#database/olap
# 概述
## 整体架构
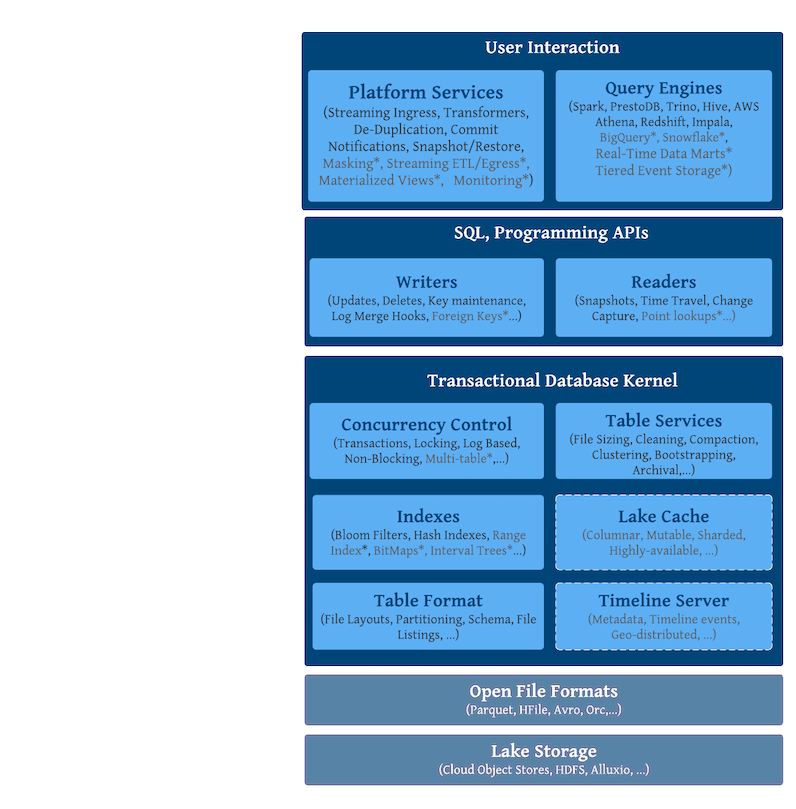
**核心能力:**
- Streaming + Batch API
支持流式写入(CDC、行级别的快速更新能力)和流式读取,实现 incremetant process
- ACID 事务
- 存算分离
- 查询优化(索引和统计信息)
- 开放性:多云支持 + 引擎中立
- time travel
- table 管理:小文件智能处理、数据布局优化等
## 表类型和查询模式
|表类型|支持的查询模式|
|--------|--------------|
|Copy On Write|Snapshot Query + Incremental Query|
|Merge On Read|Snapshot Query + Incremental Query + Read Optimized Query|
两种表类型:
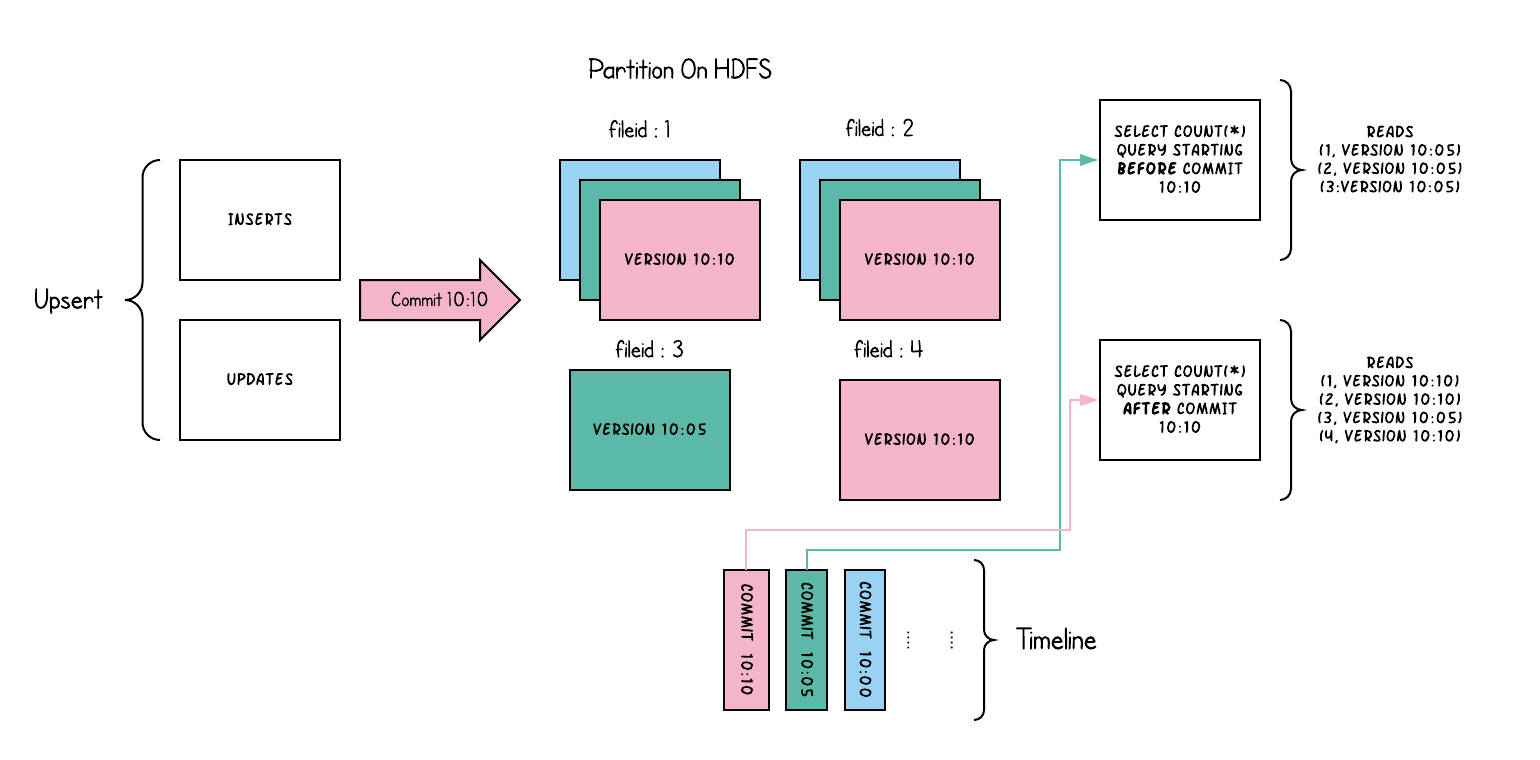
- **Copy On Write** 只有parquet列存文件,写入时同步地跟老数据进行merge重写。
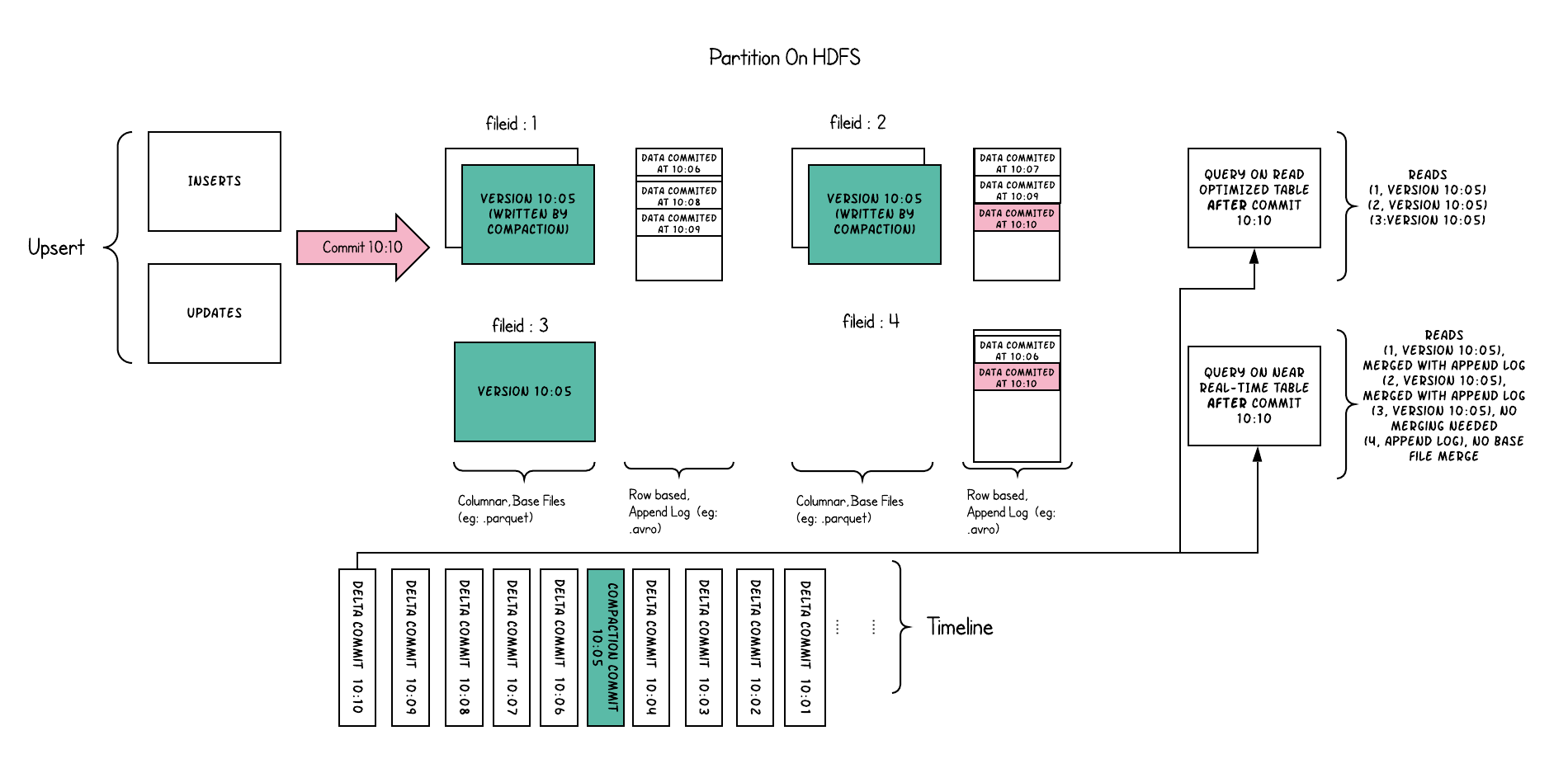
- **Merge On Read** parquet + delta log(行存),更新写入到 delta log,后续再进行合并。
不同表类型的优劣势对比:
| Trade-off | CopyOnWrite|MergeOnRead|
|----------|----------|-------|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
|更新开销(I/O)|高 (需要重写整个parquet)|低 (追加到delta log即可) |
|写放大| 高 | 低 (取决于 compaction 策略) |
不同的查询模式:
- **Snapshot Query**:获取最近的快照进行查询。对于 Merge-On-Read 表,包含了最新提交的 base file + delta logs,并在查询时现场合并(查询延迟比较高)。
- **Incremental Query**:持续地获取从某个时间点之后的新数据,适用于流式场景下。
- **Read Optimized Query**:适用于 Merge-On-Read 表类型,只读取 base parquet 文件(只有列存),忽略 delta logs。查询延迟比较低,但数据新鲜度不够。
COW Table示意图:
MOR **Table示意图:**
## Data Model
Hudi 的每个 table 需要配置主键。
每条写入的记录都有主键唯一标识,Hudi table 的主键由两部分构成:
- record key
