#database/olap
# Overview
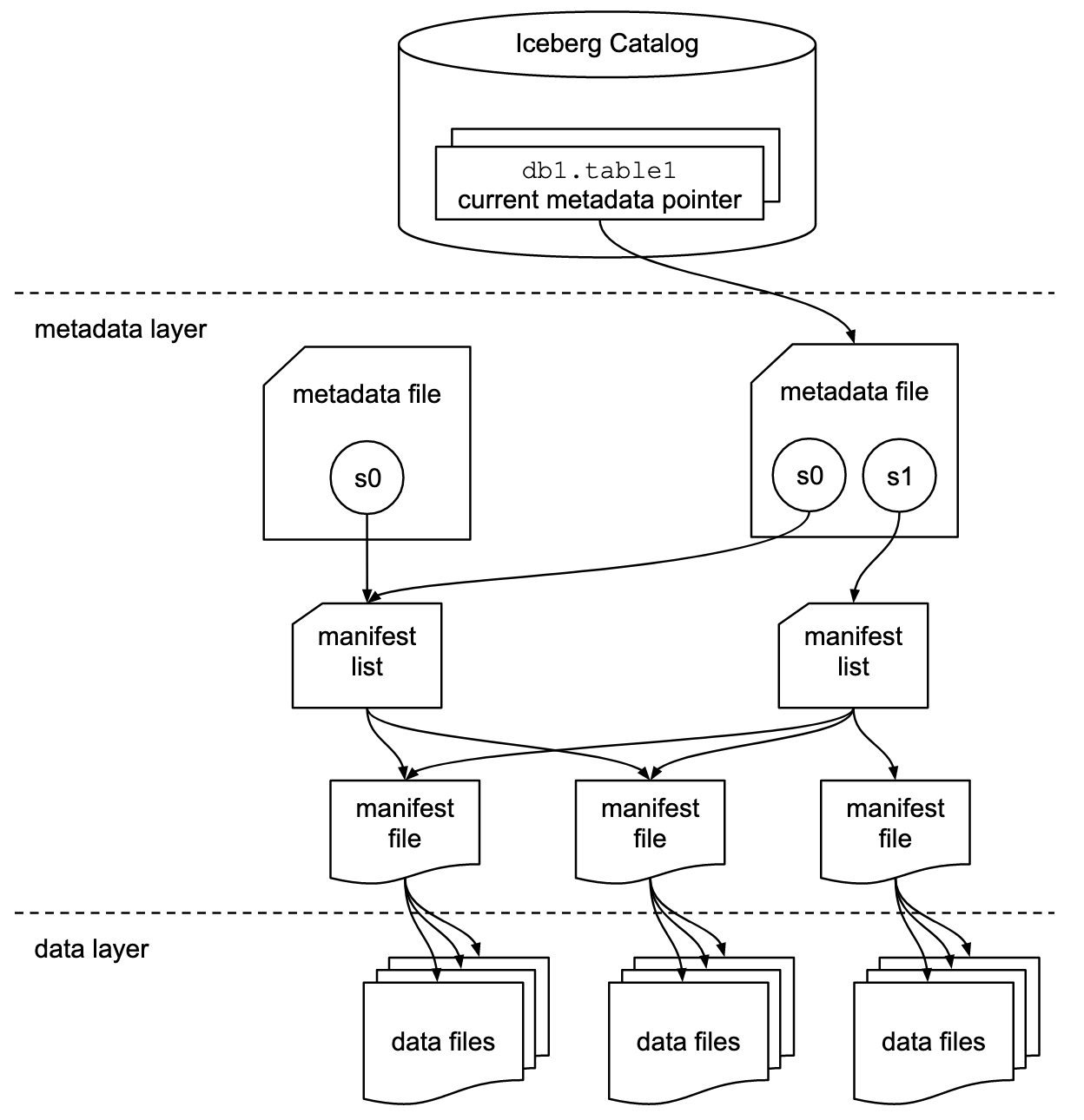
Table state:存储在 metadata 文件中。
metadata:
- table schema
- partition config
- custom properties
- data snapshot
对 table 的每次修改都会创建一个新的 metadata file 原子性地替换旧的。
manifest:存储分区内有哪些数据文件。一行一个文件。
mainfest list:对应一个 snapshot,存储 snapshot 里有哪些 manifest。
## Optimistic Concurrency
核心是 commit 时做 metadata file 的 atomic swap。
冲突:基于最新版本重试。
有些操作可以支持直接重放 metadata 变更。
## Sequence Numbers
文件带有序列号(data & delete files),来区分新旧。
## Row-level Deletes
两种方式存储删除数据:
- Position deletes:标记删除了哪些行(data file path + row position来确定)
- Equality deletes:按列值相等条件删除(如 id = 5)
列统计信息可以用来判断 delete file 是否和 data file 或者 一个 scan range 重叠。
## File System Operations
只需要文件系统支持以下操作:
- In-place write 文件写完后iceberg不会再进行move或修改
- Seekable reads
- Deletes
# Specification
术语:
- Schema
- Parition spec
- Snapshot:table 在某一个时间点的 state(包含所有数据文件)
- Manifest list:每个snapshot一个
- Manifest:存储 data & delete files 的列表,snapshot的子集
- Data flie:
- Delete file:
## Schema and Data Types
支持 struct、list、map等嵌套类型。
每个schema 对应一个唯一的 scheme ID。
每个列有一个 field id。
reserved field IDs:
- _file
- _pos
- _deleted
- _spec_id
- _parition
- file_path
- pos
- row
## Partitioning
支持按某些列作分区,也支持复杂的 transform从记录中生成 parition value。
Manifest中存储了每个 data file 的 parition values,Scan时可以快速过滤文件。
table通过配置 partition spec 来定义如何从 record 中生成 parition values。
## Partition Evolution
Table partitioning支持添加、删除、重命名或者reorder parition spec fields。
## Sorting
在分区内按某些规则对数据进行排序,来提升性能。 在 manifest 中,一个 data/delete file通过 sort order's id 来关联一个 sort order。
# Manifests
immutable Avro file,保管了所有的 data files 或者 deleta files 列表,每个 file 的 parition data tuple、metrics等。
Manifest 是一个合法的 Iceberg data files。
data files 和 delete files 的 manifest 文件是分开的。
Manifest 跟 partition spec 是绑定的,partition spec变更会重写 manifest。
Manifest 中存储了 parition spec,和 其他的 metadata(以 KV格式)。
| Key | Value |
| ----------------- | -------------------- |
| schema | json格式,table的schema |
