# Abstract
- RocksDB 的设计例如 data 和 log files 的访问模式,使得 append-only 的 DFS 很适合作为其底层存储;
- Tectonic File System
- Tectonic 主要的性能问题: metadata 的开销和尾延迟
---
# 1. Introduction
- 分离存储的原因:
- 高效:CPU 和 storage 可以独立配置
- 网络带宽增长:至少 25Gbps,常见 50Gbps 或者 100 Gbps
- 利用 DFS 的可靠性
- 提高 in-region availabilty
- 减少 cross-region data transfers
- 在 DFS 上运行 RocksDB 的主要挑战:
1. 相比 local SSDs 延迟变大
2. 容错需要数据冗余,带来存储空间和 SSD 耐久的开销
3. 存储分离后,多个节点可能会访问相同的 RocksDB 目录
- failover 发生后,必须阻止之前节点的访问
4. RocksDB 库需要处理 remote IO 的行为(失败、超时等)
---
# 2. Background And Motivation
- Why disaggregated Storage
- local SSDs:
- CPU 和 storage 总是不均衡。
- 分离后:
- 存储从 shared pool 按需分配。
- 最大化 CPU 和 storage 的使用率
- Why Still RocksDB
- 目标场景:bounded by space usage 而非 bounded by I/O。
- Generality
- 容易从 local storage 迁移,并且两者可以同时存在,随时切换
- LSM 适合实现 disaggregated storage
- Why Tectonic File System
- RocksDB 的 data 和 log 文件都是==顺序写==,因此不需要支持随机写的方案(随机写存在额外开销和复杂度)
- Tectonic 的假设:immutable data chunks 更高效