- partition_path(可选),控制是全局唯一还是parition级别唯一。
主键的定义是通过指定不同的KeyGenerator来实现的。
Hudu内置了多种 KeyGenerator,也支持自定义的方式。
- **SimpleKeyGenerator**
指定一个字段为Record Key, partition字段也指定一个字段,大部分情况使用该配置
- **ComplexKeyGenerator**
使用多个列组合作为 record key 或 parition paths
- **GlobalDeleteKeyGenerator**
全局索引场景下,主键不需要使用 parition value
- **NonparitionKeyGenerator** 只有一个分区
- **CustomKeyGenerator** 如field_3:simple, field_5:timestamp
- **TimestampBasedKeyGenerator**
字段值转换为timestamp而非string
基于主键的数据模型再配合映射到主键的索引就可以实现:
- 快速的更新逻辑(upsert)
- 去重(记录按主键唯一, parition或global级别)
> 注:主键也可以配置为空,适合于不需要更新和去重的场景。
默认 record key 需要作为一个 meta column(_hoodie_record_key)来存储到数据中的,这样会带来一些额外的空间占用。后续([RFC-21](https://cwiki.apache.org/confluence/display/HUDI/RFC+-+21+%3A+Allow+HoodieRecordKey+to+be+Virtual))Hudi 新增了 Virtual Key 的特性,可以不物理存储 record key(只存储生成方式)。
## Timeline
即 transaction logs,表示不同时间点对一个 table 上执行的不同动作。
Hudi 可以保证每个动作都是原子的。
每个动作(Instant)都有三个属性:
- action:操作类型
- time:一般是个递增的时间戳
- state:instant 当前的状态
关键的动作类型:
- COMMITS:原子写入
- CLEANS:后台活动,清理不需要的旧版本文件
- DELTA_COMMIT:MOR table 原子写入
- COMPACTION:后台活动,将 log 合并到 base
- ROLLBACK:回滚一次 commit/delta commit
- SAVEPOINT:标记某些 file group 为 saved,cleaner不会删除它们。用于灾难恢复
每个动作都有三种状态:
- REQUESTED:操作已经被调度,还没开始
- INFLIGHT:正在执行
- COMPLETED
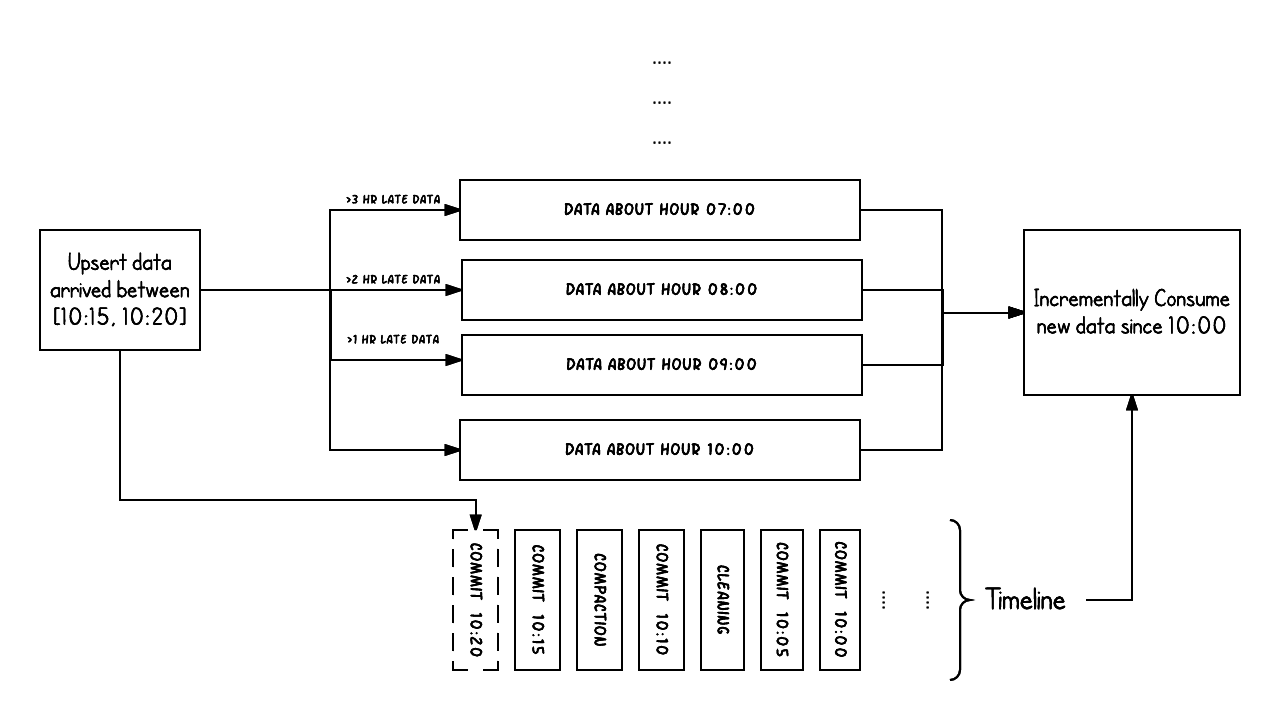
