# Abstract
- FoundationDB: 开源的 **transactional** key value store。
- 结合了 NoSQL 架构的灵活性、可扩展性与 ACID 事务的功能性
- unbundled 架构
- 解耦了:
- in-memory tansaction management system
- distributed storage system
- built-in distributed configuration system
- 每个子系统都可以独立配置和设置,以实现所需的可扩展性、高可用性和容错特性。
- 集成了一个 deterministic simulation framework。
- 提供了一个精简且经过仔细选择的功能集,使得各种不同系统能够构建在其之上。
- 半关系型数据库、文档和对象存储、图形数据库等
----
# 1. Introduction
- cloud services 需要存储 state,对 storage backend 的要求:
- fault tolerant,高可用
- strong semantics
- 事务和一致性
- 灵活的数据模型,方便快速开发
- 高容量+请求高并发
- NoSQL 存储 vs 事务:
- 过往的 NoSQL 存储一般都牺牲了 transactional semantic,只提供最终一致性,需要应用程序来处理并发操作引发的问题。
- 近年来,许多 NoSQL 系统开始提供 ACID 事务,如 Cassandra,MongoDB、CouchBase 等。FoundationDB 提供了 serializable transactions,同时也保持了 NoSQL 的高扩展性等优点;
- FoundationDB:
- 2009 年创建,名字起源:为更高层系统提供 **foundation**al set of building blocks
- 事务性 KV storage
- multi-key strictly serializable transaction
- 结合了 OCC 和 MVCC
- 支持==放宽==事务语义,提供更高灵活性
- 模块化架构
- 精心挑选的最小化特性集合
- 没有结构化语义、查询语言、数据模型、schema管理、二级索引等特性,但可以在其上构建 layers 支持
- deterministic database simulation framework
- 模拟进程间的网络交互、磁盘/进程/网络/请求级别的故障和回复
- 系统由**控制面**和**数据面**组成:
- 控制面管理集群的元数据,使用 [Active Disk Paxos](https://dl.acm.org/doi/10.1145/571825.571837) 来实现高可用。
- 数据面包括了**事务管理系统**(负责处理更新)和分布式 **storage layer**(负责服务读请求),两者都可以==独立==扩展。
- 特殊的故障处理:
- FDB ==不依赖== quorums 来掩盖故障,而是通过重新配置系统积极检测并恢复,能够以**更少的资源**实现相同级别的容错
- f + 1 个副本可以容忍 f 个失败
----
# 2. Design
- 一个生产级 DB 需要解决的问题:
- 数据持久化,数据分区,负载均衡
- 成员管理、故障检测和故障恢复、副本替换和数据同步
- 过载保护、扩展、并发和任务调度
- 系统监控、报警、备份、多语言客户端库
- 系统更新和部署、配置管理
## 2.1 Design Principles
- **分而治之**
- 解耦了 write path (事务管理)和 read path(分布式存储),并可独立扩展
- 在事务管理系统内,进程被赋予不同的角色来代表事务管理的不同方面。
- 包括 timstamp 管理、commit 接收、冲突检测和 lo logging。
- 集群级别的编排任务,如过载控制、负载均衡和故障恢复,也划分给额外的异构角色。
- **Make failure a common case**
- 对于分布式系统,故障是常态而不是例外。
- 在 FDB 的事务管理系统中,通过 recovery path 来处理==所有的==故障。
- 事务管理系统检测到故障时,会主动关闭,而不是修复所有可能的故障场景。
- 所有的故障处理都简化成一个 recovery 操作。
- **Fail fast and recover fast**
- 为了提升可用性,FDB 努力最小化 MTTR(平均恢复时间)。
- 包含了故障检测、关闭事务管理系统和恢复等时间。
- 总时间通常小于 ==5 秒==。
- **Simulation testing**
- 依赖随机化的 deterministic simulation framework 来测试正确性。
- 用于发现 deep bugs,提升开发效率和代码质量。
## 2.2 System Interface
- 支持读写单个 key 和 key ranges。
- get() / set() 用于读写单个 key
- getRange() 返回给定范围内的有序 keys 列表
- clear() 用于删除某个前缀的所有 KV。
- 事务
- 一个 FDB 事务读取和修改的是 database 在某个时刻的==快照==,只有当事务提交时才会将更改应用到底层database。
- 事务的写入缓存在 FDB client,直到调用最后的 commit() 。通过合并 database 的数据和事务 uncommitted writes 来实现 **read-your-write** 语义。
- 大小限制(为了更好的性能):
- key size 10 KB,value size 100 KB。
- transaction size 限制到 10 MB,包含了
