# ABSTACT
- **问题背景**:serving和analytical在不同系统中,导致额外的数据重复、负责的开发和维护成本。
- **定位**:
- cloud natvice HSAP(serving & analytical processing)
- 在线服务(需要高性能/点查)
- **特点**:
- 存算分离
- table分区为自管理的shard,每个shard可以并行读写
- 行列混合存储
- Execution context
- 系统线程和用户任务之间的资源抽象
- 使用更小的上下文切换的开销,协作式调度
- 支持自定义调度策略
-------
# 1. INTRODUCTION
- HSAP的挑战:
- 处理比传统OLAP更高的查询负载,且查询方式是混合的,有着不同的延迟和吞吐上的权衡
- 高吞吐的data ingestion,秒级可见
- 混合负载且变化性大,系统需要是弹性和可扩展的
## 1.1 Storage Design
- 存算分离,数据持久化到云存储。
- 分shard,每个shard是独立的,并行处理读写。
- shard可在wrokers之间灵活迁移。
- shard上数据是多版本:支持低延迟查询和高吞吐写入。
## 1.2 Concurrent Query Execution
- 面向服务的资源管理和调度框架:HOS。
- HOS使用 execution context 作为系统线程之上的资源抽象。
- 查询执行并行化:
- 拆分query为细粒度的work units,然后分发给execution contexts。
- ec可以做资源隔离(低延迟的 serving workloard 和 analytical 可以同时处理)。
------
# 2. KEY DESIGN CONSIDERATION
## 2.1 Data Storage
- **存算分离**
- 所有数据文件和log存储在 Pangu,也支持HDFS
- **Tablet-based Data Layout**
- table tablet 和 关联的 index tablet 组成一个 group。
- single writer & mutli reader
- **读写分离**
- 写入亚秒级可见
- 多版本
## 2.2 Concurrent Query Execution
- Execution Context
- user-space thread,轻量级,创建和销毁的开销可以忽略。