Hudi 基于 Timeline 来实现 MVCC + Incremental Processing 的能力。
## File Layouts
一个表的数据包含了数据文件和hudi内部的元数据文件(.hoodie文件夹)。
数据文件组织的级别:
table -> parition -> file group -> file slice -> file
1. 整个 table 的数据存储在分布式文件系统中的一个 base path 下
2. table 又拆分为多个 partition(不同子目录)
3. 一个 parition 内又分为多个 file group,不同group之间的数据不重复
4. 一个 file group 内又有多个 file slice,一次提交/Compaction产生一个 file slice(MVCC下的一个新版本)。
5. 一个 flie slice 包含一个 base file(parquet) + 多个 log files。
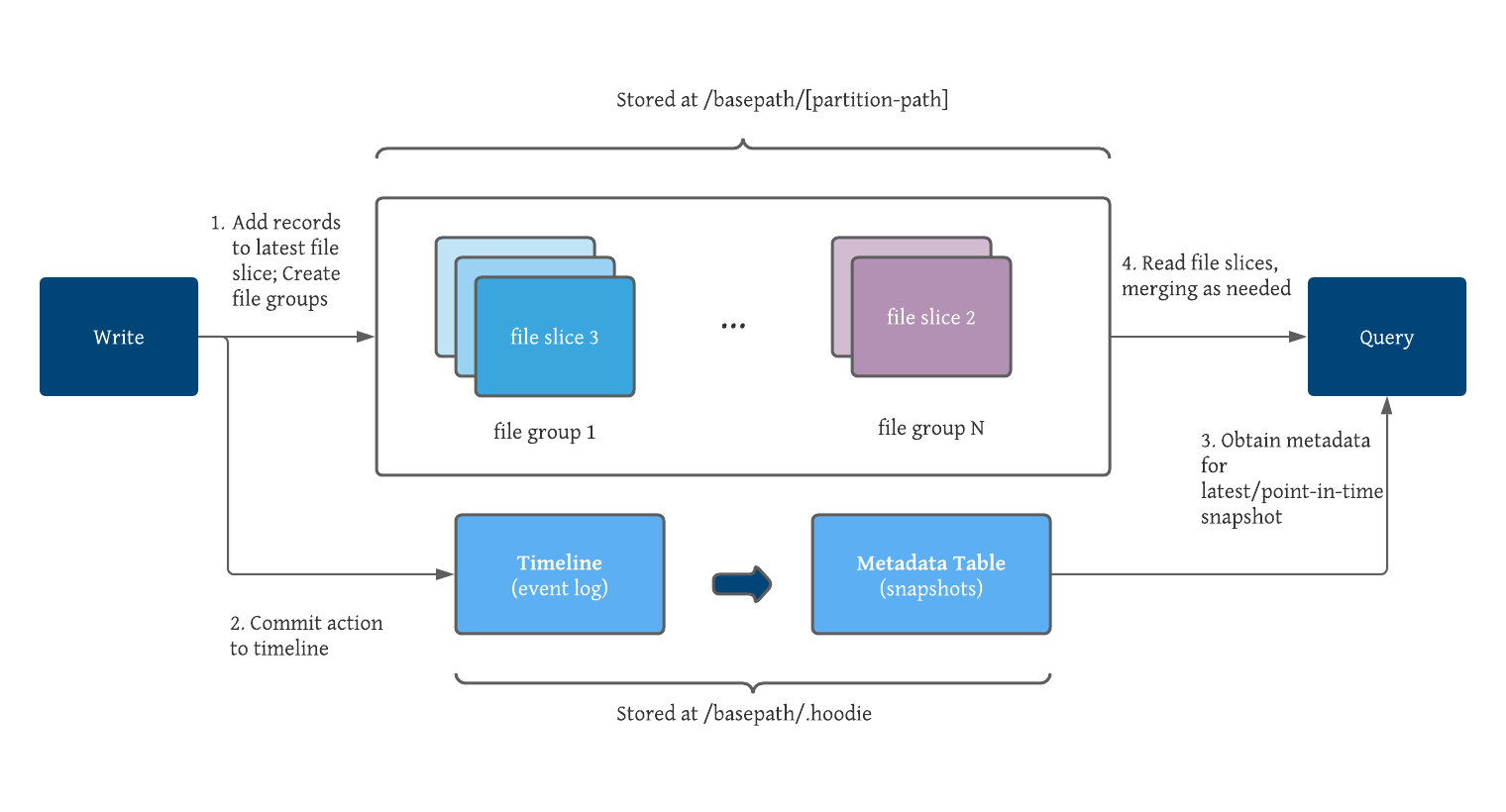
# Metadata Table
Metadata Table主要意义:不需要执行昂贵的 list files 操作。
Metadata table 是一个 internally-managed hudi table,位于 base path 的 _.hoodie/metadata_ 目录下。
Metadata table 是一个 merge-on-read 类型的 table。
与用户 table 的区别是 Metadata table 的 base file 是 HFile 格式,索引以 Key value 的形式存储,来支持快速的点查和范围扫描。
Metadata table 包含了文件列表等元数据以及索引数据。
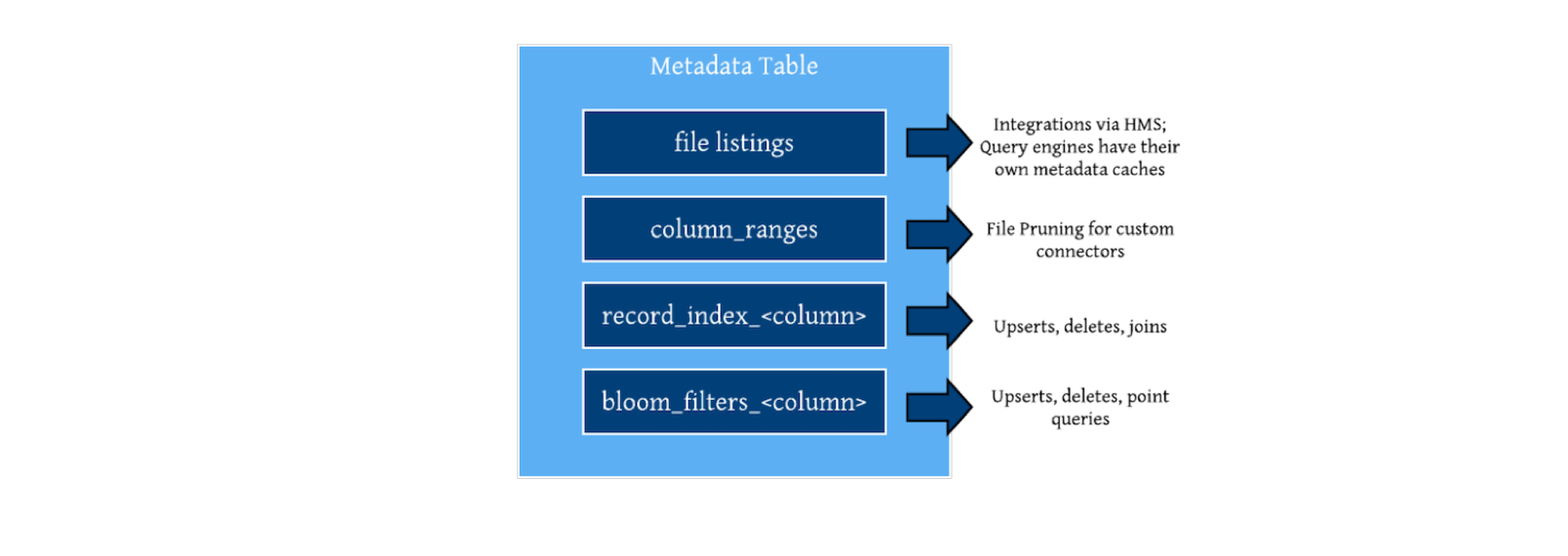
索引数据以单独 partition 的形式存储在 metadata table 中。

## 主键索引
主键索引是映射 hoodie key(record key + partition_path)到 file id,来高效支持 upserts操作。
对于 MOR table,有了主键索引后,merge也可以变得更高效。
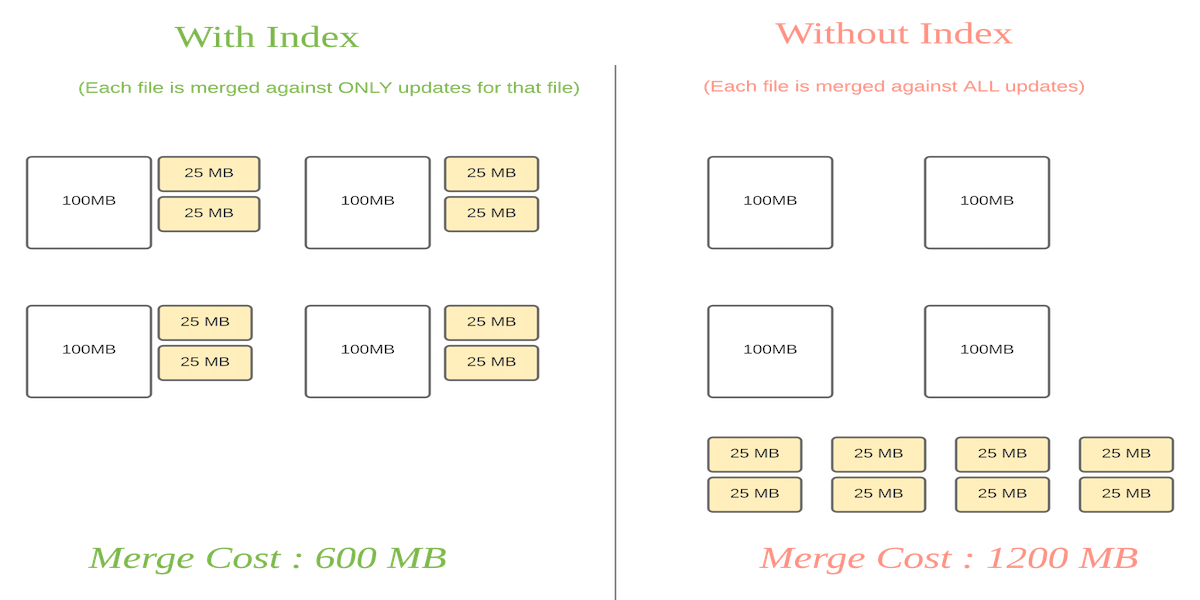
**主键索引类型**
- Bloom Index(默认)
使用 bloom filter + record key ranges(可选,interval tree)来有效过滤文件
过滤后再从候选文件中读取确认(处理 upsert 时)
- Simple Index
直接从文件里读
- Hbase Index
使用外部 Hbase 来存储索引(需要处理两部分数据的一致性)
- 用户自定义