- 历史经验:BigTable,HBase,Spanner 都是建立在 append-only 的 DFS 之上
- 需要的 API primitives:
- data 可以组织成带名字的文件
- 文件以 append-only 的形式构建,但读取支持使用 offets
- 文件可以组织成目录或 buckets
- 使用 Tectonic 的附加收益
- 减少副本数:Tectonic 保证了高可用
- **快速 failover**:重建副本不用 data copying
- 简化管理:不用管理 SSDs
- **存储共享**:offload 备份、compaction 和验证等操作到其他节点
- When Not To Disaggregate
- 应用需要评估是否能容延迟和吞吐的下降
- Tectonic 的数据冗余带来的额外空间
- Tectonic 是个复杂系统且有很多依赖,一些基础软件可能想尽可能减少依赖
---
# 3. Architecture Overview And Main Challenges
## 3.1 Architecture
- Before: 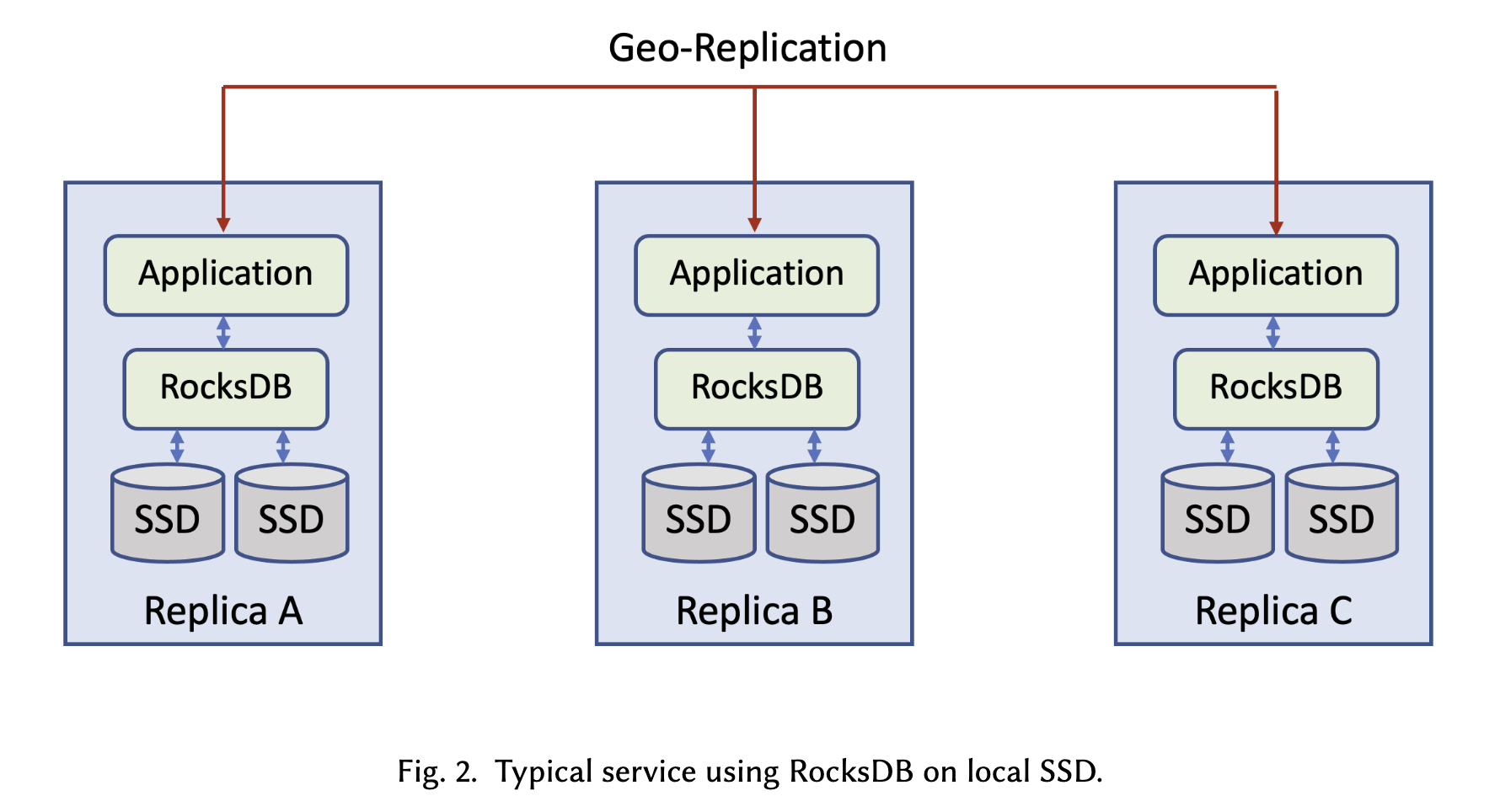
- After: 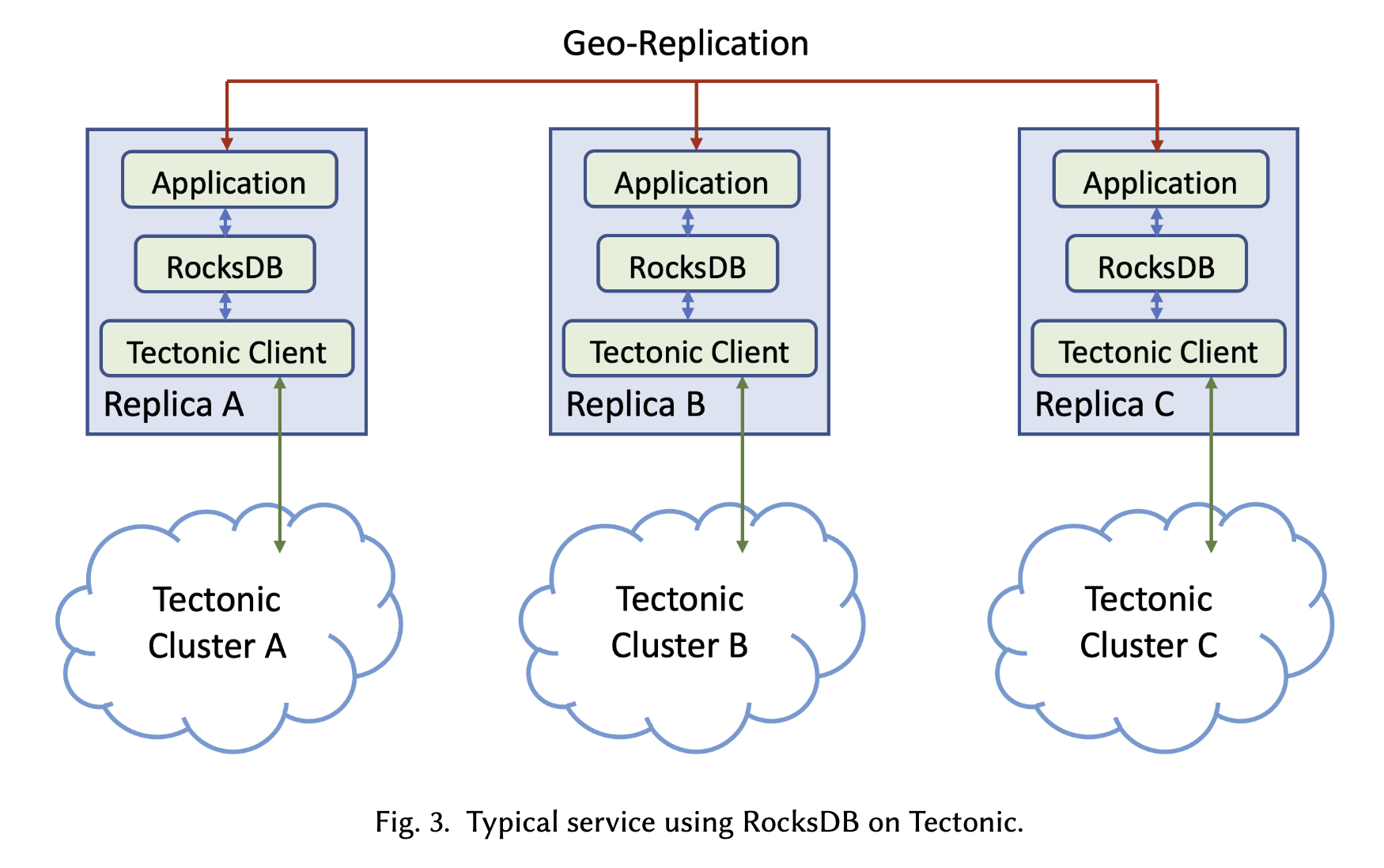
- Tectonic clusters 是 data center local 的,因此应用需要继续使用它们的 geo-replication logic。
- 在 Tectonic 上运行 RocksDB 的关键修改:
- 支持对 Tectonic 的文件读写(开发了一个新的 plugin)
- 目录名需要添加 namespaces 来进行隔离
- Tectonic 保证对目录的独占访问
- Tectonic 添加 GC 功能来删除 RocksDB 目录
- 一个 RocksDB 实例是一个 RocksDB 目录的 **single writer**,因此可以进行 cache 数据,没有一致性问题。
## 3.2 Challenges
- **Performance**
- 因为增加了网络跳数。目标:
- 小的 point queries(如 Put/Get),P99 小于 5ms
- MuliGet 和 iterator,P99 几十ms
- **Provide Redundancy With Low Overhead**
- 数据的复制或纠删编码发生在Tectonic客户端内部。
- SST 和 WAL 文件使用==不同的复制模式==
- **Data Integrity With Multiple Writers**
- failover 后,保证老的 node 无法再修改数据
- **Preparing RocksDB for Remote IO**
- 处理新的 IO 错误
------
# 4. Addressing The Challenges
## 4.1 性能优化
- **优化 IO Tail Latency**
- 当怀疑某个 node 很慢时,切换到其他 node
- 使用了以下三种技术:
- Dynamic Eager Reconstructions
- 发起第一个 read 一定延迟之后,有条件地发起第二次 read,使用最早返回的。对于纠删码数据,第二次读取是一个涉及多个并行IO的重建过程,因此资源消耗更大,需要跟踪集群的读延迟分布来限制
- Dynamic Append Timeouts
- if a timeout occurs, we fail the inflight append, take note of the last succeeded size in our metadata, select a new set of storage nodes, record it in our metadata, and retry on a fresh set of storage nodes.
- This hides the slowness caused by a smaller subset of the fleet
- Hedged Quorum Full Block Writes
- We split the writing of blocks into two phases: permit acquisition andpayload transfer.