- 在系统线程池之上调度 EC,
- 可定制的调度策略
- 不同的scheduling group,group之间是资源隔离的,保证group之间是公平的。
## 2.3 System Overview
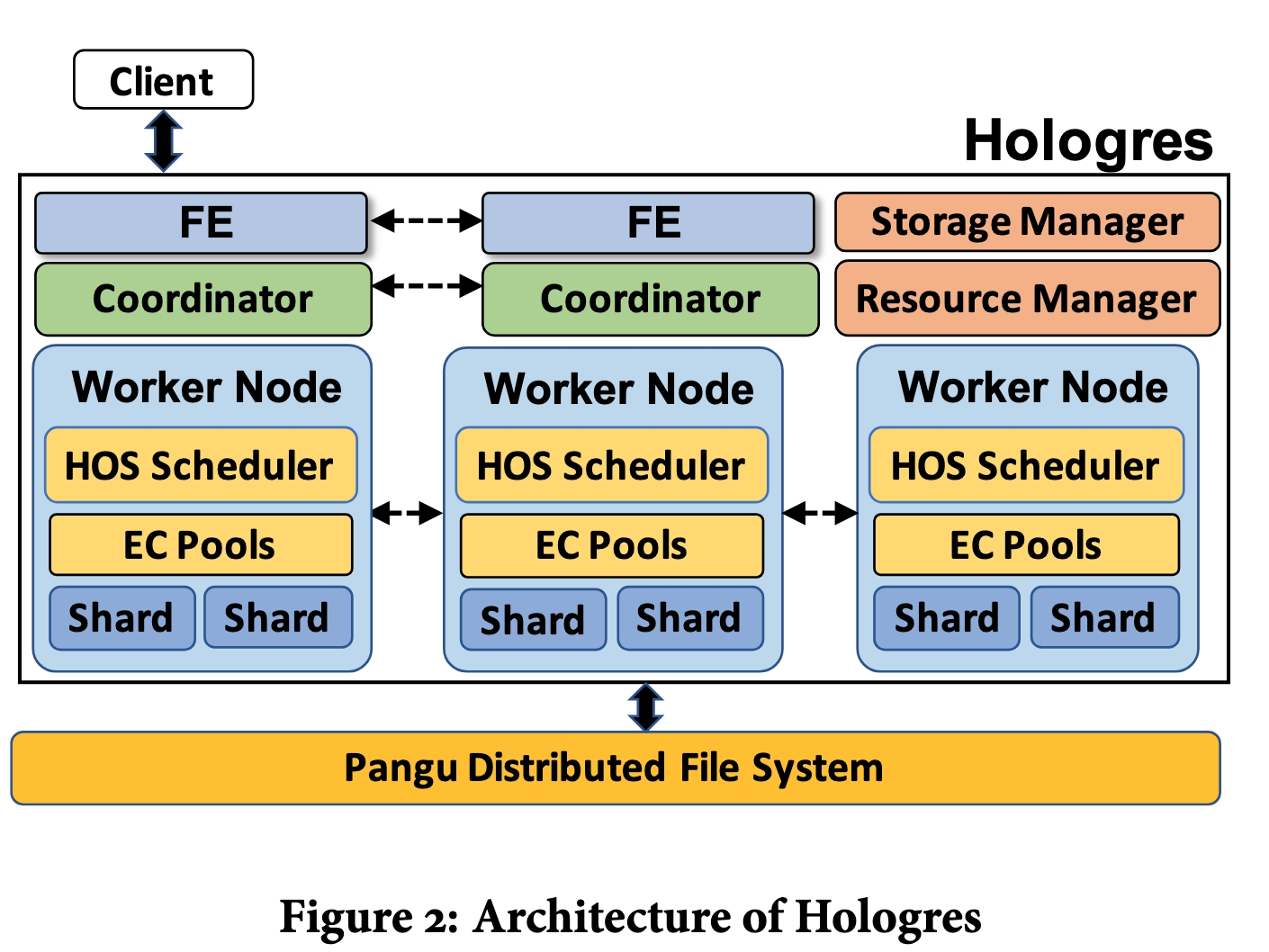
- **FE**:接收查询请求,查询优化生成查询计划(DAG fragment)
- **Coordinator**:将DAG fragment分发给 worker nodes
- **worker node**:物理资源的单元
- **resouce manager**:
- 管理 table group shard的分布。
- worker node上的资源逻辑上拆分为 slots,每个可以分配一个 table group shard
- 也负责worker node 的添加/删除
- **storage manager**:
- 维护 table group shards 的目录和元数据(位置和key范围)
- coordinator 缓存这些 meta 数据。
----------
# 3. STORAGE
- 行列混存,有效支持 HSAP 场景。
- row storage:低延迟点查
- colum storage:高吞吐列扫描。
## 3.1 Data Model
- 每个 table 有一个用户指定的 clustering key,和一个唯一的 row locator。
- 如果 clustering key 是唯一的,可以直接用作 row locator,否则需要加上一个唯一的id来构成 row locator。
- table 由 table groups 构成,table group分片为多个 table group shards(TGS)
- 每个 TGS 包含了每个table部分的 base data以及所有关联的索引。(局部索引),两者都是tablet。
- tablet两种类型:row 和 coumn tablet。
- tablet需要有一个唯一的key。
- base data是 row locator
- 二级索引:区分唯一索引和非唯一索引。
- TGS:可以原子地写入数据和索引。
## 3.2 Table Group Shard
- TGS是数据管理的基本单元。
- 一个 TGS 由一个 WAL manager 和 多个 tablet 组成。
