# 1. INTRODUCTION
- Bigtable 是一个管理海量==结构化==数据的分布式存储系统。
- simple data model,并允许 clients 动态控制 data layout 和 format。
- 索引:row + column name(任意 strings)
- 用户可以定制 data 的 locality
- 用户可以选择数据放在磁盘还是内存
- 量级:PB 级别数据,几千台机器
- 支持不同的 workloads:面向吞吐的批处理任务和延迟敏感的服务
- 达成的几个目标:
- scalability
- high performance
- high availabilty
---
# 2. DATA MODEL
- 层次:cluster --> table --> tablet --> cell
- **Table**:一个集群包含多个 tables,table 是一个稀疏、分布式的、持久化的多维 sroted map。
- **Map**:根据三个维度索引 map 中的每条数据 / cell :
- (row key:string, column key:string, time:int64) -> string
- **Sorted**:按照 row key 排序
- row key 可以说任意字符串,最大 64 KB,典型值10-100字节
- **Tablet**:连续的 rows 组成 tablet,是分布和 load balace 的单位。
- **column key** 格式:family:qualifer
- 多个 column key/qualifer 组成一个集合即 **column family**
- cf 必须==显示==创建,名字必须是 printable 的
- access control、disk & memory accounting 都在 cf 这个级别进行
- 设计上 cf 不会太多,最大几百个
- cf 创建后就可以在其下使用任意 column key,==不需要定义==
- 使用新 column key 不需要变更 schema
- **timestamp**:相同的数据可以有多个版本,使用 timestamp 作为版本
- ts 可以隐式地由 Bigtable 内部赋值(物理时间的微秒值),也可以由应用指定。
- 按 ts 的==递减==顺序排序,这样最新的在前面。
- 应用可以设置两种不同的 GC 策略:
- 保留最近的 n 个版本
- 最保留最新的版本
- 存储 web pages 的示例表:
- 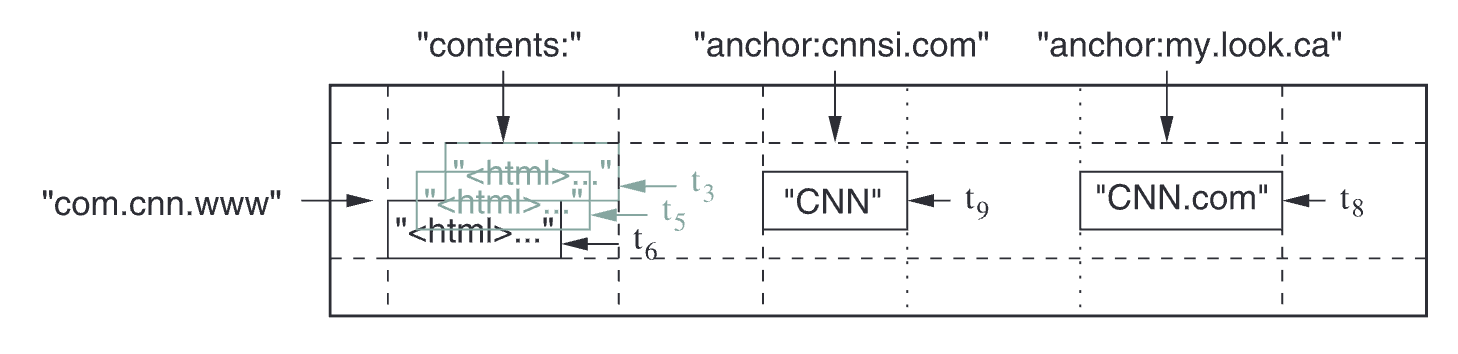
- row key: URL,即 com.cnn.www
- contents 和 anchor 都是 column family
- anchor 下有两个 columns
- contents 列保存网页内容,按照时间有不同的版本
> [!summary]
> - Map 结构:(row key, cf:col, timestamp) -> value
> - cf 需要通过 schema 变更来显式创建,其下的 columns 不需要
---
# 3. API
- Bigtable API 提供的功能
- 创建/删除 tables 和 column families
- 更改 cluster 、table 和 cf 的元数据,例如访问控制权限
- client applications 可以 :
- write、delete values
- 查询单行的 value,或者迭代多行数据
```cpp
// 写操作
Table *T = OpenOrDie ("/bigtable/web/webtable");
// Write a new anchor and delete an old anchor
RowMutation r1(T, "com.cnn.www");