**Global vs Non-Global Index**
• Global index
能保证 key 在所有分区都是唯一的
• Non Global index
默认实现,分区内的索引
## Column Stats Index
包含了所有列的统计信息,可以根据列值作 file pruning,来提升查询效率。
列统计信息示例:

# 并发控制
即处理读、写、内置异步table service(Hudi后台任务)之间的并发问题。
## Read-Write
Atomic Write (基于事务日志)+ MVCC 来处理读写之间的并发,提供了快照隔离的语义。
读写操作可以同时进行,并保证可以读到最新的完整数据(no partial-write)。
## Single Writer + Inline Table Service
写入过程同步执行 table service (compaction、clustering等),该场景下完全没有并发。
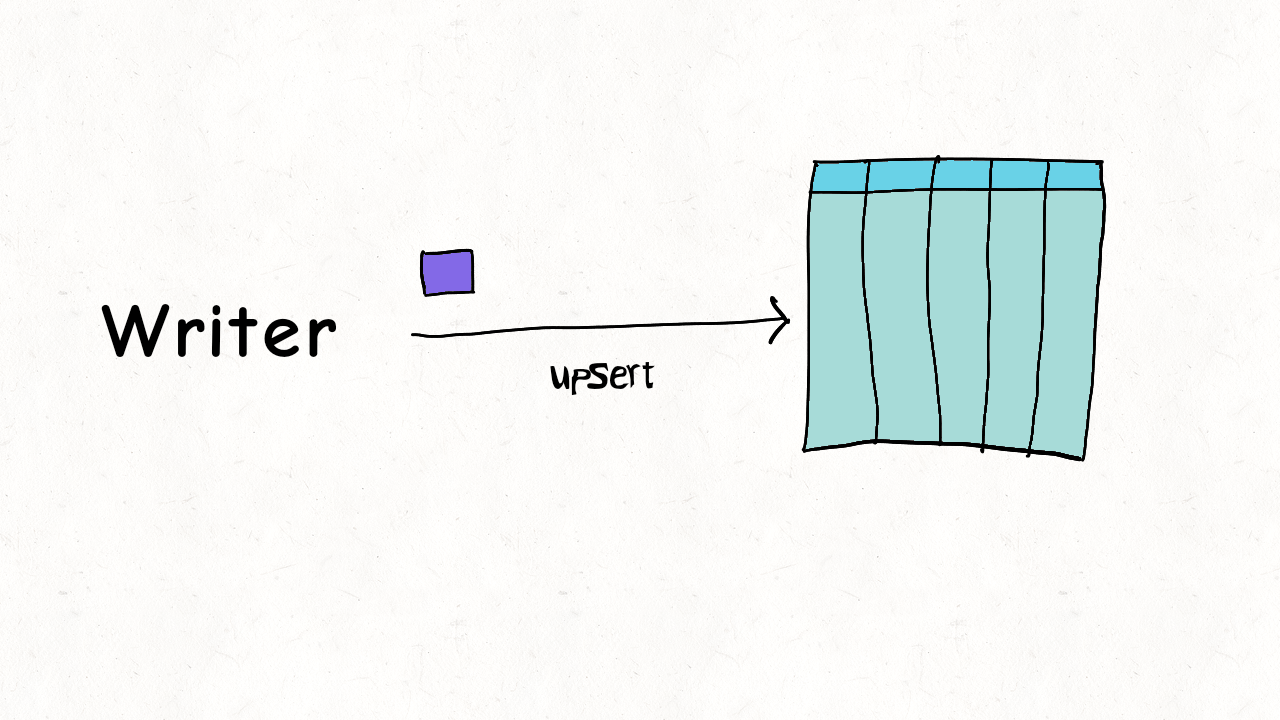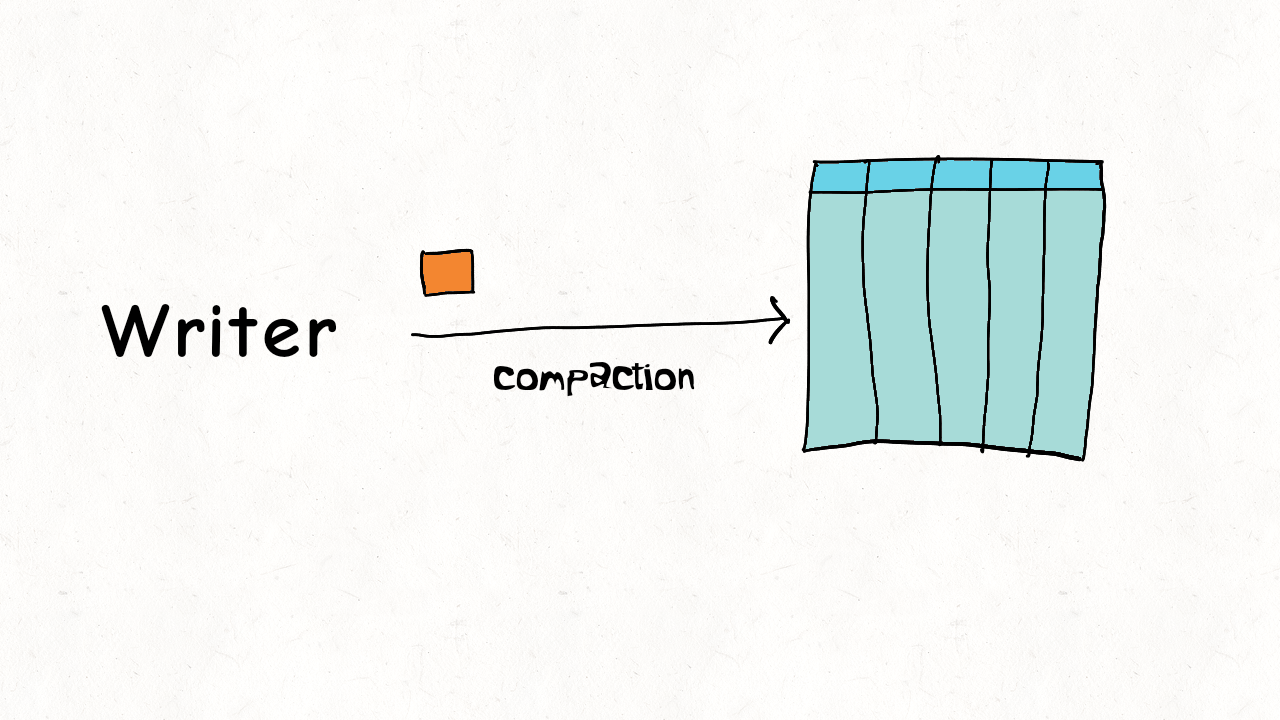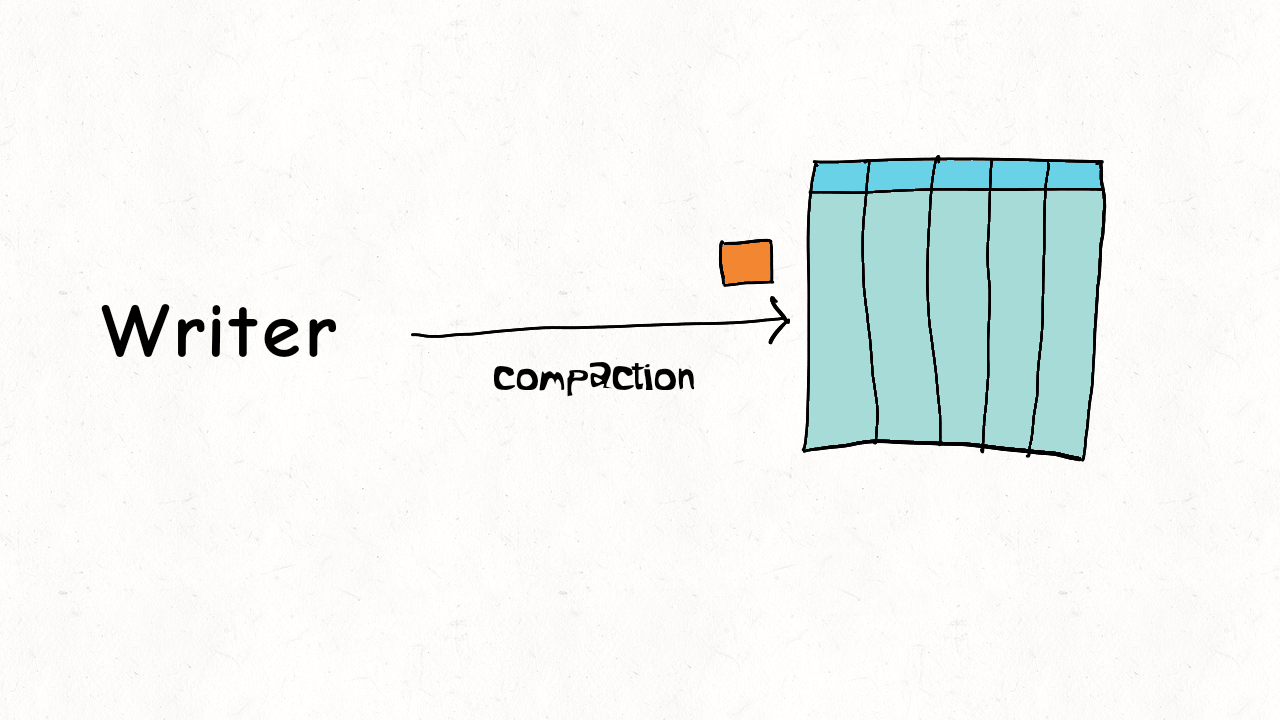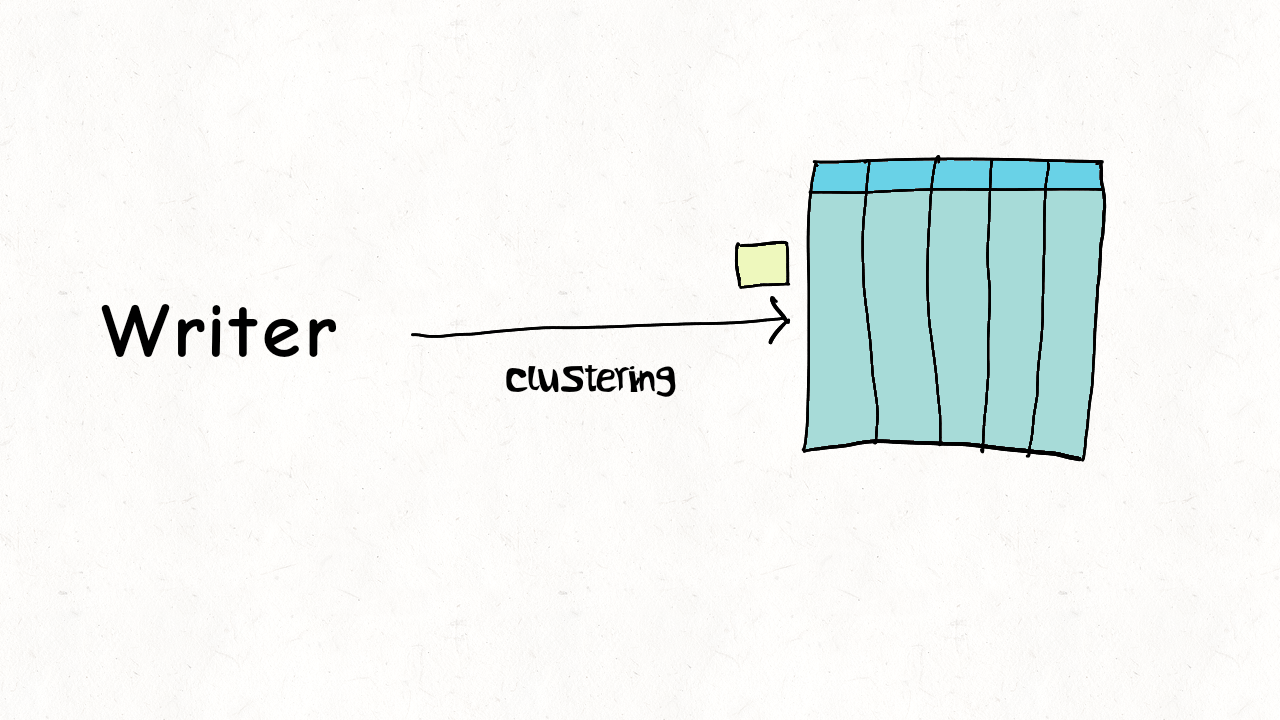
## Single Writer + Async Table Service
写入跟 table services 之间存在并发。
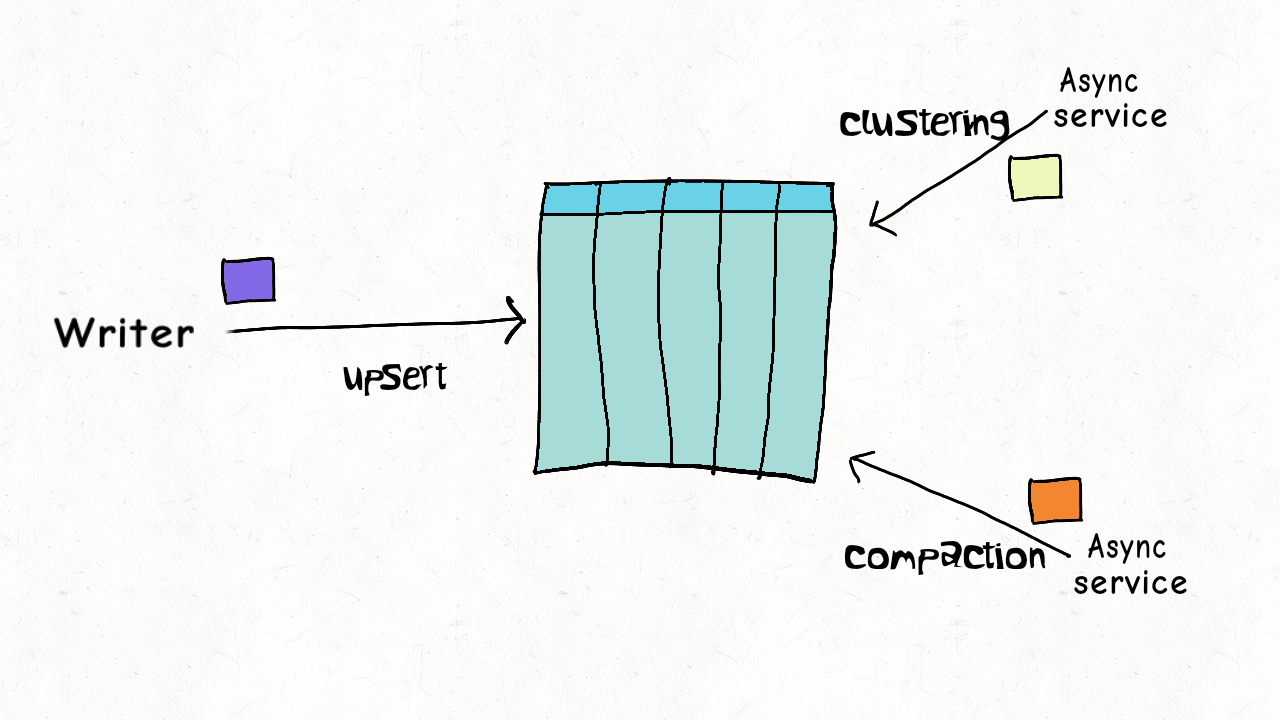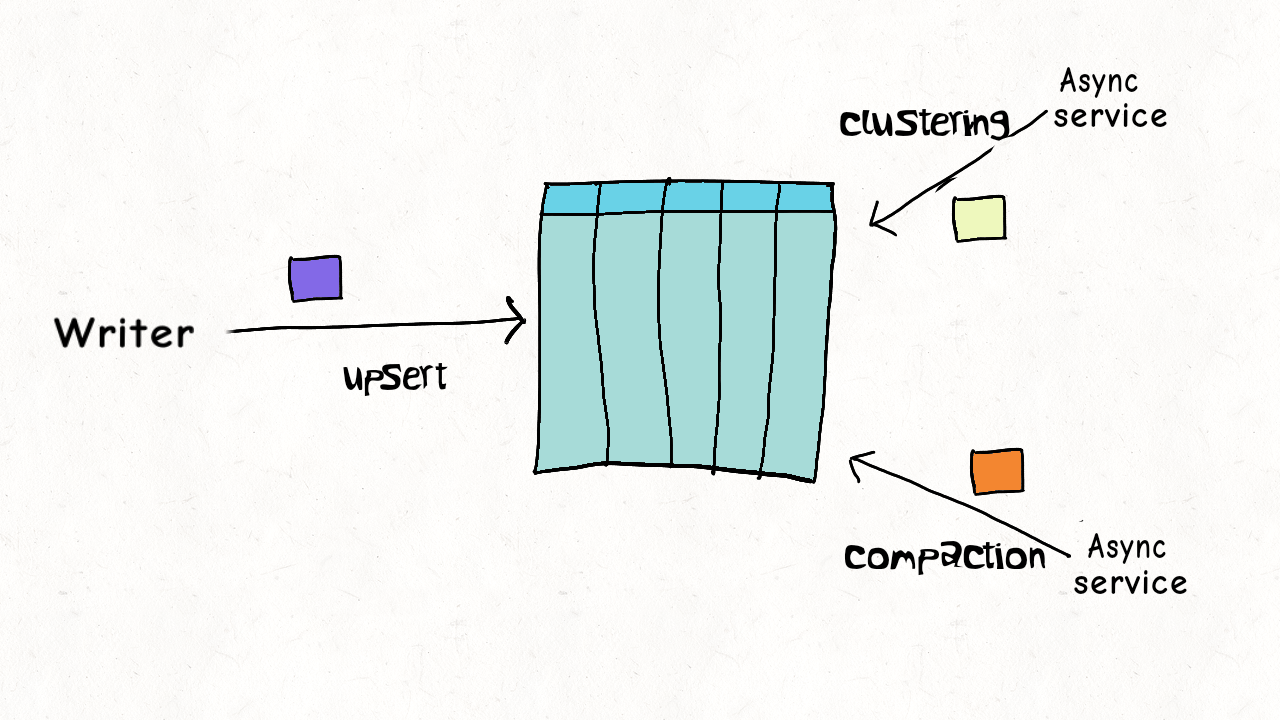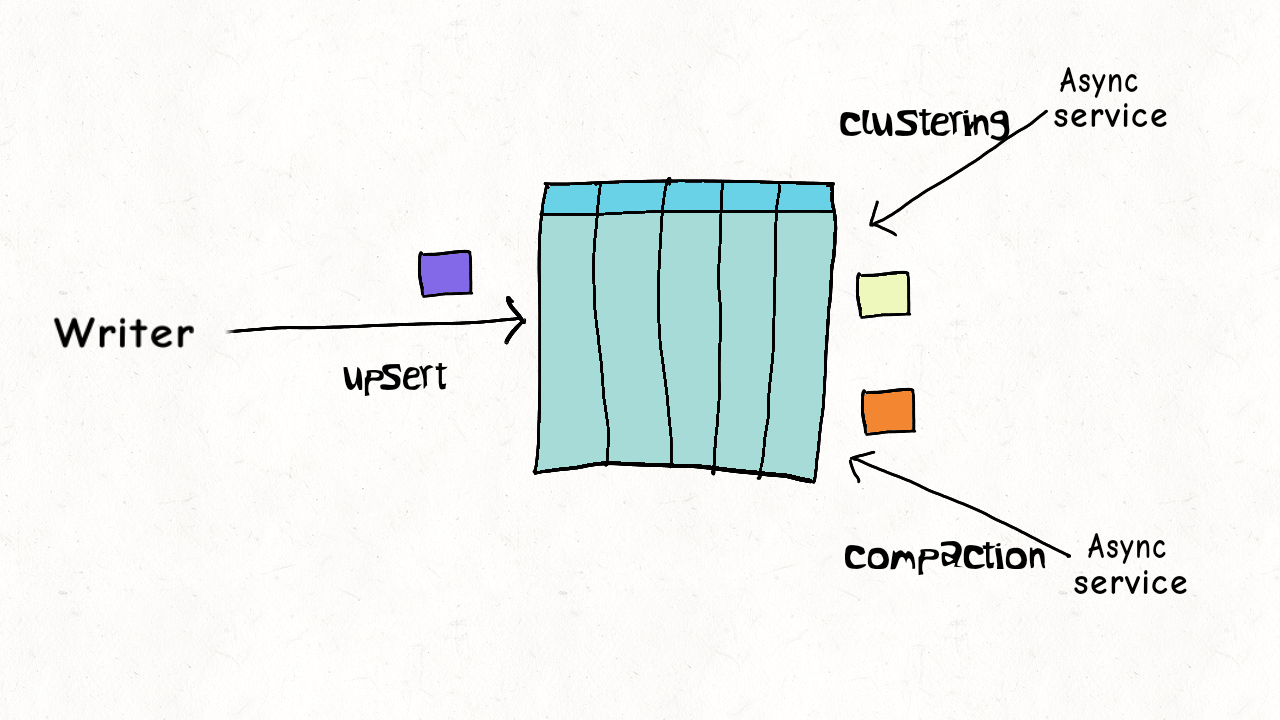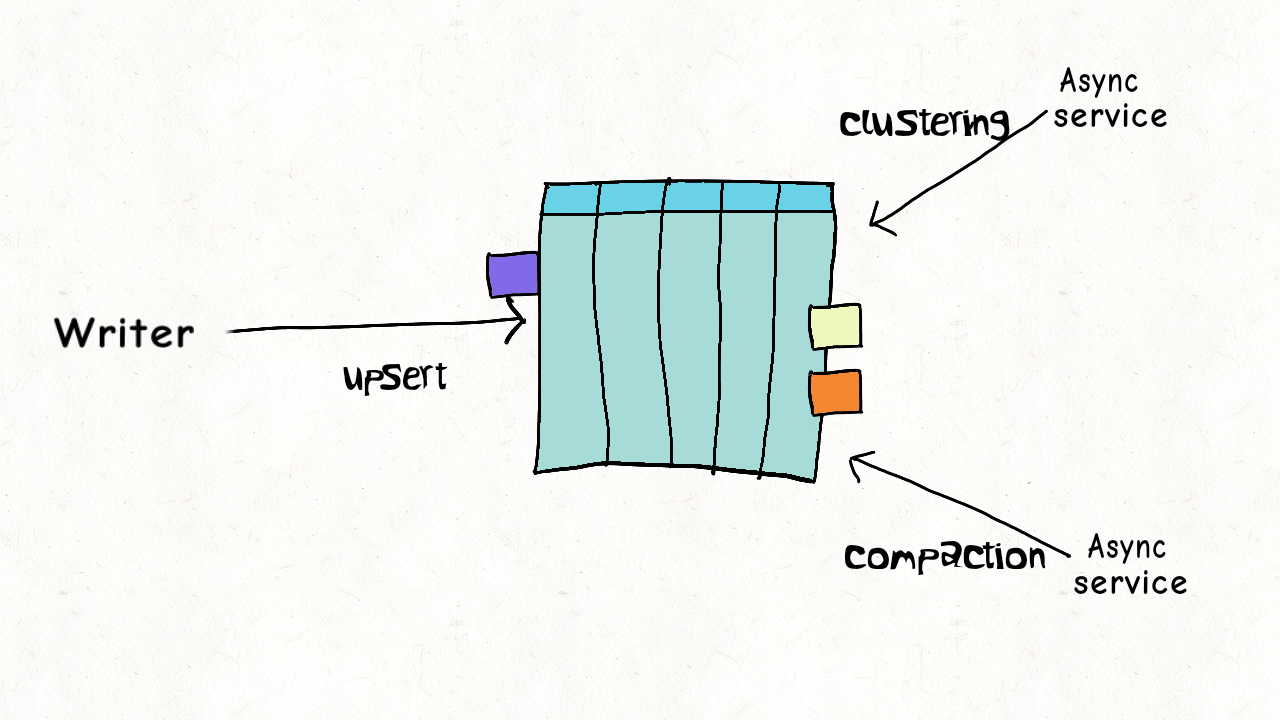
数据之间没有并发(比如compaction,处理都是已提交的数据),资源上存在并发。
根据不同的 table service 作简单的并发控制。例如 delta log 如果正在被 compaction,则不能继续写入,需要生成新 log 文件来服务写入。
## Multi Writer
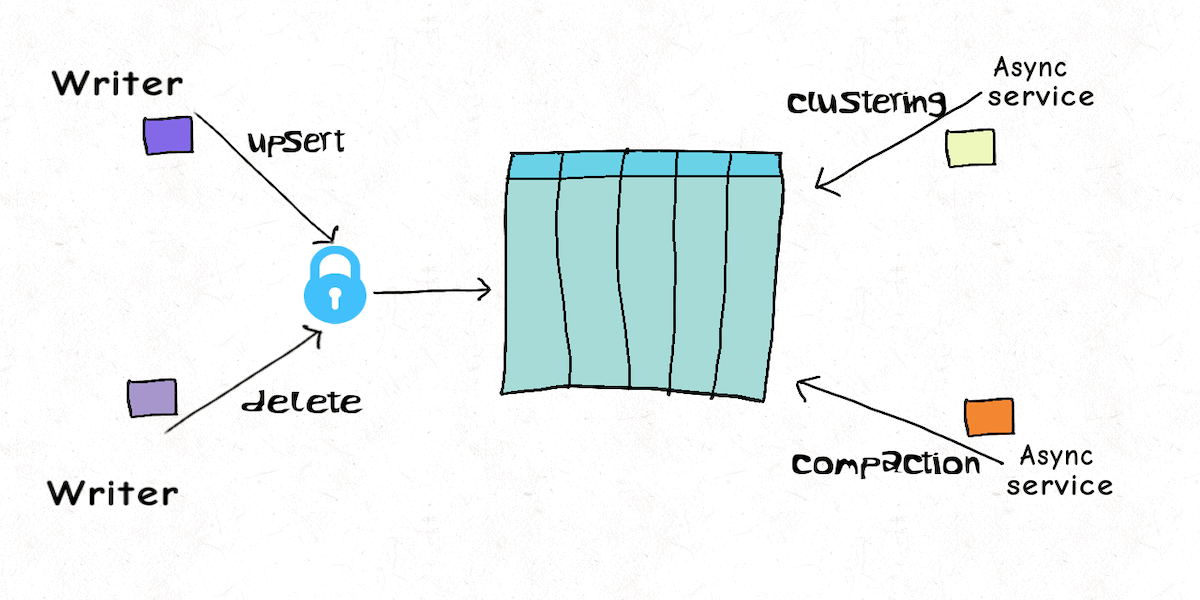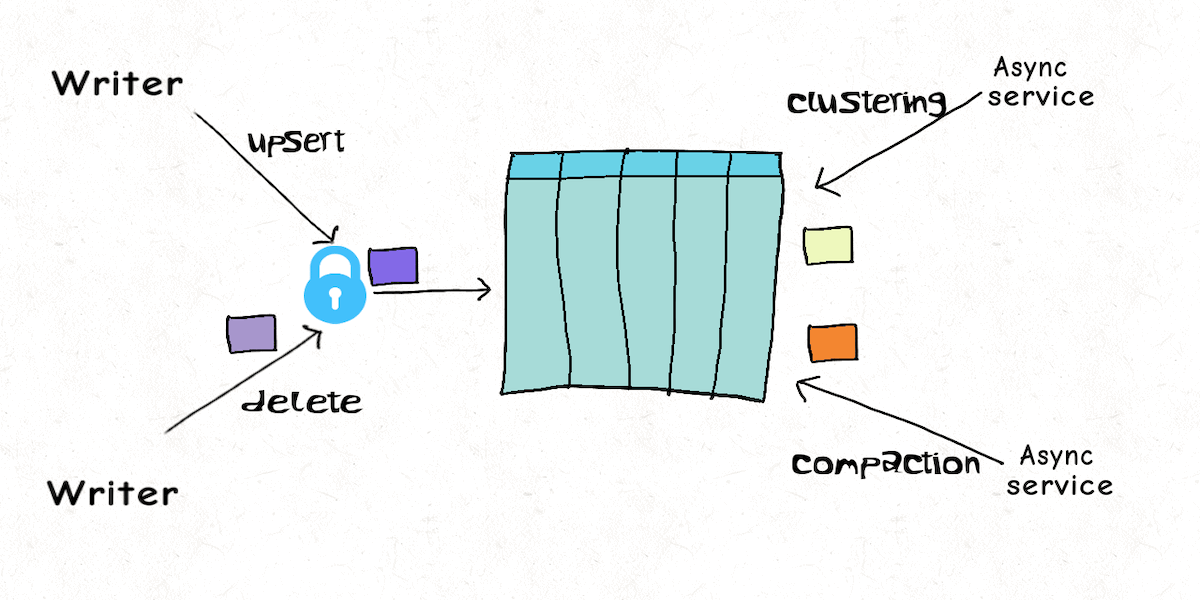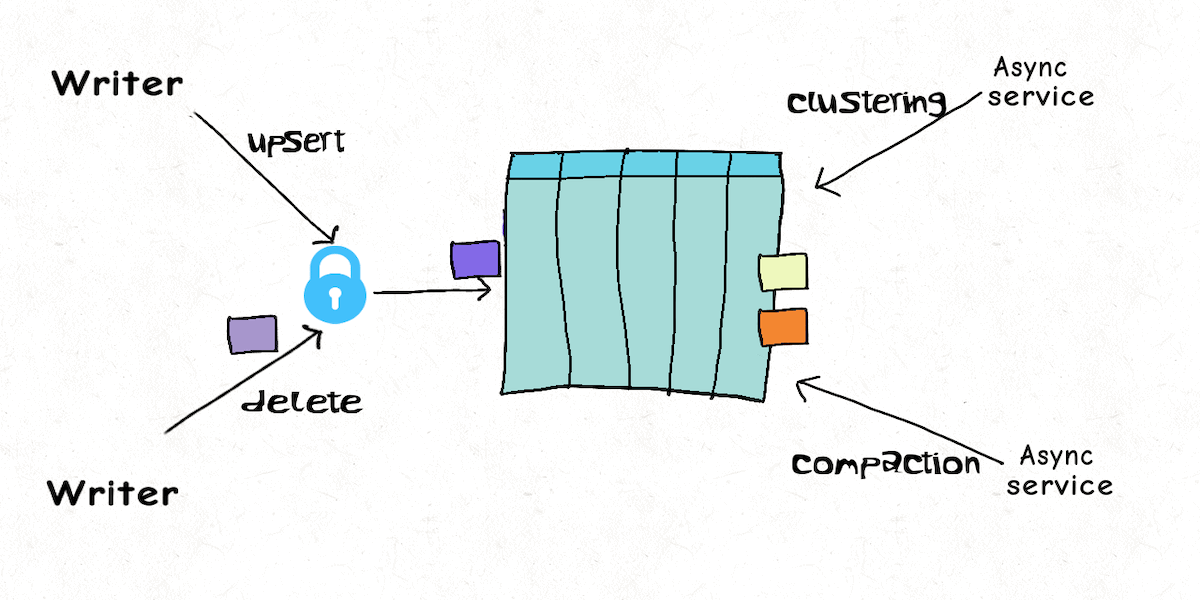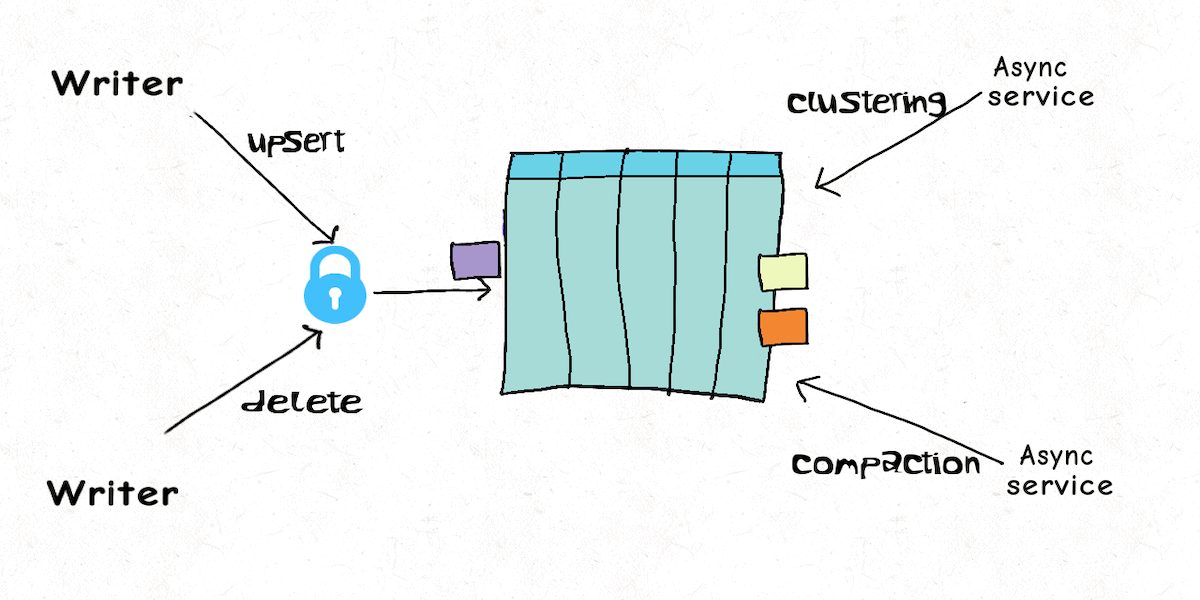
并发控制手段:File-Level(file group) Optimistic Concurrency Control
写入前期不加锁,commit 阶段加锁(表级别的锁,由 lock provider 提供)。
commit 时先检查写入期间涉及的文件是否发生更改,是的话就中止本次写入。