- 写入的所有 keys + values
- 显式指定的 read/write conflict ranges 内的所有 keys 的 size
## 2.3 Architecture
- 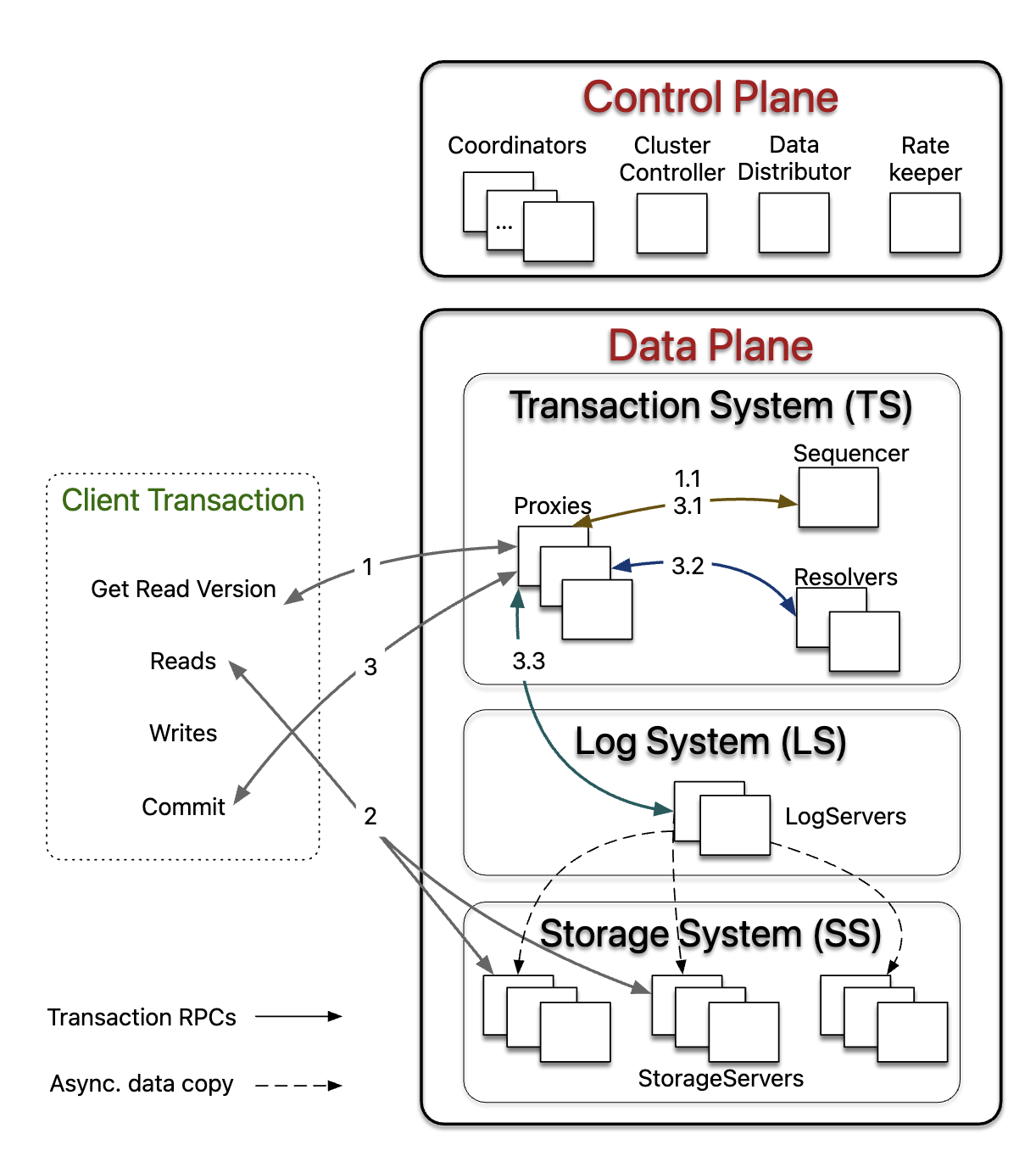
- 一个集群由两部分组成:
- control plane:管理核心的系统元数据和集群级别的 orchestration
- data plane:负责事务处理和数据存储。
### 2.3.1 Control Plane
- **Coordinators** 上持久化了核心的系统元数据,如事务系统的配置
- Coordinators 组成了一个 disk Paxos group,并选择一个单例 ClusterController。
- **ClusterController** 监控集群中的所有 servers,并雇佣了三个单例进程 Sequencer,DataDistributor 和 RateKeeper,如果它们故障会重新雇佣。
- Sequencer 负责分配事务的 read 和 commit versions
- DataDistributor 负责监控故障和在StorageServers之间均衡数据。
- RateKeeper 负责集群的过载保护
### 2.3.2 Data Plane
- FDB 目标是 OLTP 工作负载:
- 读操作最多,读写的 keys 集合很小,low contention,以及需要扩展性 scalability。
- unbundled architecture:
- **TS**:分布式的事务管理系统。执行 ==in-memory== transaction processing
- 由一个 Sequencer、多个 Proxies 和 Resolvers 组成,都是 stateless 的进程。
- **Sequencer** 为每个事务分配一个 read version 和一个 commit version。因为历史原因,还雇佣了 Proxies,Resolvers 和 LogServers。
- **Proxies** 为 clients 提供了 MVCC read versions,同时组织事务的提交。
- **Resolvers** 检查事务之间的冲突。
- **LS**:日志系统。存储 WAL。包含了一组 LogServers。
- **LogServers** 充当 replicated,多分片的、分布式持久化队列。每个队列为一个 StorageServer 存储 WAL data。
- **SS**:分布式的存储系统。用于存储数据和服务读请求。
- 由多个 **StorageServer**s 组成。每个 StorageServer 存储一组 data shards,一个 shard 是一个连续的 key 范围。
- StorageServers 是系统中数量最多的进程,它们一起组成了一个分布式的 B-tree。
- 每个 StorageServer 上的存储引擎是一个修改版本的 SQLite。
- 加快了 range clears,延迟删除到后台任务,支持异步编程。
- 
### 2.3.3 Read-Write Separation and Scaling
- 设计上解耦,进程被赋予不同角色,每个角色独立扩展, client reads 和 client writes 的扩展是分开的。
- reads 直接访问 sharded StorageServers,read scale 按照 StorageServers 数量呈线性增长。
- write scale 通过增加更多的 Proxies,Resolvers 和 LogServers 进程来实现。
- 因为这个原因,MVCC data 存储在 ==SS==,而非像 [Deuteronomy](https://www.microsoft.com/en-us/research/publication/deuteronomy-transaction-support-for-cloud-data/) 一样存储在 TS。
- *为了 read scale?*
### 2.3.4 Bootstrapping
- 系统是自举的,不依赖外部服务。
- 数据和元数据的存储位置:
- user data 和大多数的 system metadata(key的前缀为 0XFF)都存储在 StorageServers;
- StorageServers 的 metadata 持久化在 LogServers 中;
- LogServers 的配置存储在 Coordinators 中。
- 启动流程:
1. 利用 Coordinators 的 disk paxos group 特性,servers 尝试选举成为 ClusterController(如果不存在的话);
2. 新选举的 ClusterController 雇佣一个新的 Sequencer,Sequencer 从 Coordinators 中读取旧的 LS 配置,并生成新的 TS 和 LS;
3. Proxies 从老的 LS 恢复 system metadata,包括所有 StorageServers 的信息;
4. Sequencer 等待新的 TS 完成 recovery,然后将新的 LS 配置写入到所有 Coordinators 中;
5. 此时,新的 TS 变为就绪,可以接收 client 的事务请求;
### 2.3.5 Reconfiguration
- 当 TS 或 LS 发生故障,或者 database 配置发生变更时,一个 reconfiguration process 会将事务管理系统带入到新的配置,即 clean state。
- Sequencer 监控着 Proxies,Resolvers 和 LogServers,如果它们发生故障或者配置变更,Sequencer 进程将**终止**。