r1.Set("anchor:www.c-span.org", "CNN");
r1.Delete("anchor:www.abc.com");
Operation op;
Apply(&op, &r1);
```
```cpp
// 读操作
Scanner scanner (T);
ScanStream *stream;
stream = scanner.FetchColumnFamily("anchor");
stream->SetReturnAllVersions();
scanner.Lookup("com.cnn.www") ;
for (; !stream->Done (); stream->Next ()) {
printf("%s %s %1ld %s\n",
scanner.RowName(),
stream->ColumnName(),
stream->MicroTimestamp(),
stream->Value()) ;
}
```
- 其他特性:
- single-row 事务
- 可以在一个 row-key 上原子地执行 read-modify-write 操作
- 允许将 cell 用作 [integer counters](https://docs.cloud.google.com/bigtable/docs/create-update-counters)
- server 上执行 client 提供的脚本
---
# 4. BUILDING BLOCKS
- Bigtable 使用的其他 Google 基础设施:
- **Google cluster managment system**
- bigtable 部署在一个 shared machine pool,上面也运行着其他分布式应用
- 依赖该管理系统来调度任务、管理资源、监控、处理机器故障
- **GFS**
- 存储 bigtable 的 log 和 data files。
- data file 的格式是 immutable **SSTable**.
- 每个 SSTable 包含了多个 blocks(默认每个 block 64KB)
- 文件末尾存储 block index; 文件打开时,会将 block index 加载到==内存==中。
- 每次查找只需要一次 disk seek:从内存中的 block index 二分搜索目标 block,然后再读取 block
- 也允许将 SSTable mmap 到内存中,这样读取时不涉及磁盘
- **Chubby**:
- 高可用、持久化的分布式锁服务。
- Paxos 5 副本,master 负责接收请求
- 结构:目录+小文件
- 每个目录可以用作一个 lock,读写文件是原子地。
- client 与 chubby 维持 lease,失效后则释放锁和 open handles。
- bigtable 利用 chubby 来执行多种任务:
- 保证每个一个 active master
- 存储 data 的 bootstrap location
- 发现 tablet servers,检测 tablet server death
- 存储 schemas
- 如果 chubby 长时间不可用,bigtable 就会变得==不可用==。
---
# 5. IMPLEMENTATION
- 三个主要的组件:
- client library
- 一个 master server
- 多个 tablet servers
- 可以动态增删
- **master** 职责:
- 将 tablets 分配给 tablet servers
- 检测 tablet servers 的新增和失效
- 均衡 server 的负责
- GC GFS 上的文件
- 处理 schema 变更(增删 table/cf)
- 每个 **tablet server** 管理一组 tablets (典型地 10-1000个)
