# ABSTRACT
- **Reliability** at massive scale 是亚马逊的最大挑战;
- Dynamo:**高可用**的 KV 存储系统。
- 在某些场景下,会牺牲一致性来换取可用性。
---
# 1. Introduction
- Amazon 去中心化的 SOA 架构,需要应用的状态存储始终可用。
- Tradeoffs:
- availability
- consistency
- cost-effectiveness
- performance
- Dynamo 实现 scalability 和 availability 的关键技术:
- 数据分区和复制:consistent hashing
- 副本间一致性: quorum-like 和去中心化的同步协议
- 故障检测和成员变更:gossip
- 证明了最终一致性也适用于要求严格的应用。
---
# 2. Background
- 关系型数据库的问题:
- 大多数应用只需要按主键读写,不需要复杂的查询
- 硬件成本高、使用难度高
- 可用的复制技术受限、一致性高于可用性
- 不容易扩展和使用智能分区方案进行负载均衡
## 2.1 System Assumptions and Requirements
- query model:KV
- value 为 binary objects,相对比较小(通常小于 1MB)
- ACID 属性:
- 目标应用:允许牺牲 C, 来换取高可用
- 没有隔离性,只有单行更新
- 只在 amazon 内部使用,没有安全、认证方面的需求
## 2.2 SLA
- 使用 tp999 来描述 SLA
- 目标是几乎所有客户都有良好的体验
- 大多数应用逻辑都比较轻量级,存储系统在整个服务的 SLA 中占据很大比重。
- Dynamo 的主要设计考虑之一是让服务能够控制其系统属性,例如持久性和一致性,并让服务在功能、性能和成本效益之间进行权衡。
## 2.3 Design Considerations
- CAP 不可同时满足,采取==最终一致性==来提升可用性
- optimistic replication
- 允许变更在后台传播给副本
- 必须检测和解决冲突
- 冲突解决的两个问题:
- **when**:即读还是写的时候
- 大多数传统存储系统在写时解决,来保证读操作的简单性
- 问题:写入如果在给定时间内无法达到所有/大多数副本,就会拒绝写入;
- Dynamo 的设计目标是==始终可写==,因此选择在读时解决冲突
- **who**:存储系统还是应用
- 存储系统:只能使用简单的策略,例如 last write wins
- 应用:根据业务特点自定义冲突解决策略
- 其他关键设计:
- Incremental scalability:一次扩展一个节点,影响最小。
- Symmetry:每个节点的地位/责任一样,简化系统的配置和维护
- Decentralization:去中心化,优势:更简单、更 scalable 和 avaliable
- 中心化控制容易产生 outages
- Heterogeneity:可以部署在异构、不同配置的服务器上。
- 添加高容量的新节点,不需要一次性升级现有的所有节点
- *通过一致性 hash 实现,配置不同的 token*
---
# 3. Releated Work
- 对比:
- vs Bigtable:多维 sorted map,Dynamo 只有 kv 且始终可写入
- vs RDBMS:强调强一致性,扩展性和可用性受限
- Dynamo 差异性:
1. always writable:即使遭遇网络分区和故障