- 随后 ClusterController 检测到 Sequencer 故障后,雇佣新的 Sequencer,执行 bootstraping 流程来创建新的 TS 和 LS 实例。
- 通过这种方式,事务处理被划分为 ==epochs==,其中每个 epoch 代表着事务管理系统的一代,每一代有自己唯一的 Sequencer 进程。
## 2.4 Transaction Management
### 2.4.1 End-to-end Transaction Processing
- 整体流程:
1. 事务开启:cient 访问 Proxies 之一,获取 read version;
- Proxy 会向 Sequencer 询问 read version,保证==不小于==所有之前已提交事务的 commit version
2. client 从 StorageServers 按 read version 读取所需数据;
3. client 将写入缓存到本地;
4. 提交:client 将事务数据发送给 Proxy,等待 Proxy 的 abort 或者 commit 回应;
- 事务数据里包含了 read 和 write sets(例如 key ranges)
- 如果事务无法提交,client 可以选择从头开始重启事务。
- Proxy 提交事务:
1. Proxy 联系 Sequencer 获取一个 commit version(==大于==之前所有的 read versions 和 commit versions)
- Sequencer 以 100w/s 的速率来递增 commit version
- [ ] *❓commit version 是否会分配重复?*
2. Proxy 将事务信息发送给按 ==range 分区==的 Resolvers
- Resolvers 实现了 OCC 来检测 read-write conflicts。
- 如果没有冲突,则事务可以提交;否则 Proxy 将事务标记为 aborted;
3. 最后,将事务发送给 LogServers 来持久化;
- [ ] *❓按什么规则选择 LogServers?write set 的 ranges?*
4. Proxy 收到所有指定 LogServers 的回复后,将 commit version 上报给 Sequencer(保证对后续事务的 read version 可见),然后回复给 client;
- 与此同时,StorageServers 持续从 LogServers 拉取 mutation logs,应用更新到磁盘。
- [x] *❓如果拉取不及时,按 read version读的时候是否可能读不到*
- 见 2.4.3,client 等待或者尝试其他副本
- 除了 read-write 事务,FDB 也支持**只读事务**和**快照读**。
- 只读事务是 serializiable 且高性能的(借助 MVCC 机制),client 只在本地提交,不用联系 database。大多数事务都是只读的。
- 快照读通过减少冲突放宽了事务的隔离性,例如并发的写入不会与快照读冲突;
> [!question]
> - [ ] 获取 read version 时,是否存在 commit version 小于 read version 的待提交事务,例如commit_versoin=9的已经提交,commit_version=7 的还没提交?
### 2.4.2 Support Strict Serializabilty
- 通过结合 OCC 和 MVCC 实现了 SSI(Serializable Snapshot Isolation)。
- commit version 定义了事务的串行历史,并用作 **LSN**(Log Sequence Number)。
- 因为事务 Tx 可以观察到之前所有已提交的事务,FDB 实现了 strrict serializabilty。
- Previous commit version
- 为了确保 LSNs 之间没有 gap,Sequencer 在返回 commit version (LSN) 时也携带了 previous commit version。
- Proxy 同时将 LSN 和 previous LSN 发送给 Resolvers 和 LogServers,这样他们可以按照 ==LSN 顺序==串行处理事务;类似地,StorageServers 也按照 LSNs 顺序从 LogServers 上拉取数据。
- lock-free 冲突检测算法
- 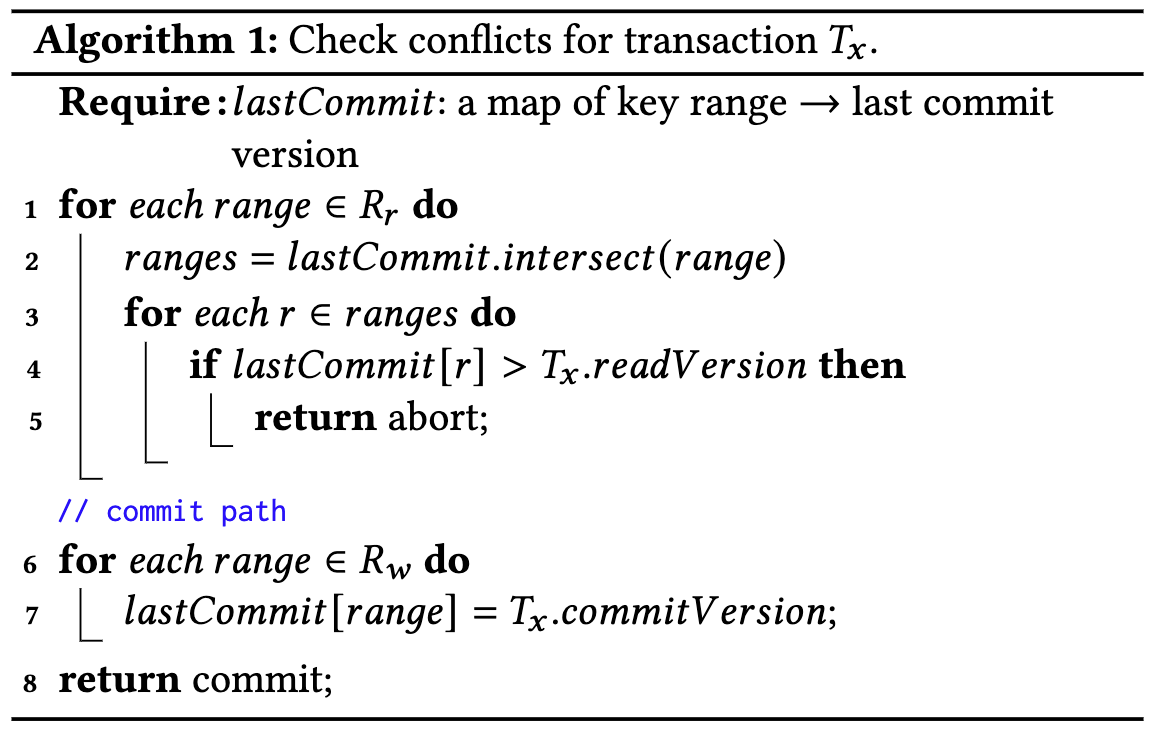
- 每个 Resolver 维护了一个 **lastCommit**,它是已提交事务修改的 key ranges 和 它的 commit version 之间的映射;
- 某个事务修改的 key range <-> 该事务的 commit version
- 使用跳表实现
- 每个 commit 请求包含了两个 sets:
- Rw:modified key ranges,用于更新 lastCommit
- Rr:read key ranges,用于检测冲突,每个 key
- 将当前事务的 Rr 与并发提交的事务的 write set 进行检查(第1—5行),以防止幻读;如果没有 read-write 冲突,则 Resolvers 允许事务提交,并根据事务的 Rw 更新 lastCommit(第6-7行);
- 快照读不包含在 Rr 中,即不检查 read-write 冲突
- [x] ❓*更新完 lastCommit 后,后续提交步骤失败怎么办,比如写 log 失败?*
- false postive,重启事务新分配的 read_version 会大于这个 lastCommit?