- tablet 是一个 LSM tree。每个 tablet 有自己的memtable 和 shard file。
- records是多版本的,读写可以彻底解耦。
- 写串行,读可以并发。
- 只提供 atomic write 和 read-your-writes 语义。来实现高吞吐和低延迟的读写。
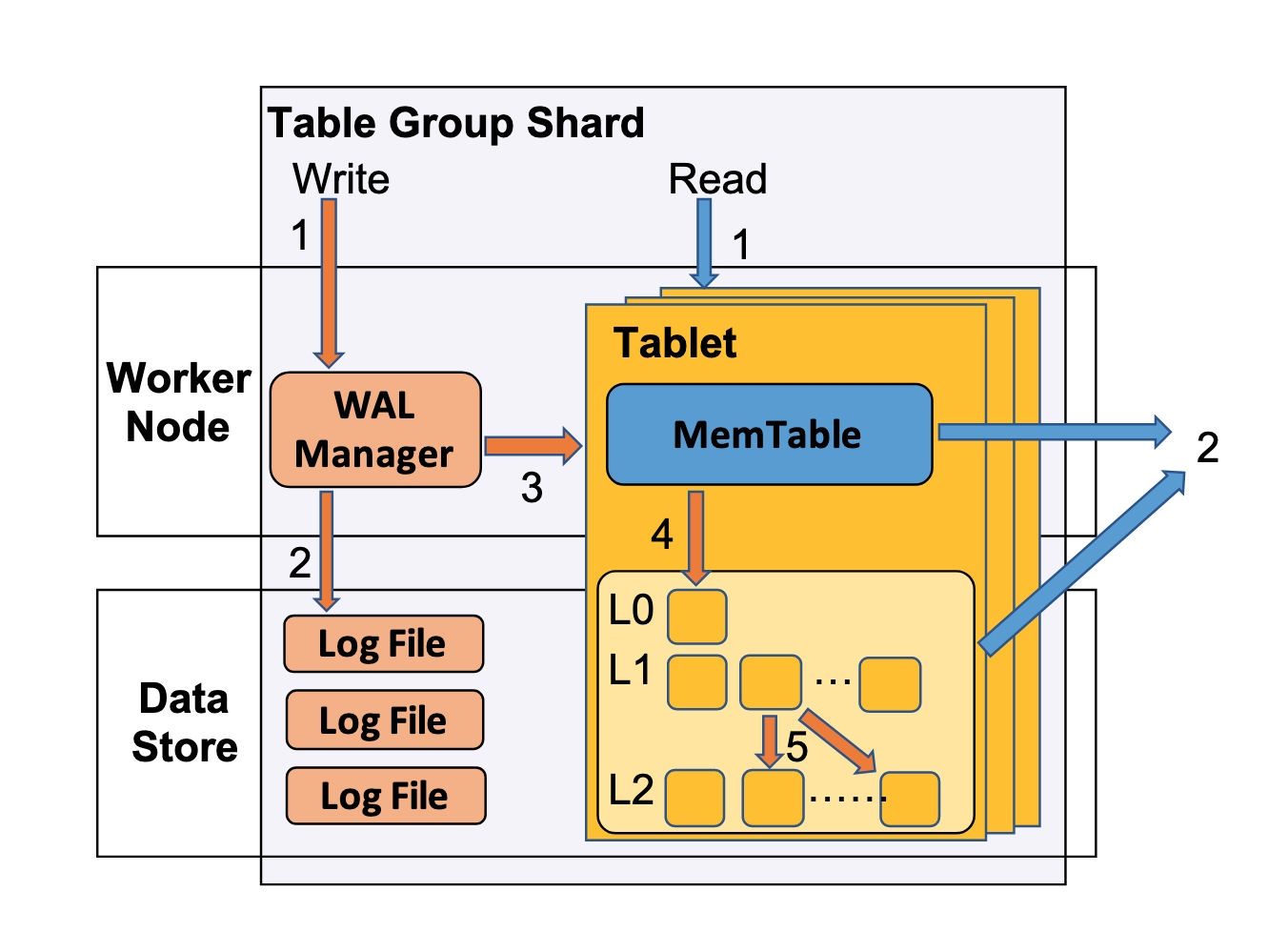
- **Writes**
- LSN包含timestamp和地址的序号。
- single-shard write
- WAL manager分配LSN -> 写日志 ->写memtable
- distributed batch write 2PC
- **Reads**
- read-your-writes
- 每个读请求携带一个 LSN_read
- **Distributed TGS Management**
- 支持迁移TGS(比如负载比较高)和故障迁移
- 进行中:只读副本
## 3.3 Row Tablet

- masstree 作为memtable, 按照 key 排序 records。
- tablet 中的 value:<value_cols, del_bit,LSN>
- value_cols指非key的列。
- 同一个key,memtable 和 shard files中 可以有 LSN 不同的多个record。
- **Reads**:
- 参数:key + LSN_read
- 并行查找 memtable 和 shard files。
## 3.4 Column Tablet

- 一个 column tablet 包含两个组件:
- 一个 column LSM tree
- 一个 delete map
- column LSM Tree 中的 value: <value_cols, LSN>
- memtable
- 以 Arrow的格式存储 records,按照到达顺序追加写入。
- shard file
- records按照key排序,逻辑上组成 row group。
- 每个列的一个row group存储为一个 block。
- meta block
- 每列级别的:data blocks的offset,每个 data block的value范围、encoding schema
- file级别的:compression schema、total row count、LSN和key range