2. 单一管理域,假定所有节点都是可信的
3. 数据模型简单 KV
4. Dynamo 为低延迟应用而构建:
- 99.9% 读写在几百 ms 内
- Dynamo 可以视为时一个 ==zero-hop DHT==
- 每个节点都维护着整体的路由信息,可以将请求直接路由到合适的节点
----
# 4. System Architecture
- 一个数据系统的解决方案需要覆盖:
- 负载均衡
- membership
- 故障检测
- 故障恢复
- 副本同步
- 过载处理
- ❓*state transfer*
- 并发和任务调度
- ❓*request marshalling*
- 请求路由
- 监控和报警
- 配置管理
- 关键技术和优势:
| Problem | Technique | Advantage<br> |
| ---------------------------------- | ---------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------- |
| 分区 | Consistent Hashing | IncrementalScalability |
| 写入高可用 | vector clock、读时协调 | Version size isdecoupled from update rates. |
| 处理 temporary failures | Sloppy Quorum and<br>hinted handoff | Provides high availability and durability guarantee when some of the replicas are not available. |
| Recovering from permanent failures | Anti-entropy using Merkle trees | Synchronizesdivergent replicas inthe background |
| Membership and failure detection | Gossip-basedmembership protocoland failure detection | Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information. |
## 4.1 System Interface
- get(key)
- 返回单个 object 或者一组版本冲突的 objects 及 context
- put(key, context, object)
- context 包含了 object 的 system metadata,对 caller 透明
- 例如 object 的 version
- context 跟 object 一起存储
- key 路由:计算 key 的 MD5 hash,生成 128-bit 的标识,用于路由
## 4.2 Partitioning Algorithm
- 分区基于 consistent hash
- basic consistent hashing 的问题
- 给每个节点随机分配 hash ring 上的一个位置,可能导致负载不均衡
- 无法处理==异构节点==
- Dynamo 使用了 virtual nodes 机制
- 每个节点负责多个 virtual nodes,即分配多个位置/tokens
- 解决异构问题:基于节点的容量分配不同数量的 virtual nodes
