- 原文:[Parquet Pruning in DataFusion: Read Only What Matters](https://datafusion.apache.org/blog/2025/03/20/parquet-pruning/)
# The Pipleline
- 不同的 pruning stages:
- 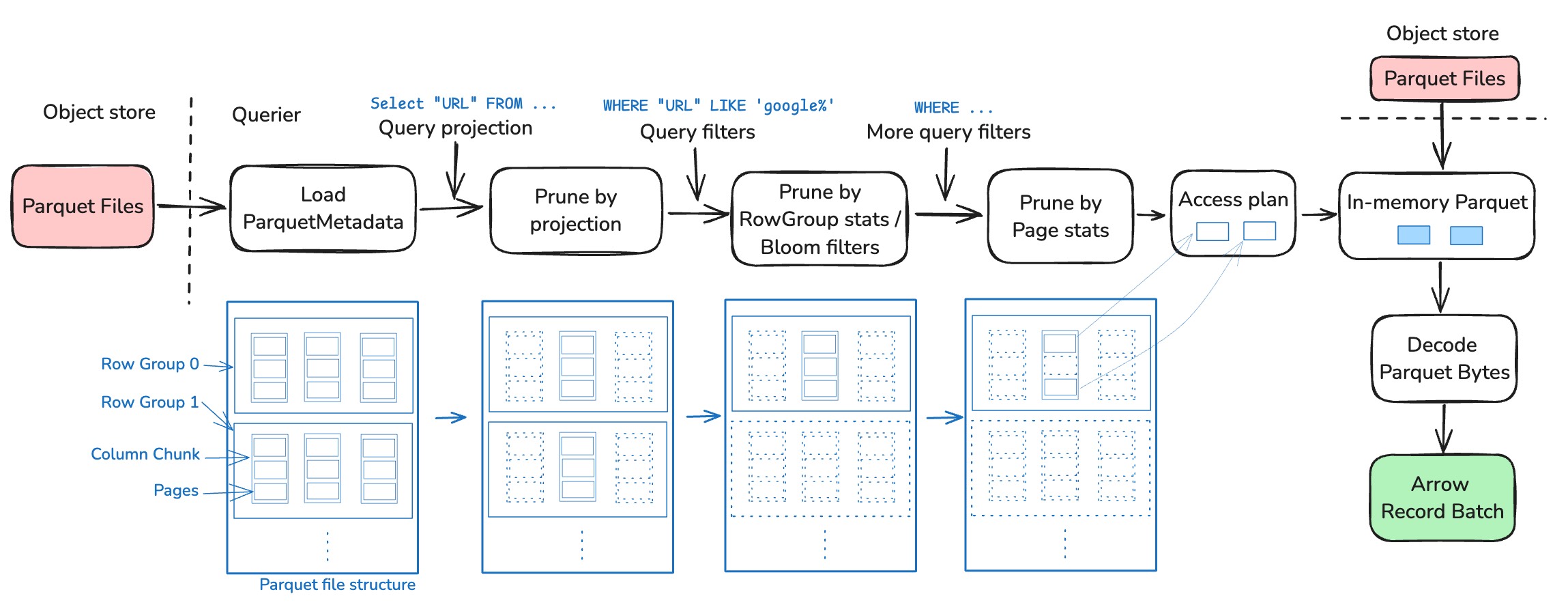
1. ReadMetadata
- Metadata 包括 schrma,每个 row group 和column chunk 的位置及统计信息。也可能包含 page-level stats 和 bloom filters
- [Fetching metadata](https://github.com/apache/datafusion/blob/31701b8dc9c6486856c06a29a32107d9f4549cec/datafusion/core/src/datasource/physical_plan/parquet/reader.rs#L118) 需要两次网络请求:
- 从文件结尾读取 footer size
- 读取 footer 内容
- [Decoding metadata](https://www.influxdata.com/blog/how-good-parquet-wide-tables) 通常很快;但需要列很多,metadata 很大解码可能会成为瓶颈,尤其对于许多 small files。
2. Prune by projection
- 只读取需要的列
3. Prune by row group stats and Bloom filters
- 利用 row group 级别的统计信息如 min/max 和 bloom filter,来跳过整个 row group
- [DataFusion bloom filter Impl](https://github.com/apache/datafusion/blob/3aaf393fe32e30ec818b9cfab99a08326f1cad2c/datafusion/datasource-parquet/src/opener.rs#L1046)