- 基于资源可用率先挑选一批节点
- 这几个优化整体感觉跟 DFS 强相关
- **RocksDB Metadata Cache**
- ==缓存 fs 的元数据==,如目录下的文件列表,文件大小。
- **RocksDB Local Flash Cache**
- SecondaryCache:local flash + DRAM
- **RocksDB IO Handling**
- DFS 的IO特点:类似于 HDD,读写延迟高,批量写入友好
- 设置更大的 compaction read size 和 compaction write buffer size
- 基于历史统计配置 initial readahead size,最大size可配置
- **RocksDB Parallel IO**
- MultiGet,并行读取多个 data blocks
- **RocksDB Compaction Tuning**
- 很少有用户在迁移到 Tectonic 时需要更改压缩策略
- 一个可能影响性能的 compaction 设置可能是 target SST file size
- 根据经验,除非小于 64 MB,一般影响很小
## 4.2 Redundancy with low overhead
- 对于SST文件,使用低开销的高 durable 编码,因为它们消耗了大部分空间和写入带宽
- 对于 WAL 和 其他日志文件,小 block 追加写的 tail latency 需要足够低,使用 R5 encoding。
- ==使小型写入高效化==
## 4.3 Data Integrity WIth Multiple Writers
- cooperative ==IO Fencing== protocol
- 递增的 fencing token
- 每次操作都携带 token,更大的 token 才能操作成功
## 4.4 Preparing RocksDB for remote calls
- Differential IO Timeout
- remote IO 更慢,==不同类型的 IO 超时不同==
- 用户请求的:通常 1 秒内
- flush/compaction:可以更长
- RocksDB 参数:request deadline
- ==Failure Handing==
- 在之前,重要的 IO 失败 会导致RocksDB 会进入只读模式。
- DFS 失败更频繁,并且是短暂的、可恢复的。
- 支持从短暂的错误中恢复
- flush/compaction 出错可重试,不影响用户写入
- 写 WAL 出错则暂时停写,并通过 flush memtables 来从错误中**恢复**
- IO Instrumentation
- storage stack 更复杂,开发更多工具来提升可视化和方便定位问题
- Utilities
- tools 适配 DFS
---
# 5. PERFORMANCE BENCHMARK
## 写吞吐

- 随机性:Tectonic 单个文件的处理速度有限,这会导致一些瓶颈。调整RocksDB compaction 参数可以解决这些瓶颈。
## 读性能

- 测试场景:每个读需要至少一次 IO。
- 由于 Tectonic client 允许的limited concurrent outstanding I/Os 有限,无法通过使用Tectonic 的更多线程来获得更高的吞吐量
---
# 6. Application Experiences: ZippyDB
- ZippyDB: 分布式 KV 存储服务。
- Multi-Paxos,Geo-replication
- 存储引擎为 RocksDB
## 6.1 Handling non-RocksDB files
- paxos 复制日志:
- 所有文件操作使用 RocksDB 的 storage interface
- 之前 log 写入到 page cache 就 ack,现在写入到 ==shared memory buffer==
- small appends with striped erasure encoding,保证高可用和低开销
- 最终效果:用户写入延迟未受到 Tectonic 影响
## 6.2 Building New Replica
- in-region replica rebuild
- 将数据拷贝到新 replica,例如处理 host failure 或 balance
- 利用 Tectonic 的 fast file copy 操作(将新文件的metadata 指向相同的物理数据)
- 50分钟 -> 1 分钟
- cross-region rebuild
- 仍然需要慢拷贝
## 6.3 Verifying Correctness And Perfomance
- 问题:平滑迁移
- Forward mirroring:在线使用 local-ssd,同时异步 copy 到 Tectonic HDD。
- Mirror based recovery:故障后从 Tectonic 中恢复
- We start to use the DB while still copying data from Tectonic into the local file system.
- Reverse mirroring:在线使用 Tectonic,异步拷贝到本地。验证可靠性和性能后,彻底抛弃本地。
## 6.4 Files Garbage Collection
- compute node 挂掉后残留的 dead DB instance,通过后台 GC 回收。
## 6.5 Wins With RocksDB on Tectonic
- 空间使用率:local SSD 是 35 %,Tectnoic 是 75%
- 服务不可用的时间缩短(replica rebuild 更快)
---
# 7. OnGoing Works And Challenges
## 7.1 Secondary Instances
- 多个 RocksDB 实例访问共享的数据。
- single-writer,multi-readers 模式。
- secondary 实例回放 primary 生成的 log files
## 7.2 Remote Compaction
- compaction offload 到专用的 host 上,避免跟 primary service 竞争资源
- 好处:
- primary service 服务质量更高
- 管理多个==跨 DB 的 compactions==
- 调度和优先级
## 7.3 Tiered Storage
- 结合 SSD 和 HDD, 不同的 SST files 放到不同的存储介质
- 通过观测数据插入后的时间来预测数据冷却,但在更复杂的预测方面仍然存在挑战。
---