## 4.3 Replication
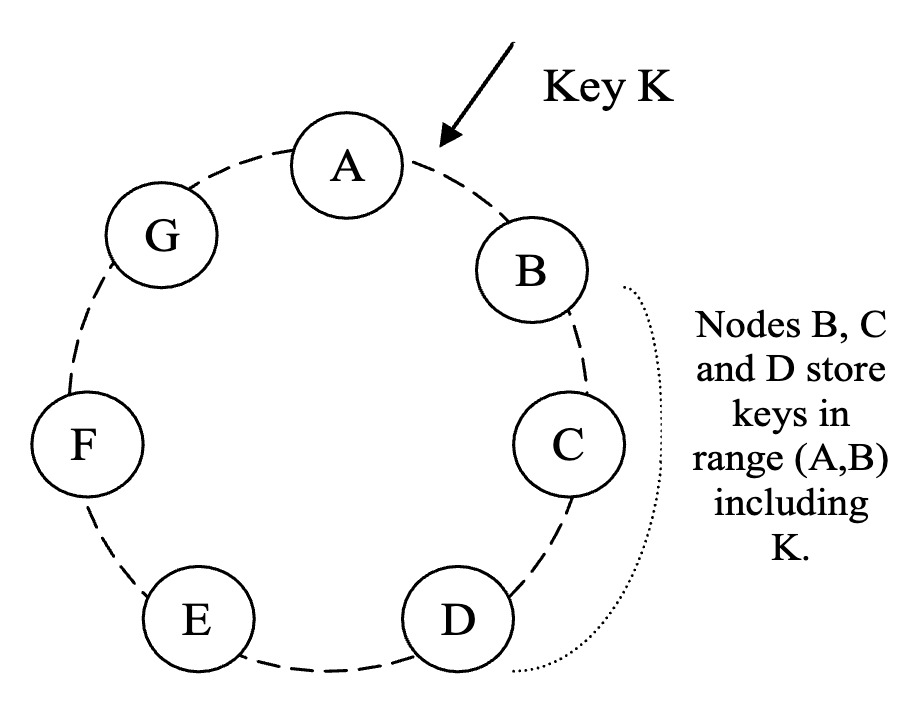
- 每条数据存储到 N 个节点上,每个 key 分配一个 coordinator node 负责复制。
- coordinator 将数据复制到 ring 上顺序针方向的后续 N-1 个节点
- **preference list**:存储某个 key 的 N 个 nodes/副本
- 考虑到节点故障,preference list 包含的节点数量==大于 N==
- virtual nodes 机制下,需要按物理节点进行==去重==
## 4.4 Data Versioning
- 最终一致性,允许==异步地==将更新传播到所有副本。
- 写返回时更新操作并不会应用到所有副本,因此可能会==读到旧数据==。
- 数据的每次修改都是一个新的 immutable version。大多数情况下,新版本包含了之前的历史的版本(可以直接 overwrite)。
- 同一个 object 产生多个冲突版本的原因:
- 并发修改:基于当前版本有多个并发的修改,这张冲突只能通过==应用==来调解。
- 故障:网络分区和节点故障
- 使用 **vector clock** 来捕获同一个 object 上多个版本之间的因果关系。
- 形式为 (node, counter) 对的列表,对应一个 version。
- 仅当 version-1 的==所有== counter 都小于 version-2 的,才能表示 version-2 是 version-1 的后继,可以丢弃 version-1;其他情况则需要 reconciliation。
- client 更新一个 object 时,需要先指定在哪个 version 之上进行更新。
- verision 来自读操作返回的 context
- 可能返回多个冲突的版本,需要 client 先折叠成一个 version,再更新
- version 演变示例:
- 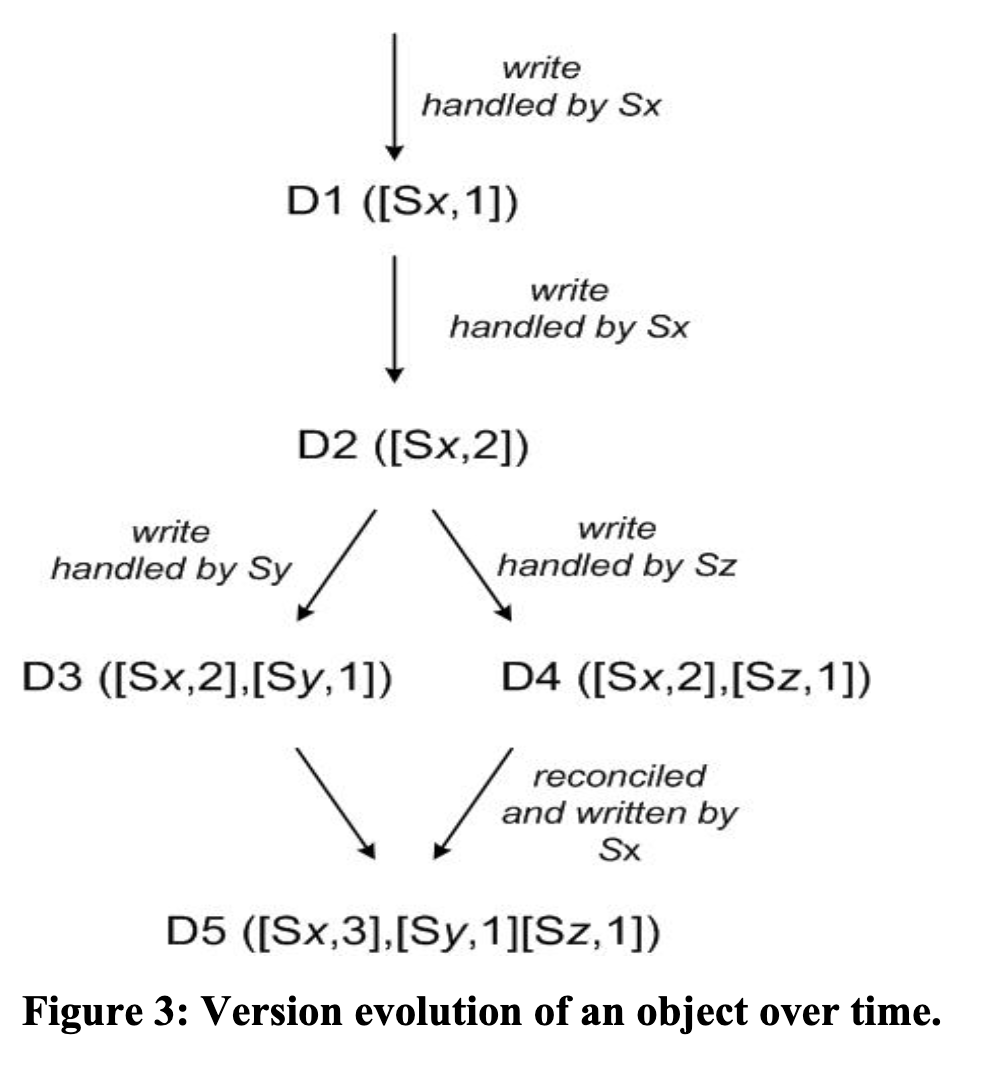
1. 写入到节点 Sx
2. 写入到节点 Sx
3. 读到 D2 并发写入到两个不同节点 Sy 和 Sz
4. 再次写入到 Sx 后,进行协调
- vector clocks 压缩:
- 避免过大即参与写入的 coordinator 节点太多时
- 通常不会,受限于 pereference list 列表 top N 节点(N 是副本个数),只有故障后会写入其他节点
- clock truncation:
- 每个 object 额外存储一个 last update timestamp
- 当 (node, counter) pairs 过多时,删除最老的,可能会造成因果关系==失真==。
## 4.5 Execution of get/put
- get 和 put 操作的通信协议基于 HTTP。
- 为每个 key 挑选一个 **coordinator** 节点来协调读写操作。
- coordinator 来自 perference list,并应用 LB 策略。
- coordinator 负责读取/写入自身存储,以及从==其他节点==读取/写入。
- 一致性参数:**R** 和 **W**
- R:每次读操作至少读几个副本
- 如果无法协调多个副本的版本,则返回所有因果无关的版本
- W:每次写操作至少同步写几个副本
- coordinator 先写入 local new version,再发送到其他 N-1 个 highest-ranked reachable nodes,至少 W-1 个 nodes 回应后才认为写入成功