- tablet server 处理对 tablets 的读写请求
- 当 tablets 过大时会进行==分裂==。
- client ==直接==跟 tablet servers 通信进行读写
- client ==不依赖== master 来获取 tablet 的位置,大多数 clients 从不与 master 通信。
- 因此 master 负载会很小
## 5.1 Tablet Location
- 使用三级层次结构来存储 tablet location 信息。
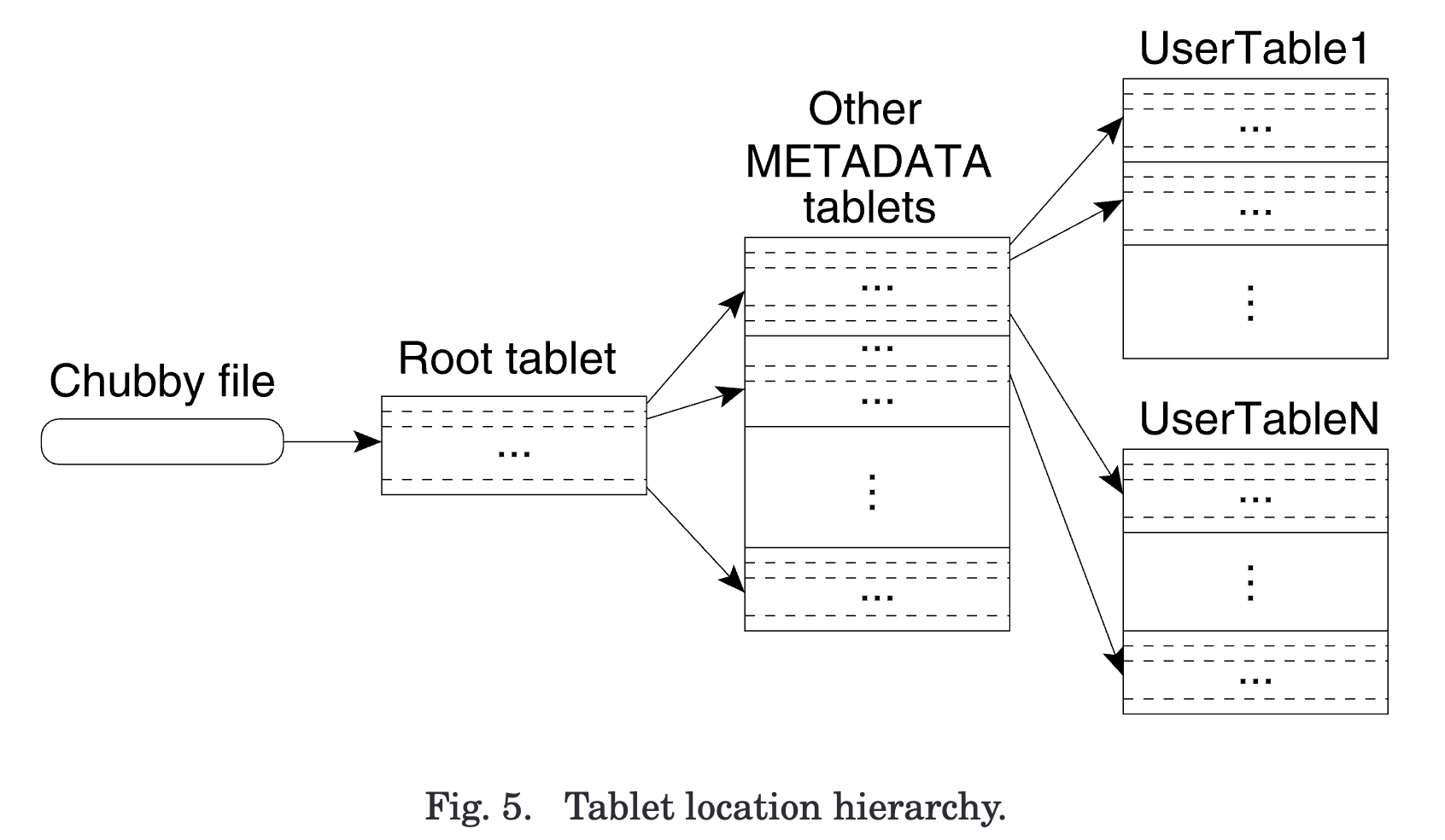
1. 第一级是存储在 chubby 的文件,包含了 **root tablet** 的位置
2. root tablet 内存储了所有 tables 的 METADATA tablets 的位置
- 对应多个 tables,每行数据存储一个 table 的 METADATA tablet 位置
- root tablet ==从不分裂==,只有一个。
3. **METADATA tablets** 存储了一个 table 的所有 tablets 位置
- 对应一个 table
- 每行数据存储了一个 tablet 的位置信息
- row key 是 table id + tablet end row
- 每行占据约 1KB,存储在==内存中==,不需要访问 GFS。
- [ ] ❓*一个 table 可以有多个 METADATA tablets?并且可以分裂?*
- client library 遍历 location 层次来定位 tablet,并进行==缓存==。
- **prefetch**:每次 METADATA 时读取多个 tablets 信息。
## 5.2 Tablet Assignment
- 一个 tablet 一次最多分配给一个 tablet server。
- master 跟踪存活的 tablet servers 、已分配以及未分配的 tablets。
- **tablet 分配**:
- 对于未分配的 tablets,master 寻找有足够空间的 tablet server,向其发送 ==tablet load request== 进行分配。
- 分配失败的 case:server 在收到 load 请求之前,master 被 failover了。
- server 只接受 current master 的 load 请求。
- 只要分配成功,就可以假定 tablet 一直由该 server 负责,直到 server 死亡或者主动通知 master unload 了。
- Bigtable 使用 chubby 来跟踪 tablet servers。
- tablet server 启动后在特定的 Chubby 目录中创建并获取一个唯一命名文件的独占锁,master 监控该目录来==发现== tablet severs
- 当 tablet server 失去独占锁后,将==停止服务==它之上的 tablets
- 当命令文件存在时,tablet server 会尝试重新获取独占锁;不存在则主动退出并释放锁,让 master 可以快速重新分配 tablets。
> [!NOTE]
> - 文件代表 tablet server 是否离开集群,未来不再提供服务;
> - 独占锁表示 tablet server 是否存活,它之上的 tablets 是否还正常服务;
> - 锁是加上 tablet server 的文件之上的
- master 负责检测 tablet server 是否能正常服务 tablets 并尽快重新分配
- 检测手段(询问或不可达):
1. master 向 tablet server ==询问== 它独占锁的状态,tablet server 报告说它失去锁了