| schema-id | schema id,string类型 |
| partition-spec | json格式 |
| partition-sepc-id | |
| format-version | 版本号 |
| content | 数据类型,data 还是 deletes |
manifest文件的 schema 是一个 struct,即 manifest_entry,它包含的字段:
| Field id,name | Type | Description |
| ---------------------- | ------------------------------------------------------ | -------------------------------------------------------------------------- |
| 0 status | int<br><br>0:EXISTRING<br><br>1:ADDED<br><br>2:DELETED | 用来跟踪添加和删除 |
| 1 snapshot_id | long | null表示Inherited |
| 3 sequence_number | long | 文件的Data seq number<br><br>Inherited when null and status is 1 (added). |
| 4 file_sequence_number | long | File seq number,代表了新旧。<br><br>Inherited when null and status is 1 (added). |
| 2 data_file | data_file struct | |
data_file struct:
| Field id, name | Type | Description |
| ----------------- | ------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------- |
| 134 content | int<br><br>0: DATA<br><br>1: POSITION DELETES<br><br>2: EQUALITY DELETES | data file的类型 |
| 100 file_path | string | fs URI |
| 101 file_format | string | avor/orc/parquet |
| 102 parition | struct<...> | partition data tuple |
| 103 record count | | |
| ... 列统计信息 | | |
| 135 equality_ids | list<136: int> | delete文件的删除条件 |
| 140 sort_order_id | int | 为空表示 unsorted,仅 data file 和 equality delete有效<br><br>postition deletes需要按 file 和 position排序 |
Manifest Entry Fields
manifest entry fields用来跟踪 snapshot 中添加了哪些文件或者逻辑删除了哪些文件。
sequence_number 代表文件内容的 relative age,用于判断跟哪些delete files合并。
file_sequence_number 表示s
**Sequence Number Inheritance**
Manifest 在一个 data/delete file 添加后跟踪 sequence number。
当添加一个新文件时,它的 data 和 file seqno 会被设置为 null,因此 snapshot 的 seqno 在提交前还没有赋值。
当读取时,会使用 manifest list 中记录的 manifest seqno。
也可以添加一个属于旧 seqno 的新文件,这种情况 data seqno 会显式提供,而不是从继承而来。
However, the file sequence number must be always assigned when the snapshot is successfully committed.