- 与 [write-snapshot isolation](https://dl.acm.org/doi/10.1145/2168836.2168853) 不同,FDB 在检测冲突==之前==就分配 commit version,这样分配version 和冲突检测都可以批量处理。
- 一个单线程 Resolver 支持 280 K TPS。
- [ ] *❓为啥提前分配就能做到 batch prcess ?*
- Resolvers 分片和并行检测
- 将整个 key sapce 拆分到多个 Resolvers 上,读写冲突检测可以并行处理。
- 只有所有相关的 Resolvers 都同意(无冲突),事务才可以提交。
- 问题:只有部分同意,导致更新了部分 Rsolovers 上的 lastCommit,冲突检测存在 ==false postive==(与一个 aborted 事务发生了冲突)
- 通常一个事务的 key range 只会落到一个 Resolers 上。实践中问题不大。
- modified keys 在 MVCC window 时间后==过期==(5秒),即 false postive 只存在 5秒。
- Resolvers 负责的 key ranges 可以动态调整,来进行负载均衡。
- OCC 总结:
- FDB 的 OCC 设计避免了复杂的加锁、解锁逻辑,极大简化了 TS 和 SS 之间的交互。
- 代价是:
1. Resolvers 需要额外存储最近的 commit 历史;
2. 无法保证事务一定能提交(冲突后不让提交),这是 OCC面临的挑战。
- 在我们的多租户环境下,冲突的概率非常低(小于 1 %),OCC 运行良好。冲突发生后 client 可以简单地重启事务。
### 2.4.3 Logging Protocol
- 当 Proxy 决策可以提交事务后,将 log message 广播给==所有== LogServers。
- 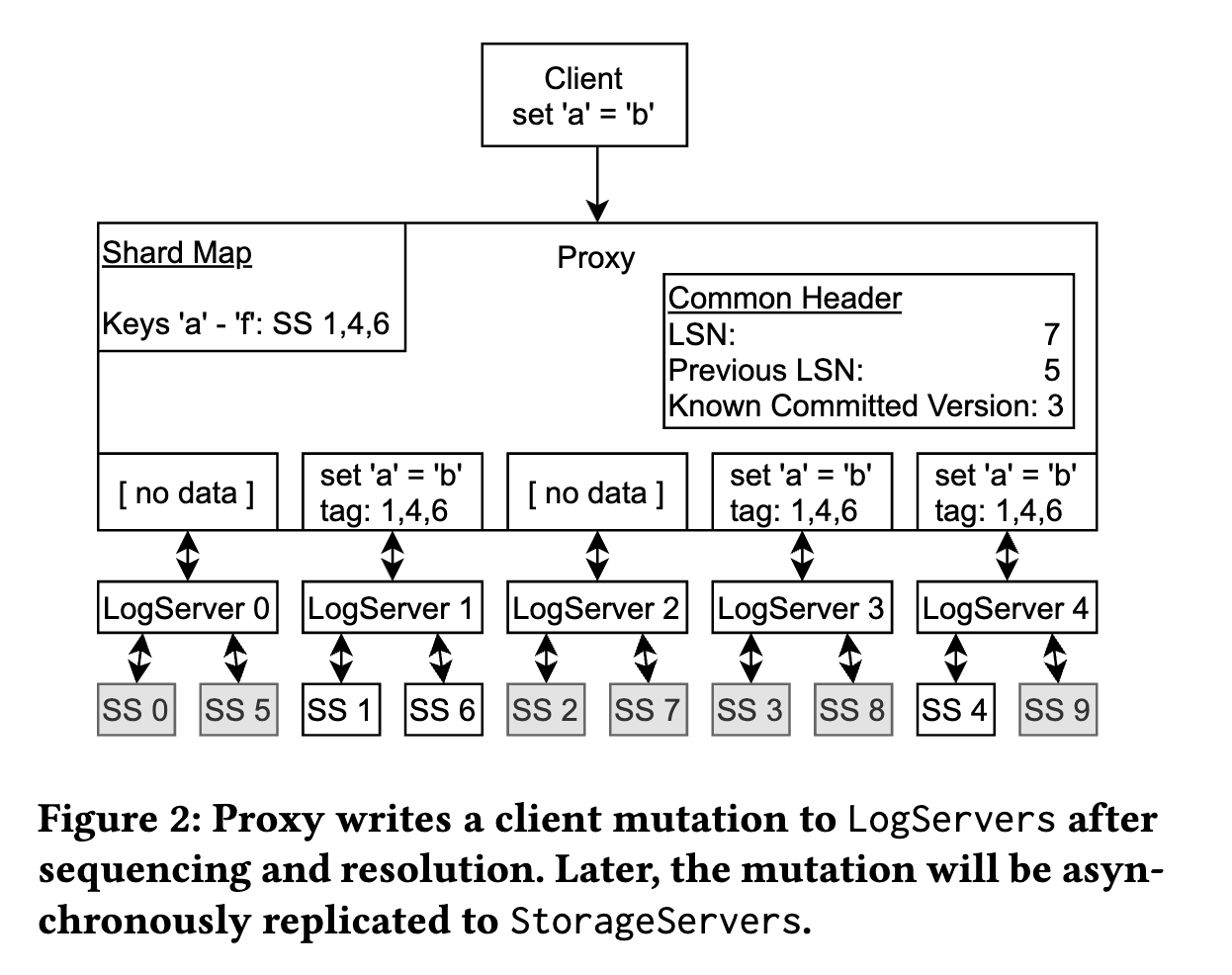
- Proxy 先查询内存中的 shard map,决定哪个 StorageServer 负责 modified key range
- Proxy 将 StorageServer tags(例如图中的1,4,6)附加到 mutation 上
- 每个 tag 都对应一个 preferred LogServer。图中 tag 1 和 6 对应同一个 LogServer。
- **路由顺序**:key range -> storageserver tag -> logserver
- Mutation 只发往 preferred LogServvers(1和4), 以及一个附加的 LogServer 3 来满足==复制==需求。其他的 LogServers 则发送一个**空的** message body。
- log message header 包含了 LSN 和 previous LSN,以及当前 Proxy 的 known committed version(KCV)。
- LogServer 在持久化之后回复给 Proxy,然后 Proxy 会将自己的 KCV 更新为 LSN(如果收到了所有 Logservers 的回应,且 LSN 大于当前 KCV)。
- redo logs 从 LS 传输到 SS 不在 commit 路径上,而是在后台进行。
- StorageServers 在 redo logs 持久化到 LS 之前就开启拉取,以非常低的延迟来提供 multi-version reads。
- SS 和 LS 之间的 log lag 分布:99.9%是 3.96 ms,最大 208.6 ms。
- 提前拉取,意味着会写入 semi-committed updates(例如 LogServer 故障后 recovery 时被 abort 的事务),需要进行==回滚==。
- 当 client 读请求到达 StorageServers 时,所请求的 version 通常是可用的;如果不可用 client 侧会进行**等待**或者尝试**其他副本**。如果两者都超时,则会**重启**事务。
- 因为 log data 已经在 LogServers 上持久化,StorageServers 可以在内存中 buffer updates,==批量持久化==到磁盘上。
### 2.4.4 Transaction System Recovery
^69be6a
- 传统方式:
- 传统的数据库系统经常使用 [ARIES recovery protocol](https://web.stanford.edu/class/cs345d-01/rl/aries.pdf),依赖 WAL 和 周期性的、粗粒度的 checkpoints。recovery 时从 last checkpoint 开始重放 redo log records 将相关的 data pages。使数据库在故障点达到一个 consistent state,崩溃期间的未完成事务可以通过 undo log 进行回滚。