- 设置 R + W > N,则生成一个 quorum-like 的系统。
- 读写操作的延迟取决于 R/W 副本中最慢的那个。
```mermaid
stateDiagram-v2
Client --> coordinator: get/put
coordinator --> Client: result
coordinator --> node1: read/write
node1 --> coordinator: response
coordinator --> node2: read/write
node2 --> coordinator: response
coordinator --> node3: read/write
node3 --> coordinator: response
```
## 4.6 Handling Failures: Hinted Handoff
- sloppy quorum:
- 读写操作执行在 preference list 的 first N ==healthy== nodes 上
- 并不一定是 hash ring 上遇到的 first N nodes,会跳过故障节点
- 
- 示例:N=3,K 本该写入到 A 上,但是 A 故障了,将会写入到 D 上。
- Hinted Handoff:
- D 被称为 hinted replica,写入到 D 上的单独的 local database 中,并且会定期扫描当 A 恢复后再==传递==给 A。
- 保证了读写的高可用。例如 W=1 时,只要集群内有一个节点存活就能写入。
- 适用于 transient node failures
- Across multiple data centers
- 构造一个 key 的 preference list 时,保证节点分散到==不同 DC==。
- 可以容忍某个 DC 整体故障。
## 4.7 Handling permanent failures: Replica synchronization
- 使用 anti-entropy 协议来保持副本数据同步。
- 使用 [Merkle trees](https://people.eecs.berkeley.edu/~raluca/cs261-f15/readings/merkle.pdf) 来检测副本间的不一致性。
- 快速检测、最小化数据传输
- 每个 node 为==每个 key range==(对应一个 virtual node)维护一棵 Merkle tree。
- 两个 node 交换对应 key range 的 Merkle tree root
- disadvantage:node join/leave 时许多 key range 会改变,trees 需要==重新计算==
- *virtual node 在 hash ring 上负责的 key range 会缩小/扩大*
## 4.8 Membership and Failure Detection
### Ring membership
- ==显式==地发起增删 node 操作
- node 故障很少意味着永久性下线,因为当副本不可达时不应该马上自动均衡分区或者修复副本。
- 变更流程:
1. 管理员使用命令行工具或者浏览器连接到一个 node 上,发起成员变更操作
2. node 将写入变更、持久化到存储中
3. 使用 gossip 协议传播成员变更,维护 membership view 的最终一致性