当将一个已存在的文件写入到新 manifest 或者标记它为 deleted,data 和 file seqno必须非空,且使用原始值。
继承意义:可以重用 manifest 文件,进行重试提交。
# Snapshots
一个 snapshot 包含如下字段:
| Field | Description |
| ------------------ | ---------------------------- |
| snapshot-id | 唯一的 long ID |
| parent-snapshot-id | |
| sequence-number | 递增的 long 型,跟踪每次table上的修改操作 |
| timestamp-ms | snapshot创建的时间,用于 GC 和 查看 |
| manifest-list | snapshot对应 manifest list 的位置 |
| manifests | |
| summary | 本次change的说明,包含 operation |
| schema-id | 当前的 schema id |
summary 中的 operation 字段,某些操作会用到:比如快照过期时跳过某些快照,operation可能的值:
- append:
- replace:Data and delete files were added and removed without changing table data,如 compaction,更改格式
- overwrite:Data and delete files were added and removed in a logical overwrite operation
- delete:
一个 snapshot 中的 data/delete files 可能存储到多个 manifest 中,这是为了:
- fast append:append时直接追加一个新的 manifest,而不是重写原来的 manifest
- table 可以使用多个 parition specs, 每个 manifest 只能对应一个 spec),多 manifest 可以允许同时有多个 partition spec
- 大的 table 通过多 manifest 来实现并行处理,或者减少重写manifest的代价。
一个快照有哪些manifest 是存储在 manifest list 中。
有哪些快照存储在 table metadata 中。
## Manifest Lists
某个snapshot的 manifest 列表是存储到单独的 manifest list file 中。
每次 snapshot commit 时都会新一个新的 manifest list。
manifest list 也包含了metadata 可以在Scan时避免扫描所有的 manifest。
manifest list 是一个 valid iceberg data file。
存储的条目为 manifest_file ,它是一个包含如下字段的 struct:
| | | |
|---|---|---|
|Field id,name|Type|Description|
|manifest_path|string|位置|
|manifest_length|long|大小|
|parition_spec_id|int|引用 table metadata 中的 partition-specs|
|content|int<br><br>0: data, 1: deletes|manifest类型|
|sequence_number|long|manifest添加到 table 时的 seqno|
|min_sequence_number|long|manifest中所有文件的最小 data sequence number|
|added_snapshot_id|long|manifest被添加时的 snapshot ID|
|paritions|list<||
field_summary
## Scan Planning
通过读取当前 snapshot 的 manifest files。
如果manifest中没有匹配的文件则跳过(通过 file counts 或者 parition summaries)。
对于每一个 manifest,scan predicates会转换成 parition predicates 来过滤文件。
例如一个 events table 有一个时间列 ts,parition方式: ts_day = day(ts)
查询条件:ts > X,转换为 ts_day > day(X)
scan predicates也可以基于 manifest 中的 column bounds 和 counts 来过滤 data/delete 文件。
符合查询条件的 Delete files 需要在读取时应用到 data files 上,限制条件:
- postition delete:
- data file 的 data_seqno 小于等于 delete file 的 data_seqno
- data file 的 parition (spec和parition values)等于 delete file 的 parition
- equality delete file:
- data file 的 data_seqno 严格小于 delete file 的 data_seqno
- data file 的 parition (spec和parition values)等于 delete file 的 parition
或者 delete file 的 parition spec 未指定
## Snapshot Reference
iceberg 使用 snapshot references 来跟踪 branches 和 tags。
Tags:snapshot 的 label
Branches:可变的命名引用,可以通过提交一个新的snapshot来更新branch。
snapshot引用存储在 table metadata 的 refs map 中。
## Snapshot Retention Policy
过期策略支持全局和引用级别:
- min-snapshots-to-keep
- max-snapshot-age-ms
- max-ref-age-ms
# Table Metadata
table metadata 存储为 json 格式。
每次 table metadata 变更都会创建一个新的 table metadata,并通过原子操作提交。
## Table Metadata Fields
| Field | Description |
| --------------------- | ---------------------- |
| format-version | 1 或 2 |
| table-uuid | |
| location | table 的 base location |
| last-sequence-number | 递增的序列号 |
| last-updated-ms | |
| last-column-id | 列ID分配 |
| schemas | schema列表(不同的schema id) |
| current-schema-id | |
| partition-specs | |
| default-spec-id | 当前的parition策略 |
| last-partition-id | parition field ID |
| properties | |
| current-snapshot-id | |
| snapshots | |
| sort-orders | |
| default-sort-order-id | |
| refs | |
| statistics | table统计信息 |
## Table statistics
## 提交冲突
同一时间,两个基于同一个版本的提交,只有一个能成功。
failed commit可以在新version上直接应用的情况:
- append操作
- replace操作:目标文件仍然存在
- delete操作:目标文件仍然存在
- schema 和 parition spec更新:base vesion与当前version之间schema没有变更
## File System Tables
atomic swap通过 atomic rename 来实现。
metadata名字:`v<V>.metadata.json`
每次提交生成新版本 V+1,执行如下步骤:
1. 读取当前 table metadata version:V
2. 基于version V 创建新的 table metadata
3. 写新的 table metadata,名字为 `<random-uuid>.metedata.json`
4. 重命名为 `v<V+1>.metadata.json`
如果重命名失败,从步骤1开始充实
## Metastore Tables
atomic swap:在metastore或者database中存储一个pointer,使用 check-and-put 操作更新
# Delete Formats
## Position Delete Files
存储file path + postition,也可选地包含deleted row。
## Equality Delete Files
存储删除条件:一个或多个列值
## Delete File Stats
存储在 Manifest 中