4. Prune by page stats
- [DataFunsion `prune_plan_with_page_index`](https://github.com/apache/datafusion/blob/3aaf393fe32e30ec818b9cfab99a08326f1cad2c/datafusion/datasource-parquet/src/opener.rs#L1117)
- 跳过 pages
5. Read from storage
- 形成 [AccessPlan](https://github.com/apache/datafusion/blob/3aaf393fe32e30ec818b9cfab99a08326f1cad2c/datafusion/datasource-parquet/src/access_plan.rs#L91) 读取文件内有效的范围,并解码成 Arrow RecordBatch
---
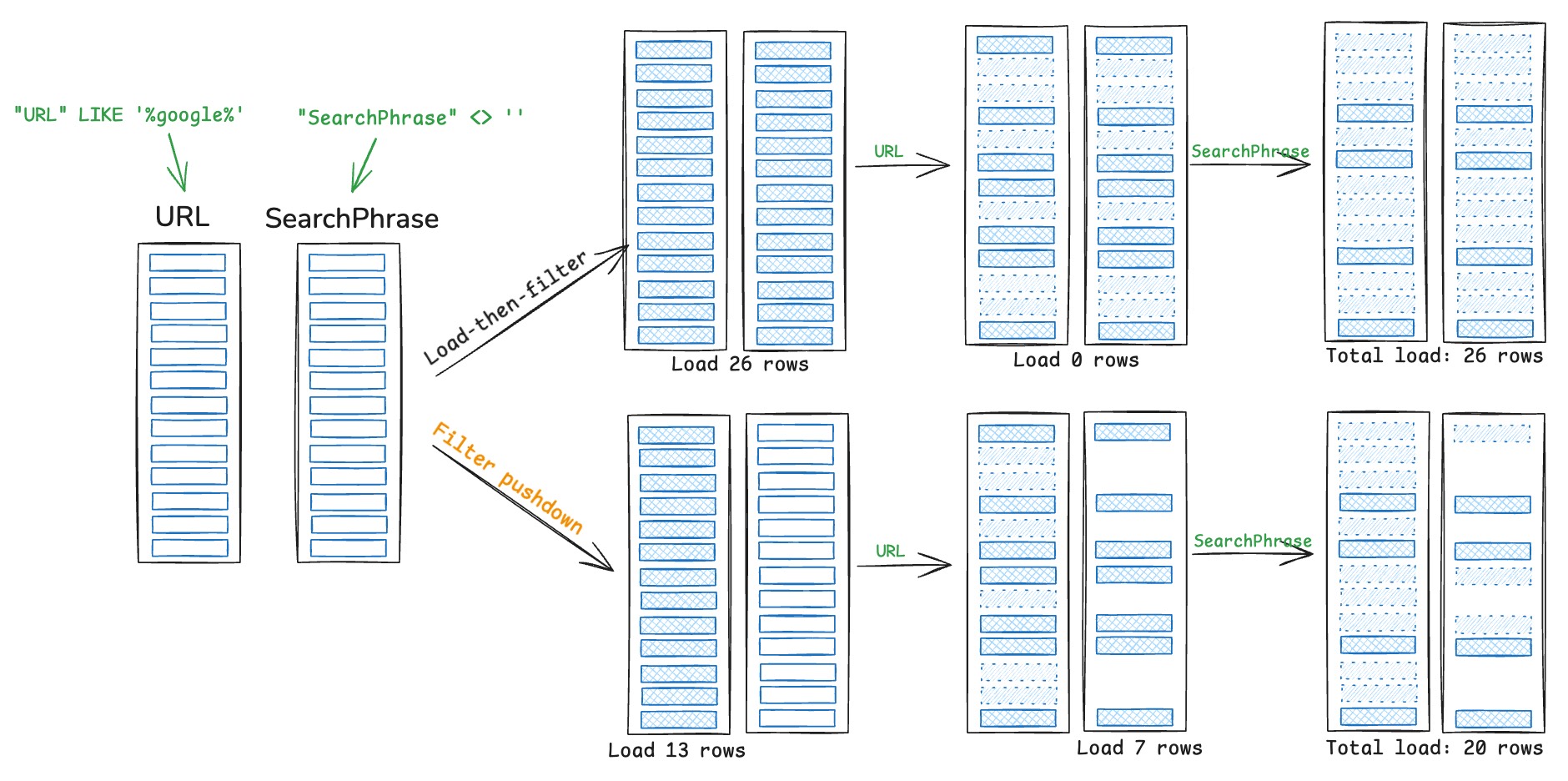
# Filter pushdown
- 前面讨论的都是只利用 ==metadata== 来 prune parquet,即不读取实际的数据。
- **filter pushdown**:predicate pushdown or late materialization
- prunes data during scanning, apply filter in the Parquet reader
- ==row-level==
- 
---
> [!summary] Parquet-pruning
> - projection pushdown: prune 掉不需要的 **columns**
> - metadata: **RowGroup** 和 **Page** 级别的 pruning
> - filter pushdown: 进行 **Row** 级别的 pruning