#tokio
原文:[https://tokio.rs/blog/2019-10-scheduler](https://tokio.rs/blog/2019-10-scheduler)
- [loom](https://github.com/tokio-rs/loom) Rust 并发代码的测试工具
# Schedulers, how do they work
- **Task**
- runnable when it can make progress
- idle when it is blocked on an external source
- user-space schedulers
- Tokio scheduler 执行 Rust futures(可以认为是异步的 green threads)
- scheduler model
- 最基本的:一个 run queue 和 一个 processor 负责消费 queue。
- 当一个 task 变得 runnable,就插入到 run queue。
多线程的两种途径:
- 一个 global run queue,多个 processors
- 多个 processors,每个 process 拥有自己的 run queue
## One queue, many processors
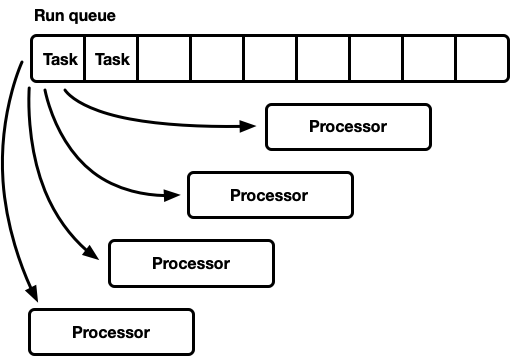
- tasks 变得 runnable 后,push 到 global run queue 的队尾。
- 每个线程从队首获取 task
- 优势:
- 调度公平(first-in,first out)
- 实现简单
- 劣势:
- 所有的线程竞争 queue 的 head
## Many processors, each with their own run queue
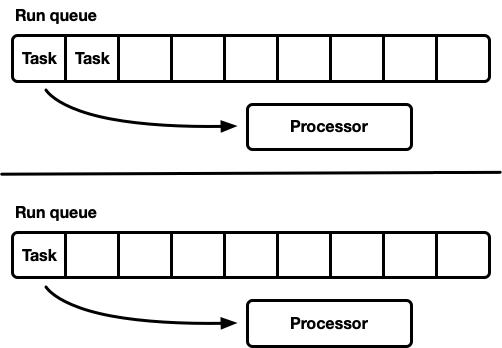
- 避免了同步问题
- 问题:workloads 不均衡
## Work-stealing scheduler
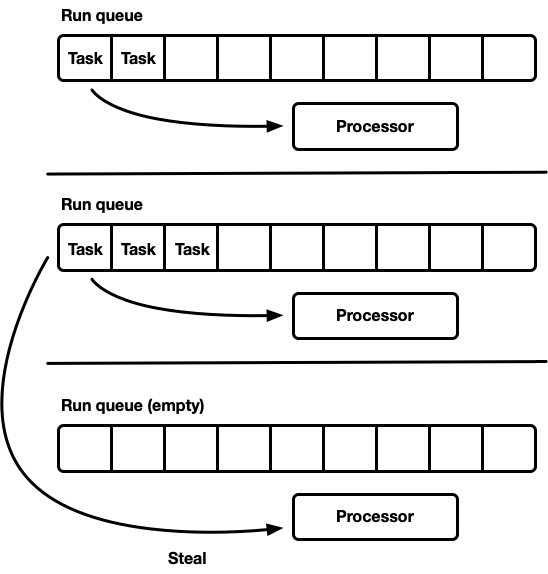
- 当一个 processor 空闲时,检查 sibling processor 的 run queues,尝试从中窃取任务。
- 平时没有同步开销,当负载在 processors 之间分布不均衡时,开始窃取(此时才有同步开销)。
-----------
# The Tokio 0.1 scheduler
- 2018/03 首次实现了 work-stealing scheduler。
- processor threads 空闲一段时间后会 shut down
- IO单线程
- CPU bound work 在线程池上执行
- 使用了 crossbeam 的 deque 实现
- 基于 [Chase-Lev deque](https://www.dre.vanderbilt.edu/~schmidt/PDF/work-stealing-dequeue.pdf), 不适合调度独立的异步 tasks
----
# The next generation Tokio scheduler
## The new task system
- [std new task system](https://doc.rust-lang.org/std/task/index.html)
- **Waker struct**
- 用于通知 task 变得 runnable。
- 只有两个 pointers,拷贝开销很小
- [custom vtable](https://doc.rust-lang.org/std/task/struct.RawWakerVTable.html)
## A better run queue
- **crossbeam deque**
- 单生产者、多消费者
- 要考虑队列的扩容,需要释放原来的 array,释放采取了 [EBR](https://aturon.github.io/blog/2015/08/27/epoch/#epoch-based-reclamation)