- 按key定位row:index block中存储了每个row groups的首个key。
- delete map是一个 row tablet。
- key:column LSM tree 中 shard file/memtable的ID
- value:bitmap标记哪个record是被删除的
- writes:
- 删除需要先查找该行所在的 file ID 以及文件内的row number。
- 更新=删除+插入
## 3.5 Hierarchical Cache
三层cache:
- local disk cache
- block cache(内存)
- row cache(内存)
---------
# 4. QUERY PROCESSING & SCHEDULING
## 4.1 Highly Parallel Query Execution
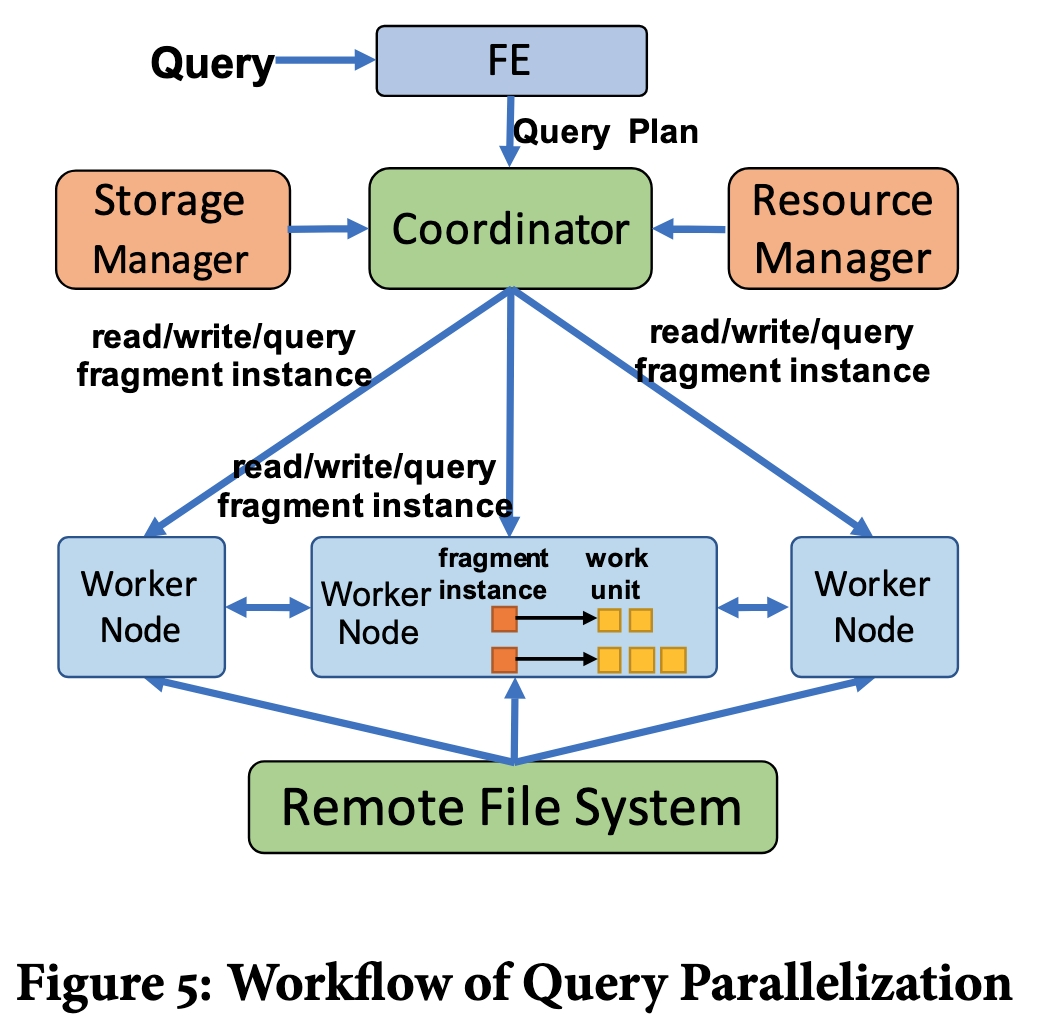
- 按照 shuffle boundaries 将 DAS 拆分为 fragments。三种类型的fragment:
- read
- write
- query
- read/write 只能分派到对应 TGS 所在的 worker node。
- query 可以放到任意 worker nodes 上处理(根据负载情况)
## 4.2 Execution Context
- EC:用户态协程,协作式调度,是 HOS 的基本调度单元。
- 三种EC pool,来做隔离和优先级调度:
- data-bound EC pool: WAL EC 和 tablet EC
- query EC pool
- backgroud RC pool 负责 flush & compact
- Federated Query Execution
## 4.3 Scheduling Mechanism
- Asynchronous Pull-based Query Execution
- Intra-worker pull:函数调用(插入到EC的任务队列)
- inter-worker pull:grpc
- Backpressure & Prefetch
## 4.4 Load balancing
- 两个方位:
- 跨worker-node:TGS迁移均衡
- worker-nodes内线程间:EC重分布
## 4.5 Scheduling Policy
- Scheduling group:分配share,对应赋给它的资源量