- 每个 node 每秒随机挑选一个 node 联系,nodes 两两交换持久化的成员变更历史
- token sets 映射(路由信息)
- 首次启动时,挑选自己的 tokens 集合(hash ring 上的 virtual nodes),并将 nodes <-> token sets 之间的映射持久化;
- 该映射初始化只包含 local node 自身的,后续通过交换来完善。
- 该映射起到路由的作用,每个 node 都有,可以将 key 请求转发到合适的 node 上
### External Discovery
- 问题: 可能造成 hash ring 被分区
- 同时新加两个新节点 A 和 B,它们彼此还没发现对方,hash ring 上只有 A 或只有B。
- 解决:选择若干 nodes 作为 **seeds**
- seed nodes 从==外部==发现成员,知道所有的 nodes 信息
- 其他 nodes 从 seeds 上同步成员,最终达到一致。
### Failure Detection
- 故障检测仅用于防止访问到 unreadable peers,为了达到这个目的,只需要==本地检测==即可。
- 即 B 如果不回应 A 的消息,则 A 会将 B 认定为 failed,A 使用替代节点来代替访问 B 上分片。
- ❓ *A 是 coordinator 节点 ?*
## 4.9 Adding/Removing Storage Nodes
- keys reallocation
- 新 node X 加入,会随机分配多个 hash ring 上的 tokens / key range;一些现有节点需要将不再由自己负责的 keys 传送给 X。
- 节点删除时,执行相反的流程
- 这种方式可以使负载比较均衡,能很好地满足延迟要求和 fast bootstrapping。
- ❓ *fast bootstrapping 是指新节点能同时从多个节点传输数据?*
---
# 5. Implementation
- 每个 storage node 有三个主要的组件(Java 实现的):
- request coordination
- membersip & failure detection
- local persistence engine
- **local persistence engine**
- 可插拔的多个不同引擎:
- Berkeley Database
- MySQL
- in-memory buffer 加 persistent backing store
- 应用可以根据自己的访问模式选择不同的引擎
- **request coordination**
- 事件驱动,SEDA 架构,所有的通信使用 Java NIO channels 实现
- coordinator 代替 client 来执行读写请求,从多个节点收集数据(读)或者写入到多个节点
- 收到每个请求会创建一个状态机负责处理流程,包含发送请求、等待回应、重试、处理回应、返回给 client 等。
- 读操作流程:
1. 向 nodes 发送 read requests
2. 等待 minimum number of required responses
3. 如果在一段时间内无法收齐足够多的回应,则请求失败; 否则收集所有 versions 并决定返回哪个/哪些版本
4. 执行 syntactic reconciliation,生成一个不透明的 write context(包含了 vector clock)
- read repair:
- 发现有副本返回的数据版本比较旧,对其进行更新
- 写操作:
- coordinator 是从 perference list 的前 N 个 nodes 中挑选的,在它们之上进行负载均衡
- ~~❓读操作的 coodrinator 可以是任意 node 吗 ~~(是的,见 6.4)
- 相同 key 的读操作会优先路由到==上一次写入==的 node,实现 read-your-writes 一致性,同时也能减少性能的波动。
---
# 6. Experiences & Lessons Learned
- 使用 Dynamo 的业务特点/模式:
- 业务逻辑自定义 reconciliation
- Dynamo 的流行用法。例如购物车业务
- 基于 timestamp 的 reconciliation
- last write wins(物理时间戳大的选为正确版本),例如存储用户 session 信息的业务
- 高性能的 read engine
- 调整 quorum 参数,业务读多写少,R 设为 1,W 设为 N(durability)
- 商品类目和促销信息的业务
- Dynamo 的一个主要优势:应用可以调整 N,R 和 W,来达到期望的 performace、availablity、 durability 和 consistency。
- 例如 N 决定了每个 object 的 durability,典型值为 3
- 例如 W 设为 1,则写入的 availablity 最优,但是 inconsistency 的风险会增加、引入 durability 的风险窗口(返回给 client 但只有很少的副本持久化了)
- 一些实例的常见 (N, R, W)配置:(3,2,2)
- 跨 DC 对延迟的影响:
- data centers 之间的延迟会影响 response time,因此 coordinator 会基于 DC 位置来挑选 nodes 以满足 SLA 要求。
## 6.1 Balancing Performance and Durability
- **object buffer**
- 先写入内存,再周期性持久化,牺牲 durability 换取 performance
- 读操作先检查 buffer
- 为了缓解对 durability 的影响,coordinator 写入时从 N 个副本中选择一个来执行 ==durable write==(即写入持久化 DB 而非内存)
- 因为只等待 W 个副本,单个 durable write 副本的也不会影响影响。
## 6.2 Ensuring Uniform Load distribution
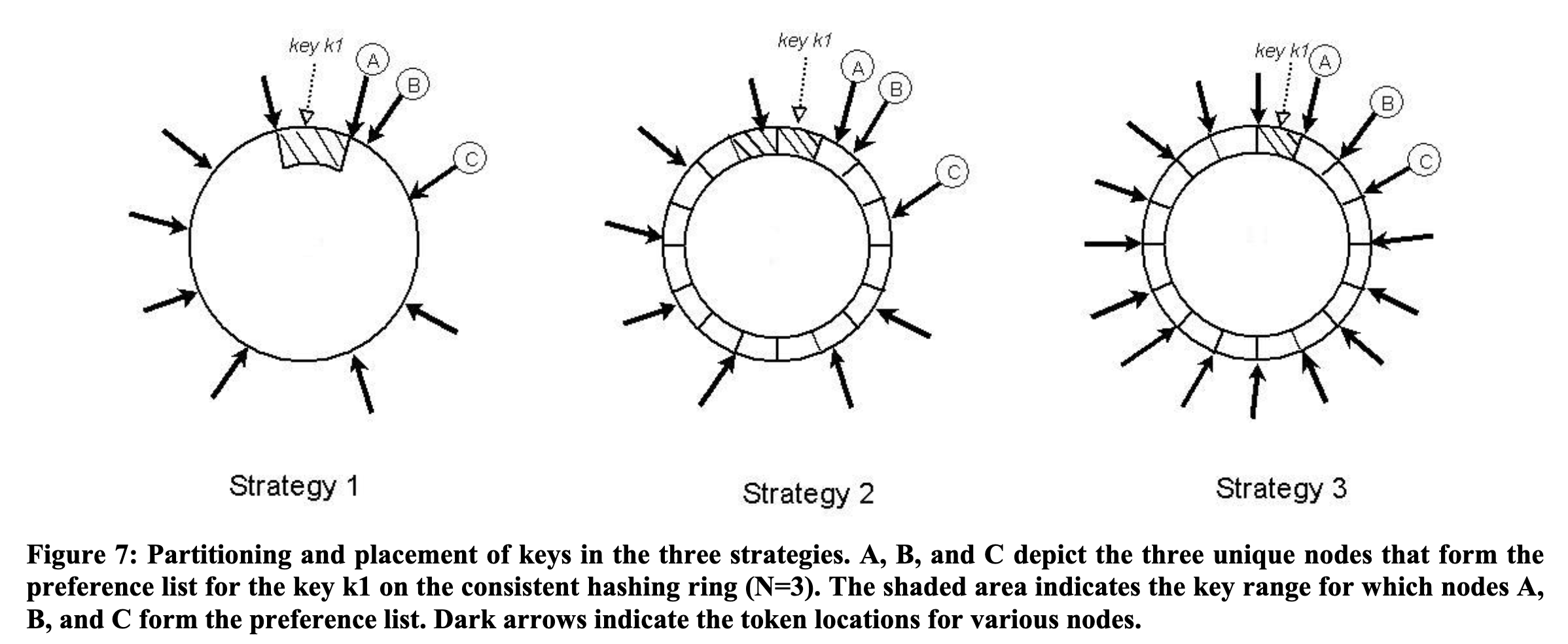
- 不同的策略:
- Strategy 1: 每 node 随机 T 个 tokens,按 token 进行 partition
- 一致性 hash 的 virtual node 模式,每个 node 在 hash space 上随机出 T 个位置
- 问题:
1. 新 node 的 bootstrap 需要从其他节点窃取 key ranges,需要执行扫描操作,影响前台性能
2. node 加入/离开时,node 负责的 key range 会变化,导致需要重新计算 merkle tree
3. 获取整个 key space 的快照很低效,因为 token 是随机出来的,每个 partition 的大小范围不确定
- Strategy 2:每 node 随机 T 个 tokens,equal sized partition