- FDB 实现:非常轻量级、解耦了 redo log 和 recovery。
- 没有 checkpoint,recovery 时不需要重放 redo 或 undo log。
- StorageServers 始终从 LogServer 拉取 logs 并在后台应用,将 redo log 处理跟 recovery 进行了解耦。当检测到故障后,启动 recovery 流程,雇佣新的 TS,在旧的 Logservers 不再需要时结束流程。在所有旧 Logservers 上的数据处理完==之前==,新的 TS就可以接收事务请求,因为 recovery 只需要找出 redo log 的末尾,由 StorageServers **异步**重新应用日志即可。
- 重放 log 不在 critical path 上
- 对于每个 epoch,**Sequencer** 分几个步骤执行 recovery:
1. Sequencer 从 Coordinators 读取之前 TS 的状态(例如 TS 的配置),然后对 coordinated state 加锁防止另一个 Sequencer 进程同时 recover;
2. Sequencer 恢复 TS 之前的状态(包含所有之前 LogServers 的信息,让它们停止接收事务),然后雇佣新的 Proxies,Resolvers 和 LogServers;
3. 当之前的 Logservers 停止,新的 TS 启动后,Sequencer 将当前 TS 的信息写入到 coordinated states 中;
4. 最后 Sequencer 开始接收新的事务提交。
- **Proxies** 和 **Resolvers** 都是无状态的,它们的恢复没有额外工作。
- **LogServers** 保存了已提交事务的 logs,需要保证之前已提交事务的持久化、能够被 SS 获取到。恢复 old LogServers 的本质是决定 redo log 的结尾,即 Recovery Version(==RV==)。
- 回滚 undo logs 本质上就是丢弃 old LogServers 和 StorageSevers 上 RV 之后的数据。
- 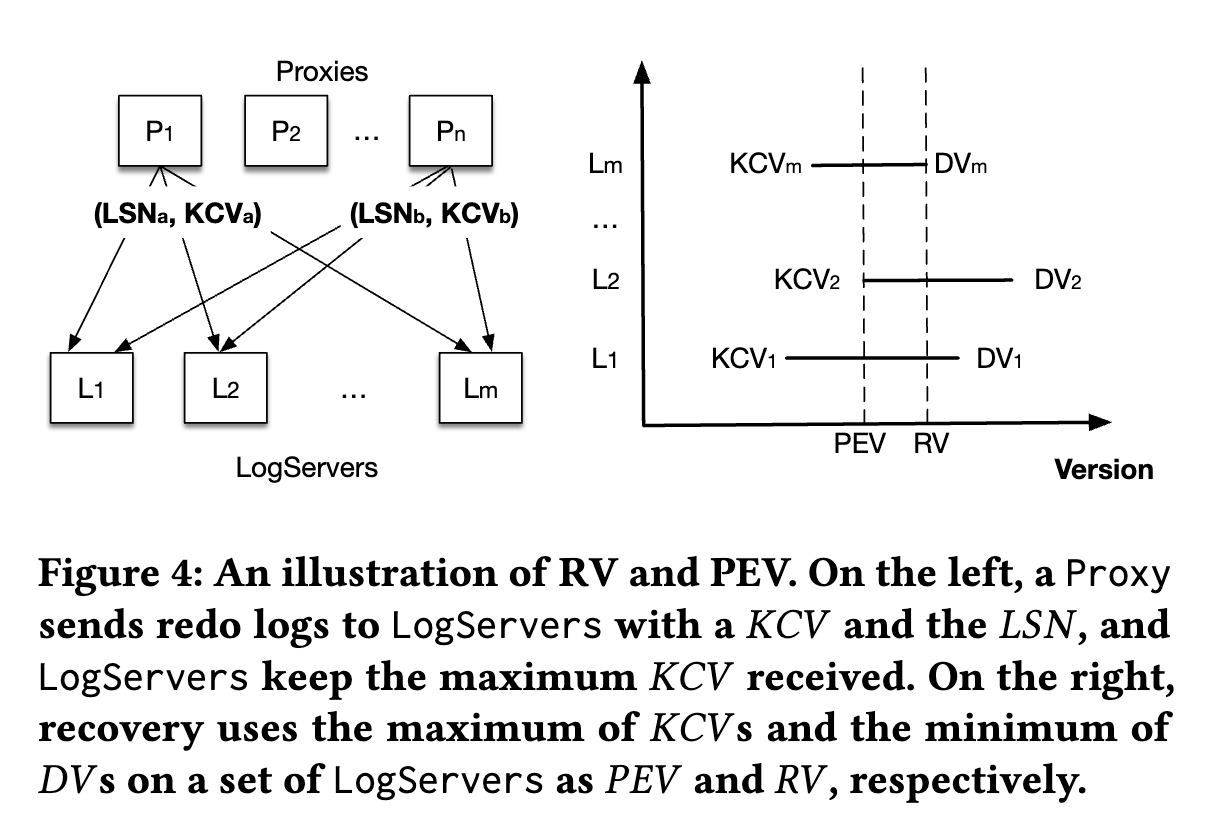
- 图4 展示了 Sequencer 如何决定 RV 的。
- Proxy 给 LogServers 发送请求时会携带它的 KCV,即当前 Proxy 已提交的最大 LSN。每个 LogServer 保存了它收到的最大 KCV 和一个 Durable Version(==DV==)。
- DV:maximum persisted LSN
- [ ] *❓DV 是写入到 SQLite 的位置?*
- recovery 时 Sequencer 尝试停止所有 m 个 old LogServers,每个 LogServer 会回应它的 DV 和 KCV。假设 replication degree 为 k,当 Sequencer 收到超过 m-k 个回复后,就可以确定上一个 epoch 已提交的事务达到了所有 KCV 的最大值,即 previous epoch's end version(==PEV==)。PEV 之前的所有数据都已被 fully replicated。
- PEV 一定存在于 m-k 个 LogServers 内
- 对于当前 epoch,它的 start version 就是 ==PEV + 1==,Sequencer 选择所有 DV 的最小值作为 RV。`[PEV + 1, RV]`区间的日志需要从 old LogServers 拷贝到当前 LogServers 上,以防 LogServers 故障后修复 replication degree。
- 当 Sequencer 接收新事务时,第一个事务是一个特殊的 recovery 事务,通告 RV 给 StorageServers 回滚所有大于 RV 的数据。
- 当前 FDB 的存储引擎是由非多版本的 SQLite,以及内存中的多版本化的 redo log 组成。只有离开 MVCC windows 的(即已提交的)数据才会写入 SQLite,因此回滚只需要==丢弃==内存中的数据即可。
- 然后 StorageServers 再从新的 LogServers 上拉取大于 PEV 的数据。
> [!summary]
> - PEV:数据已经复制到法定数量的副本上,不用再复制
> - RV:min(DV),大于 RV 的要回滚
## 2.5 Replication
- FDB 为不同的数据使用了多种复制策略的组合,来容忍 f 次故障。