> 注:写文件时仍然需要加 file group 级别的悲观锁
如果不同的Writer写入的数据不相关,则性能会比较好。
开启OCC需要配置 lock provider(四种之一):
- File system hoodie.base.path+/.hoodie/lock,并配置过期时间
- Zookeeper
- HiveMetastore
- Amazone DynamoDB
**OCC优化**:
- Writer增加心跳机制,定时跟踪写入哪些文件,及时检测冲突,尽早中止,避免造成资源浪费
- 优先终止开始时间晚的任务,对 long-running 任务更友好(long-running 任务的回滚代价高)
- 如果 Multi Writers 来自同一个 JVM client,使用进程内的锁,不需要使用外部锁
**Multi Writer Gurantees:**
- UPSERT:数据无重复
- INSERT:数据可能会重复,即使开启 dedup 选项。
- BULK_INSERT: 可能会重复,即使开启 dedup 选项。
# 读写流程
## Read
大致流程:
1. 从 Timeline 上挑选时间点(最近成功 commit version 或者 查询中指定的 commit version)
2. 读取指定时间点的 metadata table,获取对应的数据文件列表,并根据索引和统计信息过滤文件(file pruning)
3. COW表类型:从目标parquet文件扫描记录获取数据
MOR表类型:将 delta logs 加载到 _spillable map ,_读取到 parquet 文件中的每条记录后,需要检查 map 中是否有更新的数据。
## Write
Hudi支持的写入方式:
**增量写入**
• insert 不查找索引来判断数据是否存在
• upsert 需要查找索引
• delete
**批量写入**
• insert_overwrite 重写input里涉及的所有 parition
• insert_overwrite_table 重写整个表(只删除元数据,后续靠Cleaning来删除数据文件,速度更快)
• delete_parition
• bulk_insert 适用于初始化时导入数据,比 upsert 更高效(没有写入时File Sizing,对输入进行排序避免的同时写多个文件)
**upsert 写入大致流程:**
1. 开启写事务
2. 输入数据先在内存中去重
3. tag:从当前数据中按主键查找,判断是 insert 还是 update,定位目标 file group,对旧数据的更新写入旧数据所在 file group;新数据写入新的file group(不考虑 filesizing)
4. 数据合并或者写入 delta log
5. 索引维护
6. 提交事务
