# ABSTRACT
snowflake:
- multi-tenant, transactional, secure、highly scalable, and elastic system
- full SQL support
- 内置扩展支持 semi-structured data 和 schema-less data
multi-cluster、shared-data
# 1 INTRODUCTION
- 背景:
- 传统数仓
- 平台在变(cloud,弹性容易,但传统数仓弹性能力弱)
- 数据在变:半结构化数据、schema-less数据
- Hadoop 大数据平台:
- 缺乏 efficency、feature set
- engineering effort
- Semi-Structured:
- SQL扩展 travere、flatten、nesting 半结构化数据,支持 JSON 和 Avro 格式。
- Automatic schema discovery
------------------
# 2 STORAGE VERSUS COMPUTE
- shared-nothing 架构:
每个查询节点有自己 local disk。
数据水平分区到每个node, 每个node自己 local disk 上的 rows。
适合 star-schema query:join small(broadcast)dimension table 与 large(partitioned) fact table。
问题:计算和存储耦合
- shared-data架构
存算分离,每个计算节点的 local disk 仅用作 cache(hot data)。
--------------
# 3 ARCHITECTURE
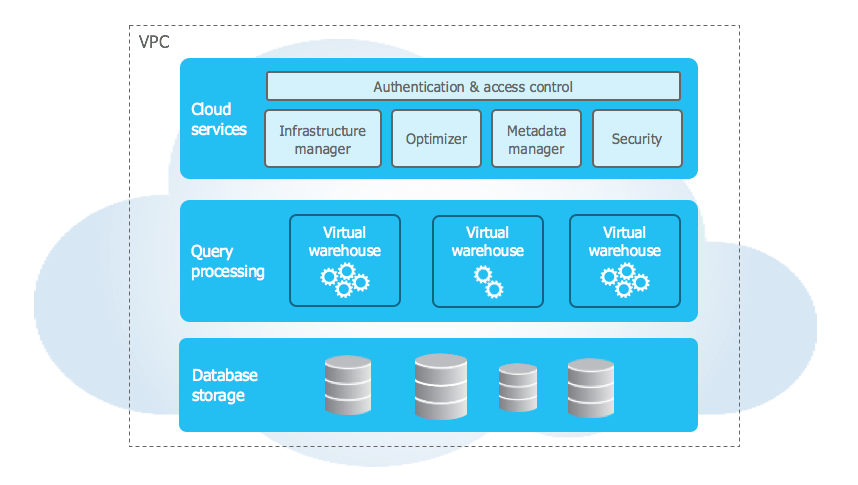
三层:
- **Data storage**:使用S3存储 table 数据和查询结构
- **Virtual Warehouses**:系统的肌肉,处理查询执行
- **Cloud Services**:系统的大脑, 管理 Virtual warehouse、queries ,transactions,metadata(schmea、访问控制、加密key,统计)
## 3.1 Data storage
文件格式:PAX hybird columnar,头部记录每列的偏移
S3 也用于存储临时数据(如massive join,本地磁盘放不下)
metadata(表内的文件列表、统计、locks、事务日志等)存放到了 transactional key-value store。
# 3.2 Virtual Warehouses
包含了 多个 EC2 集群。每个集群呈现给一个用户使用,通过 VW 层抽象。
每个 EC2 实例称为一个 worker node。VM是存粹的计算资源。
Ephemeral process:查询时node启动 woker process,每个worker process的生命期仅限于一次查询。
- cache:
worker node 上 LRU cache。
使用一致性hash策略cache不同的table file,访问相同file的查询会路由到同一个node
提高cache的命中率和避免cache重复数据。
- file stealing:
worker process 完成自己 input file set 的 scanning 后,从其他 peer 请求额外的文件处理。
requestor 直接从S3下载文件,而不是从 peer 传输文件。
- Execution Engine:
columnar:
vectorized:避免 materizalization intermediate results。pipleline的形式,几千rows(列存格式)批量处理。VectorWise
Push-based:非火山模型,realtional operator push结构到下游 operator。可以提升cache效率。
# 3.3 Cloud services
- **Query Management and Optimization**:
query早期阶段都在 Cloud Servcice层处理:parsing,object resolution,access control 以及 plan optimization。
query optimizer 采取了典型的 Cascades-style 形式,top-down cost-based optimization。
优化使用到的统计信息在数据写入和更新时自动维护。
snowflake没有使用索引,所以 plan search space比其他系统的小,并通过推迟许多descision到执行阶段,进行了进一步减少(如 join 的数据分布类型)。
优化完成后,execution plan分布到所有的 worker node 上执行。执行期间Cloud Service跟踪状态、收集性能指标、检测节点失败。
所有的查询信息和统计信息都存储起来用于审计和性能分析。
- **Concurrency Control**
分析型workload:large reads,bulk or trickle inserts,bulk updates。
实现了 snapshot 隔离(MVCC)。
由 global kv store 中存储的 meatadata 跟踪 table files 的 添加和删除,每次修改代表一个版本。
同时 MVCC 还用于 time travel 和 database objects clone。
- **Pruning**
传统B+树索引在Snowflake上的问题:
1. 依赖随机访问,对于S3 和 列存压缩文件不友好
2. 维护索引需要成本,拖慢load
3. 需要用户显式创建索引
- static pruning:
min-max based pruning
也涵盖了半结构化数据中自动探测的列。
- dynamic pruning:
执行过程中,基于统计信息
--------------
# 4 FEATURE HIGHLIGHTS
## 4.1 Pure Software-as-a-Service Experience
## 4.2 Continuous Availabilty
- Fault Resilience:
S3 和 Clound Service 跨 AZ (availabilty zones)
VM不跨AZ
- Online Upgrade:
无状态的服务容易升级
## 4.3 Semi-Structured and Schema-Less Data
为半结构化数据扩展的三种 SQL 数据类型:
- VARIANT:存储任意 native SQL type
- ARRAY:VARIANT的数组
- OBJECT:映射 string 到 VARIANT
VARIANT列可以用于 join keys,grouping keys以及 ordering keys。
VARIANT类型可以用于 ELT 而非传统的 ETL
对于半结构化数据,先scan文件,通过统计分析哪些列是常用的,存为单独的列存,其他列则组装到一个 VARIANT 列。