- 将 hash space 分成 Q 等份 partitions/ranges,每个 node 仍然随机 T 个 tokens
- 每个 partition 由 hash ring 上该 partition 之后的 N 个 unique nodes 负责
- Strategy 3:每 node 分配 Q/S tokens,equal sized partition
- 直接给每个 node 分配 partition,而不是靠在 ring 上随机 hash 。
- Strategy 3 效果最好,相比随机能确定性地均匀分配,同时 partition 的粒度大了,元数据量级小了。
## 6.3 Disvergent Verions: When and How Many?
- disvergent version 的来源:
1. failure
2. concurrent writers
- 为了可用性和效率,需要尽量减少不同版本的数量。
- 系统无法进行 syntactic reconciliation 时,则要依赖业务逻辑进行 semantic reconciliation(但给业务增加了额外负担,最好尽量减少对其的需求)
- 版本数量统计:
- 99.94%的请求只看到了一个版本
## 6.4 Client-driven or Server-driven Coordination
- client-driven:将 state machine 逻辑移动到 client 侧
- 优势:请求直接在 client 本地协调,不需要 coordinator 节点代理转发,也不要执行挑选 coordinator 所需的负载均衡逻辑。
- 更低延迟
## 6.5 Balancing background vs. foreground tasks
- 每个 node 都有执行不同种类的后台任务,如
- 副本同步
- data handoff
- **Admission control mechanism**
- 后台任务会跟前台的 get/put 请求竞争资源,因此引入了 admission control mechanism ,给后台任务分配可用的 time slices。
- ==feedback== 机制:监控前台任务的性能更新后台任务可用的 resource slices
- 监控维度:磁盘操作的延迟、db 访问的锁竞争和事务超市、请求队列等待时间
---
# 7. Conculsions
- 极高的 availability,99.9995%的请求成功率
- 可调整的 (N,R,W)参数
- O(1) DHT system
- gossip 协议,每个 node 上都有路由信息
--------
# 总结
- 高可用:
- alway writable
- sloppy quorum
- hinted handoff
- preference list can span across multiple data centers
- 最终一致性
- 冲突解决,利用 object versioning (vector clock)
- 两种解决方式:syntactic(系统内部) vs semantic(应用)
- 允许在旧的 version 上修改,后台异步解决冲突;
- 复制和分区都通过一致性hash
- virtual node
- 划分 hash ring 为多份,均分给 nodes
- scale incrementally
- 去中心化架构
- 延迟敏感
- 客户端按需调优
- N R W
- object buffer