2. master 一段时间内无法连接到 tablet server
- 检测异常后, master 尝试获取该 server file 的独占锁,获取成功则==删除==文件,将 tablets 标记为未分配。
- master 获取锁后,防止 tablet server 重新获取锁后恢复;
- 删除后,该 server 未来无法继续提供服务,不会再抢占 tabets,造成冲突;
- 如果 master 跟 chubby 的 session 失效,则 kill 掉自己。
- master 在做出变更前,需要先发现当前 tablets 的分配情况。启动后会执行如下步骤:
1. 向 chubby 获取独占的 **master lock**(避免多个 master 实例并发工作)
2. master 扫描 chubby 上 的servers 目录,发现 live servers;
3. master 向每个 live servers 询问他们负责的 tablets,并且通告自己是 current master;
- *servers 只接收来自 current master 的 load 请求*
4. master 读取 METADATA table 来获取 table 的所有 tablets,与步骤 3 的进行对比确定还未分配 的 tablets
- 复杂性:扫描 METADATA table 时,METADATA tablets 可能还没有被分配
- 因此执行前,如果步骤 3 没发现 root tablet,则将 root tablet 添加到 unassigned set 中,保证 root tablet 的分配,从而能扫描出 METADATA tablets
- tablets 集合的变更:
- 变更来源:
- table 创建/删除
- tablet 合并
- tablet 分裂
- master 能够跟踪这些变更,除了分裂其他都是由 master 来发起的。
- 分裂是由 ==tablet servers== 发起的。
- tablet server 为新 tablet 向 METADATA table 提交一条分裂记录信息,并通知 master。
- 如果通知失败,master 发送 load tablet 请求,tablet server 会告知已分裂。
- master 发送的 load 请求中的 tablet row key 范围与 tablet server 的不匹配
- 例如 master 要求 load 负责 `[a, e)` 的 tablet,实际上在 MEATADATA 中该 tablet 当前只负责 `[a, c)`
- [ ] ❓ *新分裂出来的 tablet 初始是 assgined 的吗*
> [!summary]
> - servers 目录下的 server file 列表代表了 tablet servers;
> - server file 的独占锁表示了是否负责了 该 server 之上的 tablets
## 5.3 Tablet Serving
- tablet representation
- 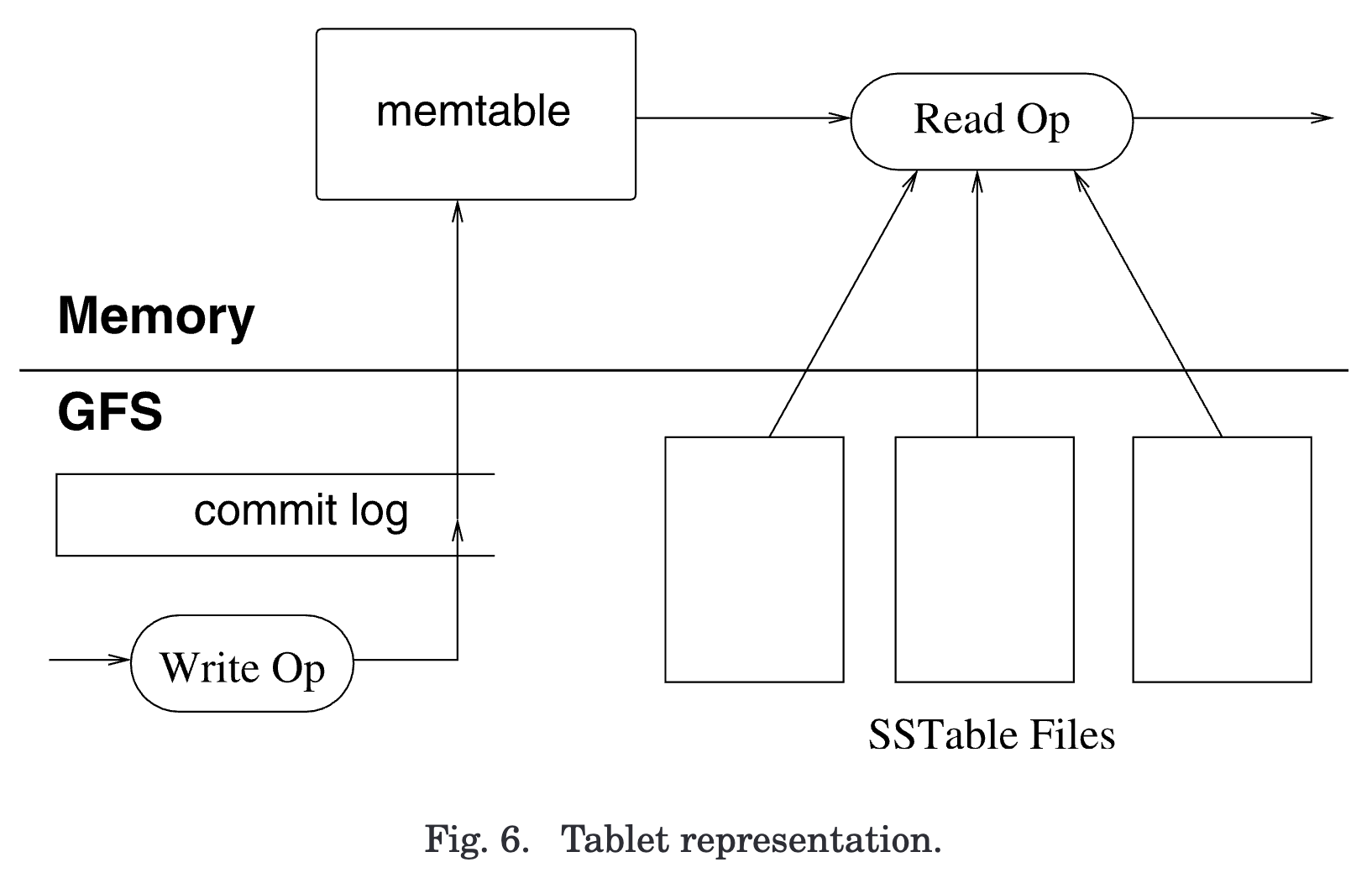
- 三个存储组件:memtable、commit log 和 SSTable
- 持久化状态即 commit log 和 SSTable 存储在 GFS 中
- memtable: tablet server 内存中的 storted buffer
- 更新操作提交到 commit log 中( redo log),同时也按行记录到 memtable 中。
- 旧的更新记录在 immutable SSTable files 中
- 加载 tablet
- tablet server 从 METADATA 中读取 tablet 的元数据,包含了
- SSTables 文件列表
- redo points,指向了包含了该 tablet 的 commit logs
