#database/olap
引用:[https://parquet.apache.org/docs](https://parquet.apache.org/docs)
# Overview
## Motivation
- 压缩、高效的列存,可用于 Hadoop 生态的任何项目。
- 基于 Dremel paper 中的 [record shredding and assembly algorithm](https://github.com/julienledem/redelm/wiki/The-striping-and-assembly-algorithms-from-the-Dremel-paper) 支持嵌套数据结构
- per-column compression scheme
---------------------
# Concepts
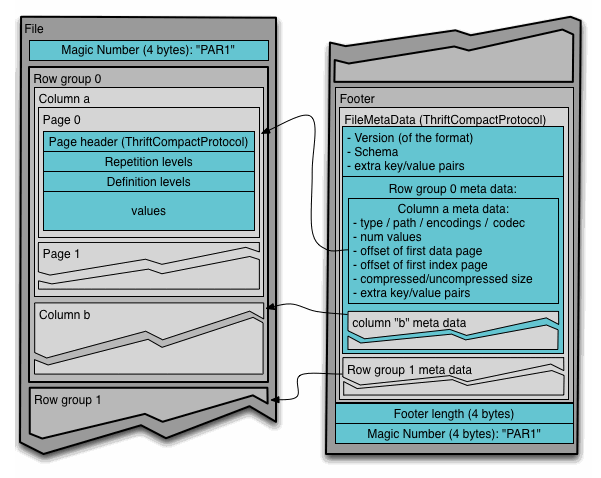
- **Row group**:将 rows 进行逻辑上的水平分区。一个row group 包含每个列的 column chunk。
- **Column chunk**:某一列的 data chunk,在文件内连续
- **Page**:Column chunks 拆分成 pages。最小不可拆分的单位(压缩和encoding)。一个 column chunk 内可以存在多种不同的 page types
- 结构上一个 **file** 由一到多个 row group 组成。
- **并行粒度**
- MapReduce:File/Row Group
- IO: Column chunk
- Encoding/Compression:Page
----------
# File Foramt
- thrift 定义
```
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"
```
- 拆分为 M 个 row groups。
- 一个 Chunk 对应一个 Row Group 的某列数据
- file metadata:所有 column metadata 的起始位置
- Reader
先读取 file metadata 找到感兴趣的 column chunk,再顺序读取 columns chunks。
- data 与 metadata 分离,可以把 columns 分成多个文件,通过一个 metadata file 来引用多个 parquest 文件。
==? column meta是否支持二分查找==
## Configurations
- **Row Group Size**
越多 column chunks 就越大,可以用做大的顺序IO。
但越大写的时候就需要更大的 buffer。推荐 512MB-1GB(差不多一个 HDFS block大小)。
读优化的配置:1GB Row group,1GB HDFS block size,每个 HDFS file一个 HDFS block。
- **Data Page Size**
小配置利于细粒度的读取(如单行查找)
大配置下额外的空间开销更少(page headers个数变少),解析header的开销也变小。
> 顺序 scan 时,一次不会只读一个page,page 它不是 IO chunk
推荐:8KB page size
## Extensibility
可兼容地扩展:
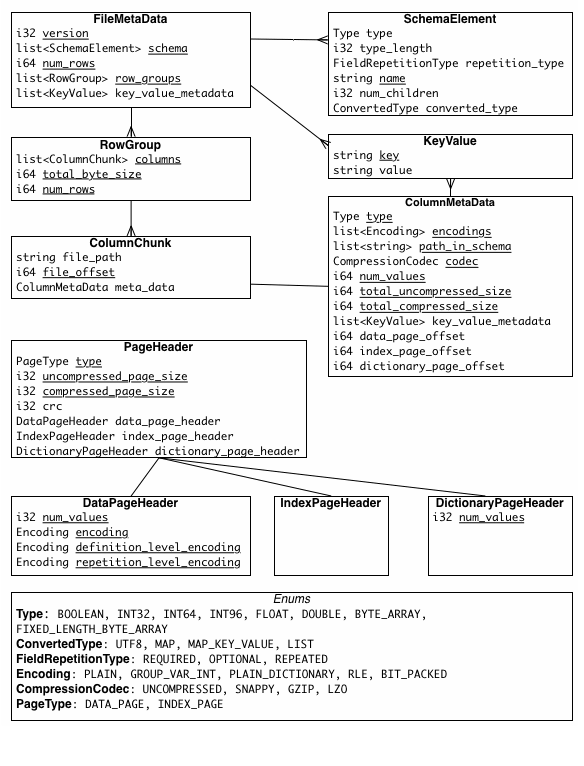
- **File version**:file metadata 中包含了一个 version
- **Encodings**:encoding 通过一个 enum 来指定,未来可以添加新的方式
- **Page Types**:未来可以添加额外的 page types,可以 safely skipped
## Metadata
三种 metadata:
- file metadata
- column(chunk)metadata
- page header metadata。
## Types
file format 能支持的 types 需要尽可能的少,这样可以聚焦优化磁盘存储。
例如不支持 16-bit 整型,因为可以被32位整型包含。
```
BOOLEAN: 1 bit boolean
INT32: 32 bit signed ints
INT64: 64 bit signed ints
INT96: 96 bit signed ints
FLOAT: IEEE 32-bit floating point values
DOUBLE: IEEE 64-bit floating point values
BYTE_ARRAY: arbitrarily long byte arrays.