# Table Service
## Compaction
适用于Merge-On-Read表类型,将 delta logs 与 base file 合并生成新的 base file,提升查询性能。
compaction默认是在后台异步执行。异步compaction整个过程分为两步:
1. 任务生成: 由 ingestion job 负责,扫描分区、挑选需要 compact 的文件,并将 compaction plan 写入 Hudi timeline
2. 任务执行:读取 compaction plan 并执行
compaction 不同的执行方式:
- 异步执行:默认在 spark streaming job、 DeltaStreamer Continuous Mode(CDC同步)下自动异步执行。
- 同步执行:可配置为写入时同步执行(比如某批数据写入后,想马上提升查询它的性能)
- 手动触发:手动向 Spark/Flink 提交任务,或者通过 Hudi-CLI 命令行工具进行离线的compaction。
## FileSizing
大量的小文件将会导致很差的查询分析性能,因为查询引擎执行查询时需要进行太多次文件的打开/读取/关闭。Hudi提供了 FileSizing Service 来解决小文件的问题,主要是采取了两个措施:
- 写入时:避免小文件的生成
- 写入后:提供 Clustering 特性将小文件进行合并
### 写入时(Auto-Size)
新数据写入时(数据不存在),不优先创建新的 file group,而是查找已有的较小的file group,追加到其后。
例如:小文件阈值为100Mb,则当前 File_1,File_2, File_3都为小文件:

写入时新数据优先追加到小文件上:

小文件填充完后,再创建新的 file group:

**缺点:**
- 开销发生 ingestion 期间,影响写入速度
- 如果数据文件上有其他任务在进行(如compaction),则无法进行
### 写入后(Clustering)
[RFC-19](https://cwiki.apache.org/confluence/display/HUDI/RFC+-+19+Clustering+data+for+freshness+and+query+performance)
跟 ingestion job 脱离,不影响 ingestion的速度。
与ingestion job并行地执行,同步或在后台异步地将小文件合并为大文件(合并多个小 file group)。

**缺点:**
同一个file group,clustering和更新操作无法同时执行(未来会支持)。
默认配置下,一个 file group 如果正在执行 clustering 动作 ,则无法对该 file group 进行更新操作。
也可以配置有更新时,回滚 clustering 操作。