- server 将 SSTables 的索引加载到内存,并根据 redo point 应用 redo log 重建 memtable
- 写操作:
1. server 收到写请求后先作有效性检查和认证
- 认证:从 chubby 读取允许写的 writers 列表
2. 将 mutation 写入 commit log
- 使用 group commit 来提升 small mutations 的吞吐
3. commit 后插入 memtable
- 读操作:
1. 检查和认证
2. 在 SSTables 和 memtable 的 merged view 之上进行读取
- tablet 分裂、合并和 compaction 期间,读写都可以正常处理。
## 5.4 Compactions
- **minor compaction**
- 即 flush,当memtable size 到达阈值后冻结,转换成 SSTable 写入到 GFS。
- 两个目标:
- shrink 内存占用
- recovery 时减少 replay 的数据量
- **merging compaction**
- 后台读取少量 SSTables 和 ==memtable==,写入到新的 SSTable。
- 当 comacption 完成后,就可以丢弃 input SSTables 和 memtable。
- **major compaction**
- 将==所有== SSTables 重写成==一个==。
- 输出将不再包含 deleteion entries。
- GFS locality optimization
- 写入文件时,GFS 尝试将一个副本的数据放置到跟 writer 相同的机器上
- 当读取 GFS 文件时,从最近可用的副本上进行读取。
- 相同机器上的话,相当于读取 ==local disk==。
## 5.5 Schema Management
- schemas 存储在 Chubby。
- chubby 提供了 atomic whole-file writes 和小文件的一致性缓存。
- 例如:删除 table 的 cf,通过原子地 rewrite schema 文件来实现。
---
# 6. REFINEMENTS
- **Locality Groups**
- 每个 column family 被分配给一个 client-defined locality group
- locality group 是一层抽象,可以让 clients 控制数据的存储布局。
- compaction 时会为每个 tablet 的不同 locality group 生成单独的 SSTable。
- 通常将不一起访问的 cf ==分隔==到不同的 locality group 中,使读取更高效。
- 可以将某个 locality group 声明为 ==in-memory== 的
- 适用于小数据量且经常访问的,例如 METADATA table 的 tablet-location cf
- **Compression**
- client 可以控制 locality group 的 SSTables 是否压缩,以及使用什么压缩格式
- 压缩粒度:SSTable block,大小可调整(locality group 级别的参数)
- 好处:可以读取 SSTable 的一小部分,而不用解压整个文件
- **Caching for Read Performance**
- tablet server 使用了两级 cache
- scan cache:缓存 kv pairs
- block cache
- **Bloom Filters**
- 为某个 locality group 的 SSTables 启用 bloom filters
- **Commit-Log Implementation**