```
### Logical Types
利用 logical types 来扩展 parquet 能存储的 types。
logical types 会映射到 primitive types。
这样可以保证 primitive types 最小化,和重用 parquet 的高效编码。
例如 string 存储会 byte arrays(binary),再加上一个 UTF8 的 annotataion。
annotations定义了如何 decode 和 interpret data。
Annotations 作为一个 ConverttedType 存储在 file metadata 中([LogicalTypes.md](https://github.com/apache/parquet-format/blob/master/LogicalTypes.md))
## Nested Encoding
todo!
## Data Pages
在 data page 中,紧跟在 page header 之后的是:
1. define levels data // 可选,column 是 required 时没有
2. repetition levels data // 可选,column是非嵌套时没有
3. encoded values // 必须
### Encodings
- **Plain**: (PLAIN = 0)
支持的类型:所有
最简单的编码方式:
- BOOLEAN:Bit Packed, LSB first
- INT32:4字节小端
- INT64:8字节小端
- INT96:12字节小端(已废弃)
- FLOAT:4字节 IEEE 小端
- DOUBLE:8字节 IEEE 小端
- BYTE_ARRAY:4字节小端长度 + 数据
- FIXED_LEN_BYTE_ARRAY:只有数据
^554e55
- **Dictionary Encoding**(PLAN_DICTIONARY = 2 和 RLE_DICTIONARY = 8)
把某列遇到的所有的 values 构建一个字典。
字典存储在一个 dictionary page 中(每 column chunk 一个)。
如果字典太大,则退回到 plain 编码。
列值存储为整型,使用 [RLE/Bit-Packing Hybrid](parquet-doc#^703e64) 编码。
先写 dictionary page(在 column chunk 的 data pages 之前)。
page 编码:
- dictionary page:按序使用 [Plain](parquet-doc#^554e55) 编码。
- data page:1 字节 的 bit width + [RLE/Bit-Packing Hybrid](parquet-doc#^703e64) 编码后的value
> Parquet 2.0 废弃了 PLAIN_DICTIONARY enum,data page 需要使用 RLE_DICTIONARY,dictiodictionary page 使用 PLAIN。
- **Run Length Encoding / Bit-Packing Hybird**(RLE = 3)
结合 bit-packing 和 run length encoding,存储重复 values 更高效。
```
rle-bit-packed-hybrid: <length> <encoded-data>
length := length of the <encoded-data> in bytes stored as 4 bytes little endian (unsigned int32)
encoded-data := <run>*
run := <bit-packed-run> | <rle-run>
bit-packed-run := <bit-packed-header> <bit-packed-values>
bit-packed-header := varint-encode(<bit-pack-scaled-run-len> << 1 | 1)
// we always bit-pack a multiple of 8 values at a time, so we only store the number of values / 8
bit-pack-scaled-run-len := (bit-packed-run-len) / 8
bit-packed-run-len := *see 3 below*
bit-packed-values := *see 1 below*
rle-run := <rle-header> <repeated-value>
rle-header := varint-encode( (rle-run-len) << 1)
rle-run-len := *see 3 below*
repeated-value := value that is repeated, using a fixed-width of round-up-to-next-byte(bit-width)
```
1. bit-packing: 从 LSB 到 MSB,
2. varint-encode:[ULEB-12](https://en.wikipedia.org/wiki/LEB128) 编码
3. bit-packed-run-len 和 rle-run-len 的范围是 32 位有符号整型
RLE 编码方式只支持一下类型的数据:
- Repetition 和 definition levels
- Dictionary indices
- Boolean values in data pages(作为 PLAIN encoding的替代)
^703e64
- **Delta Encoding** (DELTA_BINARY_PACKED = 5)
支持的类型:INT32,INT64