## Clustering
clustering 除了包含异步 FileSizing 功能外,还支持对数据文件进行布局上的优化,基于 [Z-Order 和 Hilbert Space Filling Curves](https://hudi.apache.org/blog/2021/12/29/hudi-zorder-and-hilbert-space-filling-curves/) 实现多字段排序,达到更好的数据局部性以及更强的 data-skipping 能力(结合相关的z-order索引)。
## Cleaning
清理没有被使用的旧版本文件来回收存储空间。
关键的配置:
- **KEEP_LATEST_COMMITS** 保留最近N次 commit 的历史版本
- **KEEP_LATEST_FILE_VERSIONS** 为每个文件最多保留多少个版本
- **KEEP_LATEST_BY_HOURS** 基于时间做清理
cleaning会影响 time travel 功能,需要考虑与 storage cost 之间做一定的权衡。
## Data Quality
写入时校验数据
## Transforms
写入时对数据进行一层转换后再写入到 Hudi。
# 生态
## 多云支持
Hudi 支持的云对象存储:
- HDFS
- AWS S3
- Google Cloud Storage
- Alibaba Cloud OSS
- Microsoft Azure
- Tecent Cloud Object Storage
- IBM Cloud Object Storage
- Baidu Cloud Object Storage
- JuiceFS
- Orace Cloud Infrastructure
## 查询引擎支持
### Read Support
- Apache Flink
- Apache Spark
- Apache Hive
- Apache Impala
- Athena
- Databricks Spark
- Presto
- RedShift
- Trino
- Doris/StarRocks
### Write Support
- Apache Flink
- Apache Spark
- Apache Impala
- Databricks Spark
# Ongoing & RoadMap
- fully lock free事务(基于日志、 crdt等)
- Cache
- [Consistent Hashing Index](https://github.com/apache/hudi/blob/master/rfc/rfc-42/rfc-42.md)

- [Record Level Indexing](https://cwiki.apache.org/confluence/display/HUDI/RFC-08++Record+level+indexing+mechanisms+for+Hudi+datasets)

