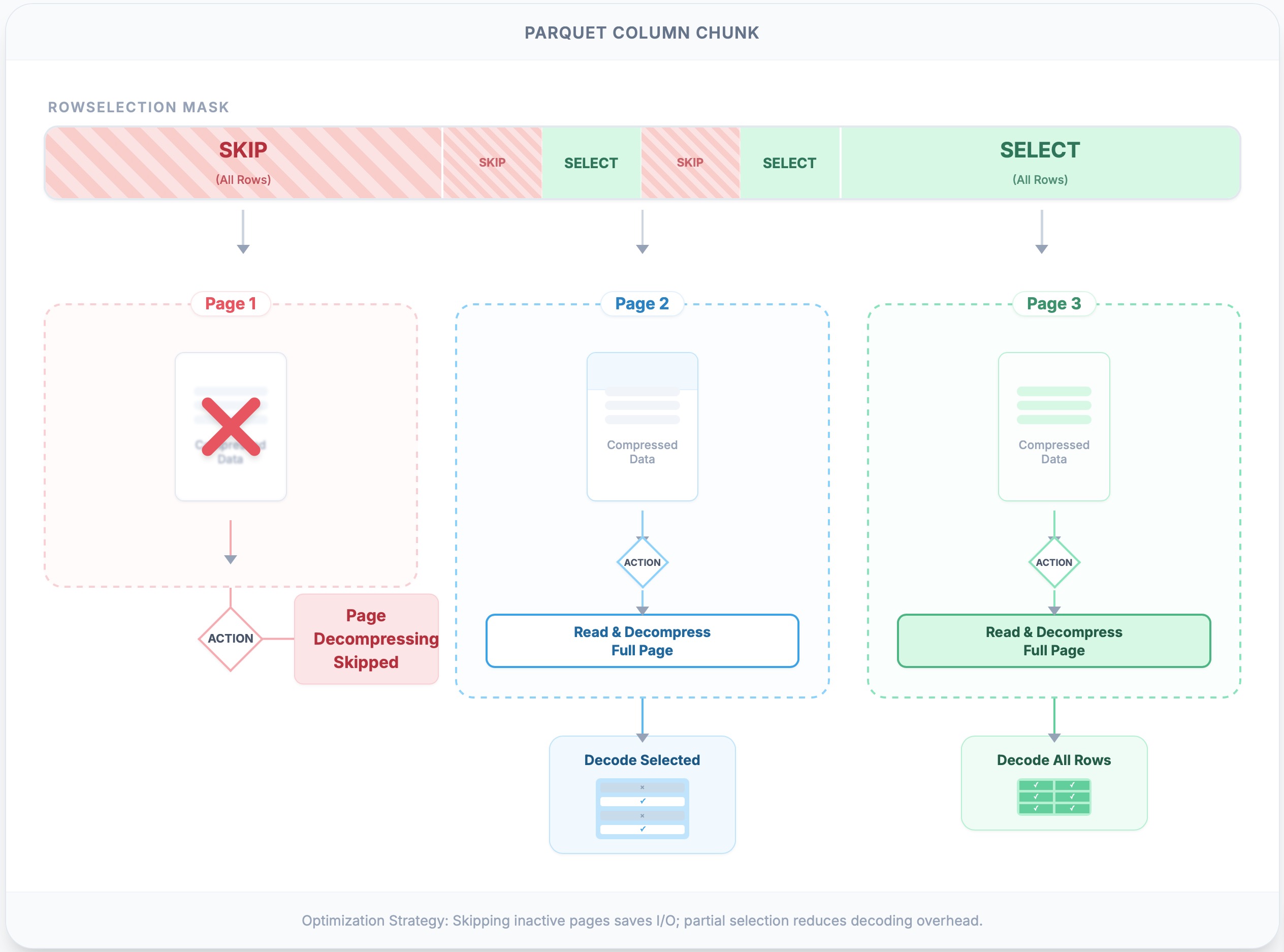
> [!summary] Page pruning
> - `RowSelection` 包含了需要读取的 rows
> - `RowSelection::scan_ranges` 根据上述信息和 page index,计算出需要读取的 pages 位置
> - 即 selected rows -> selected pages(byte ranges in file)
> - logical row filtering -> physical byte fetching
### 3.3 Smart Caching
- double tax
- 延迟物化:为了高效的 skip data,需要先读取它(即 filter columns)。
- 问题: skip 时读取一次,output / projection 时再读取一次。
- [[parquet-efficient-filter-pushdown-blog]]
- 解决:[`CachedArrayReader`](https://github.com/apache/arrow-rs/blob/ce4edd53203eb4bca96c10ebf3d2118299dad006/parquet/src/arrow/array_reader/cached_array_reader.rs#L40-L68)
- [#arrow-rs/7850](https://github.com/apache/arrow-rs/pull/7850)
- 缓存第一次 decoded batch,projection 时进行重用。
- **Dual-Layer** Cache:
- **The Shared Cache**:
- 所有 columns 和 readers 共享的 global cache,有容量限制,==不一定命中==。
- 当解码 predicate page 后插入到 cache 中,projection 时读取。
- **The Local Cache**
- column reader 私有,当前 pipeline 片段中一直持有,一定会命中。
- ==优先读取==
### 3.4 Minimizing Copies and Allocations
- [`PrimitiveArrayReader`](https://github.com/apache/arrow-rs/blob/ce4edd53203eb4bca96c10ebf3d2118299dad006/parquet/src/arrow/array_reader/primitive_array.rs#L102) 实现了 zero-copy
- 直接接管 decoded `Vec<T>`,而非 memcpy 到 Arrow Buffer
- [PrimitiveArray: From a Vec](https://docs.rs/arrow/latest/arrow/array/struct.PrimitiveArray.html#example-from-a-vec)
### 3.5 The Alignment Gauntlet
- Chained filtering 使用了 relative offset
- Row 1" in filter N might actually be "Row 10,001" in the file due to prior filters.
- 使用 [fuzz test](https://github.com/apache/arrow-rs/blob/ce4edd53203eb4bca96c10ebf3d2118299dad006/parquet/src/arrow/arrow_reader/selection.rs#L1309) 测试 offset 转换的正确性