来源:[“Decoding billions of integers per second through vectorization”](http://arxiv.org/pdf/1209.2137v5.pdf)
使用变长整型来存储 numbers(不是 deltas)
- 无符号使用 [ULEB128](https://en.wikipedia.org/wiki/LEB128#Unsigned_LEB128)
- 有符号使用 zigzag 编码将负数映射到正数,再应用 ULEB128
Deleta encoding 由一个 header + blocks of deleta encoded values binary packed 组成
每个 block 由 miniblocks 组成。
header 定义:
```
<block size in values> <number of miniblocks in a block> <total value count> <first value>
```
- blocks 是 128 的倍数,ULEB128 int
- miniblock count per block:ULEB128 int,block size 的除数,商是一个 miniblock 的 values 数量(32的倍数)。
- total value count:ULEB128 int
- first value:zigzag ULEB128 int
每个 block 包含:
```
<min delta> <list of bitwidths of miniblocks> <miniblocks>
```
- min delta: zigzag ULEB128 int
- bitwidth:一字节
- 每个 miniblock:一系列 bit packed int,对应 block 起始处的 bitwidth
编码 block 的步骤:
1. 计算连续元素间的 diff。block的 first value 使用上一个block的最后一个元素(如果是第一个 block 使用整体的第一个value,header中存储的)
2. 计算 block内所有 deltas 的 min delta,所有的 deltas 再都减去 min delta,这样保证所有 values 都是非负的
3. 使用 zigzag ULEB128 int 编码 min delta,再加上 minblocks 的 bit widths 以及 每个miniblock 的 delta values(减去 min delta 后的)
多个 blocks 的设计可以适应 min delta 的变更,保证 delta values 更小。
**对比:**
[RLE/Bit-Packing Hybrid](parquet-doc#^703e64) 对于整型的值范围更小时,更有利(极端情况:一个 page 所有 values 都相同)。
- **Delta-length byte array**(DELTA_LENGTH_BYTE_ARRAY = 6)
支持类型:BYTE_ARRAY
对于 byte array columns,该编码会优先使用(相比 PLAIN)。
编码方式:
先取出所有 byte array 的长度,然后使用 delta encoding 编码,具体数据再放到后面。
优势:长度信息压缩率更高
- **Delta Strings** (DELTA_BYTE_ARRAY = 7 )
支持类型:BYTE_ARRAY
类似前缀压缩:存储上一个元素的 prefix length,加上 suffix
- **Byte Stream Split** (BYTE_STREAM_SPLIT = 9)
支持类型:FLOAT DOUBLUE
编码后不会减少数据的大小,但可以实现更高的压缩率和速度。
编码前:
```
Element 0 Element 1 Element 2
Bytes AA BB CC DD 00 11 22 33 A3 B4 C5 D6
```
编码后(穿插):
```
Bytes AA 00 A3 BB 11 B4 CC 22 C5 DD 33 D6
```
### Column Chunks
Column chunks由连续的 pages 组成。
这些 pages 共享一个共同的 header,readers 可以跳过不感兴趣的 pages。
page 中的数据可以compress and/or encoded,方式在 page metadata 中指定。
### Error Recovery
如果 file medata 损坏,则文件无法恢复。
如果 column metadata 损坏,对应的 column chunk 丢失。
如果 page header 损坏,则 chunk 内剩余的 pages 丢失。
如果 page 内的数据损坏,则该 page 丢失。
如果 row groups 越小,则容错率越高。
## Nulls
Nullity 编码在 definition levels 中(run-length编码)。
NULL values 不会编码到数据中。
-----------
# 其他
- [thrift 定义](https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift)
- [Querying Parquet with Millisecond Latency](https://www.influxdata.com/blog/querying-parquet-millisecond-latency/)
# 问题
- page header 一个 column chunk 内有多少个(一个 还是 每 page 一个)
> 每个page一个
- https://parquet.apache.org/docs/file-format/data-pages/columnchunks/