- **Metadata replication**
- 控制面的系统元数据,使用 Active Disk Paxos 存储在 Coordinators 上。
- 只要 Coordinators 的 majority 存活,元数据就可以恢复。
- **Log replication**
- Proxy 同步写到 f + 1 个 LogServers 上,只有都成功持久化事务才算成功。
- LogServer 故障触发 [[apple-foundationdb-paper#^69be6a|TS recovery]]
- **Storage replication**
- 每个 shard 即 key range 异步复制到 f+1 个 StorageServers 上,成为一个 ==team==。
- StorageServer 故障后由 DataDistributor 将数据从故障 team 搬迁到健康的 team。
- [ ] ❓*整个 team 都搬迁?*
- storage team 抽象比 [Copyset](https://www.usenix.org/system/files/conference/atc13/atc13-cidon.pdf) 策略更复杂。
- copyset 只能减少**进程级别**的多故障后的丢数据概率,fdb 需要考虑更多维度的故障域 fault domain,如 host 级别、racks、az 等,一个复制组内最多一个进程放在同一个故障域内。
## 2.6 Other Optimizations
- **Transaction batching**
- Proxy 将从 client 接收到的事务请求合并成一个 batch,只向 Sequencer 请求==一次== commit version,一起发送给 Resolvers 进行冲突检测,然后将 batch 中已提交的事务写入到 LogServers。
- [ ] 如果 batch 内的事务彼此有冲突,是否能检测出来?
- batching degree **动态调整**,闲时缩小以提高提交延迟,而当系统繁忙时增加以维持高吞吐量。
- **Atomic operations**
- 支持原子的 add、bitwise add、compare-and-clear 和 set-versionstemp 操作。
- 优势:
- 事务更新数据时不需要先读取,节省了跟 StorageServers 之间的一次交互;
- 也可以消除跟其他原子操作(相同 data item 上的)的 read-write 冲突,但 write-read 冲突仍可能发生。
- 场景:频繁更新的 counter 等场景。
- set-versionstemp:将 key 或 value 的一部分设置为事务的 commit version。
- client 后续可以读取数据的 commit version,提升 client-side caching 性能。
- [fdb record layer](https://www.foundationdb.org/files/record-layer-paper.pdf) 中许多 aggregate indexes 的维护也适用了 atomic mutations。
---
# 3. Geo-replication and failover
- 在 region 故障时提供高可用性的主要挑战:**性能**和**一致性**之间的权衡。
- 同步能提供强一致性,代价是高延迟;异步可以减少延迟(只在 primary region 持久化),但是 region 故障可能会丢失数据;FDB 同时支持同步和异步的跨 region 复制。
- 第三种可能:利用同一个 region 内的多个 AZ ,提供高度的故障独立性(整个 region 宕机的可能性不大)。
- FDB 的设计:
1. 始终避免 cross-region write latencies,类似异步复制一样;
2. full txn durability,像同步复制一样,只要 region 内多个 AZ 不会同时挂掉;
3. region 之间可以快速和完全自动地 failover;
4. 可以手动 failover,具有与异步复制相同的保证
- 提供 ACID 中的 A,C,I,如果整个 region 挂掉则可能出现 Durability 失败;
5. 只需要在 primary 和 secondary region 的 main AZ 有 DB 的完整副本,而非每个 region 多副本;
- 一个集群的两 region 复制布局:
- 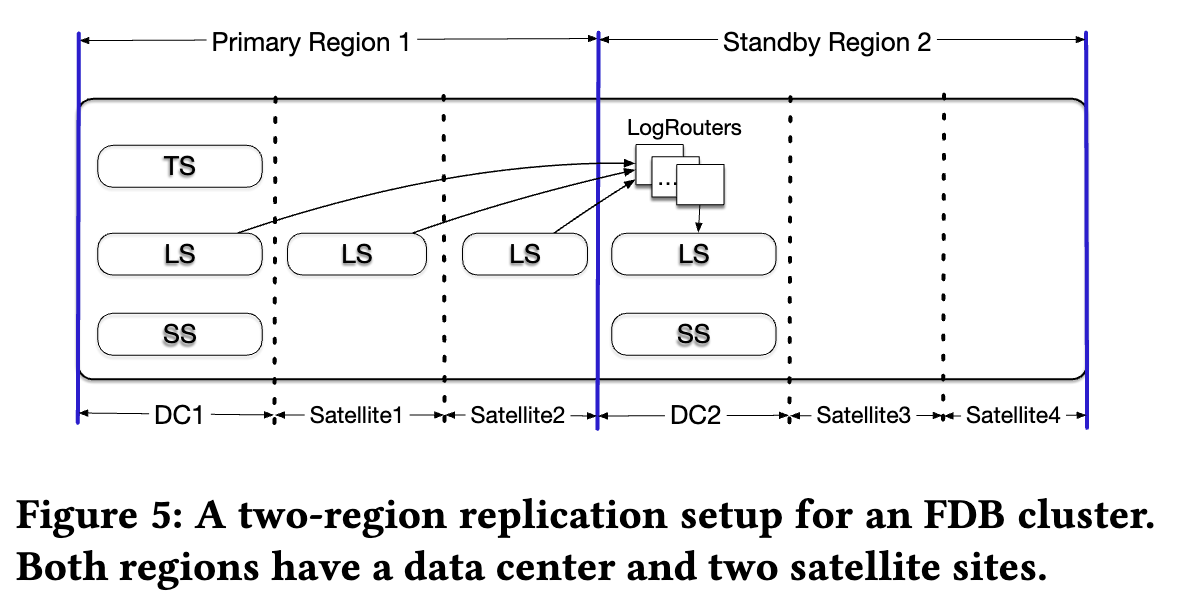
- 每个 region 都有一个 DC 以及一到多个 **satellite** sites。