问题:hot path 上有额外开销,每个操作都必须使用 atomic RMW 操作(进入和离开 critiacal sections时)来通知其他线程内存正在使用不能被释放。
- **fixed-size per-process queue**
- 不用考虑扩容,同步开销很小
- 队列满了后,不增长 local queue,而是 push 到 global、多生产者多消费者的队列。
- processor 需要去检查 global queue,但不需要像 local queue 一样频繁
- **global queue**
- intrusive linked list,访问加锁
- push时,先把 tasks link 好,保证 critical section 尽可能小
- **push_overflow** 会移动 run queue 的一半到 global queue 中。同时 steal 操作也是拿取一半。
- 如果 local queue 非空,从 local queue 执行约 60 个 taks 后再检查 global queue。
另外处于 **searching** 状态下时,也会检查 global queue。
## Optimizing for message passing patterns
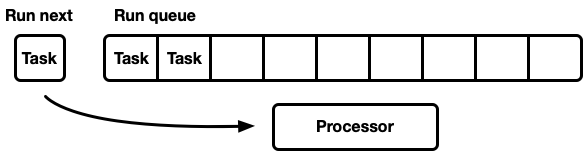
- 增加 next task slot,检查 run queue 前先检查它
- task 变成 runnable 时,先放到 next task slot,如果 slot 已经被占据则先淘汰 old task 到 run queue 尾部。
- 好处:task 可运行后,它需要的数据可能还在 cpu cache 中,如果放到队尾,等轮到它运行时,数据可能已经被淘汰了(运行滞后)
- 例子:task阻塞在 channel recv,保证消息接收到后能马上运行。
## Throttle stealing
- steal 时随机挑选 sibling processor,避免多个 processor 同时 steal 同一个 sibling processor,造成竞争。
- 限制在同一时刻可以 steal 的 processor 数量。正在进行 steal 的标记为 **searching** 状态。
## Reducing cross thread synchronization
- **sibling notification**
- 唤醒睡眠状态下的 sibling,来 steal tasks。
- 优化:
- 没有 workers 处于 searching 状态时才发送通知
- worker 接收到通知后马上进入 searching 状态,找到 new tasks 后退出 searching 状态然后通知另外一个 processor(相等于同时只有一个 processor 被唤醒)
## Reducing allocations
每个 spawned task 只需要进行一个分配(旧版本需要两次)。
```rust
struct Task<T> {
header: Header,
future: T,
trailer: Trailer,
}
```
- hot data 放在 struct 的头部,并且尽可能小。访问 Task 时,一次只 load 一个 cacheline 数据。
## Reducing atomic reference counting
Waker wake 时避免 clone 其拥有的 task 成员。
-------
# Fearless(unsafe) concurrency with Loom
- tool:[Loom](https://github.com/tokio-rs/loom)
- loom 会多次执行测试,排列组合多线程环境下所有可能的执行和行为。
- loom也会校验正确的内存访问、释放内存等。
- 核心算法基于[dynamic partial order reduction](https://users.soe.ucsc.edu/~cormac/papers/popl05.pdf)
----