- Secondary Index
- 生态:BigQuery集成、Kafka connect sink等
# 总结
## Hudi特点
- 功能丰富,且高度可配置化(多种表类型、有无主键等)、可扩展(可插拔的索引模块、主键函数等),能够覆盖非常多的应用场景
(Hudi 有500多个不同的配置项)。
- 索引模块能够很好地支持更新操作
- file group 是一个比较核心的设计,可以实现按数据量作切分,分而治之,不同的 file groups 可以并行处理,相互不影响。
## 与 LSM 模型对比
- **对有序数据集的支持**
LSM 对有序数据支持地更好,因为数据在物理上是整体排序的。
- **场景一**:range scan操作 如查询主键的一段连续区间,LSM能快速定位到目标文件,且读取的数据在磁盘上是连续的。而 Hudi 可能需要读取多个 file group。
- **场景二**:查询一组完全随机的 uuid ,完全无序,LSM会命中较多的数据文件。而对于Hudi,由于数据写入和访问一般具有时间上的局部性,有可能只会命中最新的几个 file groups。
同理,当更新一组随机 uuid 时,LSM下该更新会与非常多的旧数据文件重叠,导致compaction的开销很大
- **写入开销**
LSM写入和compaction时有排序的开销。Hudi没有,写入吞吐会更大,但merge的效率会低(内存占用也比较大)。
- **更新延迟**
- LSM可以做到更低的更新延迟。
- Hudi需要先定位 file group(尤其 file group 较多时,极端情况下 key range 失效时需要检查每个 file group的索引,并且 bloom filter 的误判率也会变高,检查完索引后还需要文件里确认)。
- **数据规模**
- Hudi基于 file group 按数据量做切分(一个 file group 在百兆级别) ,每个 file group 是自治的,可以独立 compaction,能支持更大的数据规模。
- LSM支持较小的数据规模。当数据量变大时,一次 compaction 的开销会很大。利用 bucket lsm 可以缓解,但需要用户定义分桶策略,以及可能会存在数据热点、分布不均匀的问题,每个bucket的数据量也比较难限制。
- 另外存储模型的选择,可能也与技术演进路线相关。比如Hudi 最初的起点是 HDFS + parquet files,再演进出事务性地COW(此时仍然只有parquet文件),以及后面率先提出 MOR table、索引等。
## 与传统数仓对比
Hudi 只负责存储层,是引擎中立的,互操作性和生态更好,一份数据可以支持多个业务(可能使用不同引擎)的读写,能够节省成本。
Doris等传统数仓,查询引擎是定制的,底层存储可以暴露更多的细节给上层查询引擎,有更强的查询优化能力,生成更高效的查询计划,从而达到更好的查询性能。