- satellites 位于 DC 附近的位置,但是故障独立,satellites 需要的资源较少,只需要存储 log replicas;而 DC 则需要 LS,SS ,以及当是 primary 时还需要 TS。
- Control plane replicas:
- 例如 coordinators,部署到三到多个故障域(某些部署下甚至会使用额外的 region),通常至少 9 副本。基于 majority quorums 可以容忍一个 site(DC/satellite)故障和一个额外的副本故障。
- 两个 region,每个 region 一个 DC 两个 Satellite。
- DC1 位于 primary region,包含完整的 TS,LS 和 SS。
- DC2 位于 secondary region 拥有自己的 LS 和 SS 副本;
- 读取:
- 两个 DC 都可以提供读服务,**一致性读**需要从 primary DC 获取 read version。
- 写入:
- 所有的写入都转发到 primary region,由 DC1 的 proxy 处理。然后==同步==持久化到 DC1 的 LogServer 和 primary region 的一个到两个 satellite sites(可配置),避免了跨 region WAN 延迟;然后更新异步复制到 DC2;
- LogRouters 实现 cross-region 数据传输,避免传输相同信息,同一个 log entry 只跨 WAN 传输==一次==,然后传递给 DC2 的所有相关 LS servers。
- failover:
- 当 primary DC 不可用时,集群自动切换到 secondary region。
- DC2 可能缺少最新的 log,从 primary 剩下的 log servers 中进行恢复
- 在 Coordinators 的帮助下,在 DC2 上启动新的 TS。
- 切换后如果 primary region 恢复正常了,集群会再切回来(它的优先级更高)
- Satelite 故障时在某些情况下也会引发 failover,目前是手动决策。
- 不同的 region 可以使用不同的 satelite 配置:
1. 同步存储 log 变更到 region 内优先级最高的 satelite;
2. 同步存储 log 变更到 region 内优先级最高的两个 satelites;
- 如果一个 satelite 故障,可以简单地替换成一个优先级更低的;
3. 类似与2,但只同步等待其中的一个持久化完成(延迟更好);
- 在所有的情况下,如果没有可用的 satelites,则只使用 DC1 的 LogServers。配置 1 和 3 可以允许 1 个 site 故障(DC or satelite),配置 2 可以容忍 2 个。
> [!summary]
> - 只写入到 primary region,再异步同步到其他 regions;
> - region 内的 satellite sites 为 LS 提供独立的故障域;
> - 为何只有 LS 需要, SS 呢,因为 SS 数据可以从 LS 上恢复❓
---
# 4. Simulation Testing
- **Deterministic simulator**
- 所有的代码都是确定性的,没有多线程并发(每个核心部署一个数据库节点)。
- 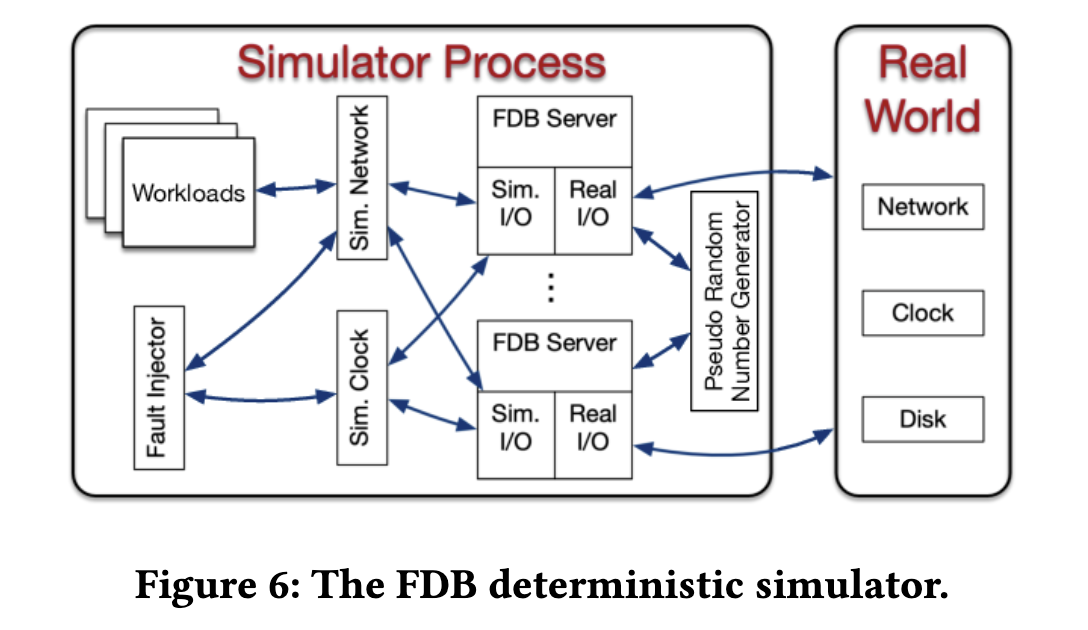
- 所有不确定的源和通信都被抽象化了,包含网络、磁盘、时间和伪随机数生成器。
- FDB 使用了 [Flow](https://github.com/apple/foundationdb/tree/main/flow)编写,一个添加了 async/await 的 C++ 语法扩展,提供了 Actor 编程模型,将 FDB server 进程的不同 actions 抽象成了 actors,由 Flow runtime 进行调度。
- Simulator 进程可以启动多个 FDB servers,它们之间的通信通过一个==模拟网络==进行;相对地,生产环境上的实现为对应的系统调用。
- Simulator 可以启动多个 workloads(也适用 Flow 编写),通过模拟网络跟 FDB servers 通信,workloads 包括故障注入、mock app、配置变更、内部功能调用等。workload 是可组合的,以测试各种功能,并被重用以构建全面的 test cases。
- **Test oracles**
- FDB 使用多种 test oracles 来检测模拟中的故障,大多数 workloads 会利用断言来验证 DB 的约束和属性。
- recoverability 验证:使用模拟的硬件环境。
- **Fault injection**