- 问题:如果每个 tablet 一个 单独 commit log,则导致有大量文件并发写入 GFS。
- 写入不同物理文件,大量 disk seeks
- 修复:==每 tablet server== 一个 commit log
- 新问题:recovery 将变得复杂
- 新 tablet server load tablet 回放 log 时,里面混合了大量其他 tablets 的数据,读放大很大,尤其很多个 tablets 同时 load 时
- 读去重:按照 (table, row name, log seqno) ==排序== commit log entries,排序后针对某个 tablet 的 entries 将变得连续,读起来更高效。
- 将 log file 按 64MB 分区,并行排序,tablet server 需要 recover 时由 master 协调排序。
- 每个 server 有两个 log writing threads,对应两个 log file,同时只有一个是活跃的
- 防止 GFS performance hiccups
- **Speeding Up Tablet Recovery**
- unload tablet 时,tablet server 对 tablet 进行 minor compaction,另一个 tablet server load 时就无需再回放 log entries。
- 两次 minor compaction:upload 前、停止服务真正 unload 时
- **Exploiting Immutablity**
- 为了减少读 memtable 时的竞争,每个 memtable row 是 copy-on-write 的,允许读写并行进行。
- SSTables 是 immutable 的:
- Master 扫描 METADATA table 通过 GC 来删除过时的文件
- 快速分裂 tablet,child tablets 与 parent ==共享== SSTables,不用拷贝一份新的
> [!summary] Locality Group
> - 不同的 local group 的 SStables 是隔离的;
> - local group 级别的配置:
> - 数据放置在 in-memory
> - SSTable block size
> - bloom filter
---
# LESSONS
- 大型分布式系统很容易遭遇各种类型的故障
- 不仅仅是许多分布式设计假设的网络分区和 fail-stop 故障
- memory 和 network corruption
- lock skew
- hung machines
- 使用的其他系统的bug
- 延迟添加新特性,直到明确这些新功能将如何使用。
- 合适的系统层面的监控
- RPC traces
- 向 chubby 注册每个 cluster,跟踪 clusters,发现它们的规模、部署版本等
- 最重要:==simple designs==
---
# Conclusions
- 2005年4月生产使用,2006年8月60个工程在使用 bigtabl。
- 新特性:
- secondary indices
- 跨 DC 复制,multiple master replicas
- deploy as a service
- resource-sharing issues
---
# Notes
- 数据模型:
- (row_key, cf:col, timestamp) <-> value
- tablet 元数据也存储在 tablets 上
- 路由信息
- 持久化状态信息(SSTables,commit logs + redo points)
- chubby server list file + 独占锁,管理 tablet servers 是否可服务 tablets