- FDB simulator 支持注入:
- 机器、rack 和 DC 级别的 fail-stop 故障和重启
- 不同的网络故障、分区和延迟问题
- 磁盘行为(机器重启数据损坏)
- 随机化 event times
- 在代码的许多位置,能够注入了不寻常的行为(但不破坏约定的),补充了网络和硬件层面的故障注入。例如:
- 一个通常会成功的操作返回错误了
- 一个通常很快完成的操作延迟了
- 某个调优参数使用了一个不常见的值等,或者使用一个随机值,保证参数的不同不影响功能的正确性。
- Swarm testing:
- 每次模拟运行使用随机的集群大小、配置、workloads、故障注入参数、调优参数,启用/禁用不同 buggification points 子集。
- [fdb-joshua](https://github.com/FoundationDB/fdb-joshua)
- Conditional coverage macros 模拟平时很难发生的场景,提升代码覆盖率。例如
- 开发人员担心一段新的代码可能很少在缓冲区满的情况下被调用,可以添加行 `TEST( buffer.is_full() )`; ,然后通过分析模拟结果来了解有多少不同的模拟运满足了该条件。如果数量太低或为零,可以添加 buggification、workload 或故障注入功能,以确保该场景得到充分测试。
- **Latency to bug discovery**
- 可以更快发现 bug:
- 离散事件模拟可以比实时运行得快很多
- 如果 CPU 使用率很低,模拟器可以快进到下一个事件
- 可以并行运行多个模拟
- **Limitations**
- 不能用于检测性能问题
- 无法用于测试第三方库和依赖,甚至无法测试未在 Flow 中实现的自己代码。
- 需要在很大程度上避免对外部系统的依赖。
- 关键依赖系统中的错误,例如文件系统或操作系统,或者对其约定的误解,都可能导致 FDB 中的 bugs。
- 例如,由于实际操作系统的约定比预期要弱,已经导致了几个错误。
---
# Lessons Learned
- **Architecture Design**
- 分而治之的设计原则更适合灵活地云部署,使 DB 同时具备性能和扩展性。
- 分离 TS 和 SS,实现了存算分离。可以将 FDB 不同的异构角色放在不同类型的实例上,优化性能和成本;
- 解耦的设计更容易做功能扩展,例如目前在进行的对 RocksDB 的支持。
- 这种设计模式成功地允许频繁添加新功能和能力;
- **Simulation Testing**
- 模拟测试使 FDB 能够缩短引入错误到发现错误之间的延迟,并能确定性地重现问题,从而提供了小团队的开发速度。
- 通过模拟进行严格的正确性测试使FDB极其可靠。
- 增强了==信心==带来了生产力提升。如果没有模拟测试,许多项目将被认为风险过大或太困难,甚至不会尝试。
- 模拟的成功促使我们不断推动适合于模拟测试的边界,通过消除依赖项并在 Flow 中重新实现它们,例如替换 ZK 为 新Paxos实现。
- **Fast Recovery**
- 简化了软件更新和配置变更,使得它们更快速。
- fdb 升级可以通过同时重启所有进程来进行,通常在几秒钟内完成。
- 一个有趣的发现是,Fast Recovery 有时可以自动修复潜在的错误,类似于软件抗衰 ([Software rejuvenation](https://dl.acm.org/doi/10.5555/874064.875631))。
- **5s MVCC Window**
- 选择使用 5 秒的 MVCC 窗口,来限制 TS 和 SS 的内存使用。
- Resolovers 和 StorageServers 的多版本数据是存储在内存中的。
- 限制了事务的大小,从经验来看,对于绝大多数 OLTP 场景 5 秒是足够的。
- 如果事务超过时间限制,说明 client 通常在执行一些低效的操作。
- 对于大事务,client 可以进行拆分。
- [ ] *是否需要检测和拒绝大事务❓*
---
# Notes
- 事务性 KV
- OCC + MVCC 实现 strrict serializability
- **5s** MVCC window
- unbundled 架构
- 不同类型的数据不同的复制策略
- 避免跨 region 延迟
## TODO
- [ ] 理解 DV 的作用和 TS recovery 流程
- [ ] 学习 [Copysets](https://www.usenix.org/system/files/conference/atc13/atc13-cidon.pdf)
- [ ] [fdb record layer](https://www.foundationdb.org/files/record-layer-paper.pdf)
----