# ABSTRACT
- GFS:分布式的文件系统
- 运行在廉价的商业硬件上,具备容错能力
- 高并发、高性能
- 最大集群:
- 几百 TB
- 几千块磁盘
- 一千台机器
- 几百个 clients
---
# 1. Introduction
- 设计来源于Google 当前和预期的应用 workloads 和 技术环境,与之前其他文件系统的假设有很大不同。
1. 组件故障是种常态,而非例外
- 系统必须具备持续监控、错误检测、容错和自动恢复
2. 文件很庞大,体现在单个文件很大(几GB)以及文件数量上(几亿个KB级别的文件)
- 需要对设计假设和参数进行重新审视,如 I/O操作和块大小。
3. 大多数文件只有==追加写==,而非覆盖写。
- 实践中几乎不存在随机写。
- 文件一旦写完后,也==只有读操作==,且经常是顺序读。
- 性能优化和原子保证的重点考虑追加操作,*在 client 缓存数据块不再重要❓*
4. 应用和文件系统的 API 共同设计(co-design),提升了灵活性,使整体系统受益。
- 例如放宽了 GFS 的一致性模型,来极大地简化文件系统,减轻给应用程序的负担。
- 多 clients 可以并行地==原子追加==写入,它们之间不需要额外的同步。
---
# 2. Design Overview
## 2.1 Assumptions
- 构建在廉价的商业硬件上,经常故障。
- 适量的大文件。预期:
- 几百万的文件,每个典型 100 MB 或者更大
- 多GB级别的文件很常见,需要高效管理
- 支持小文件,但不需要优化
- workloads 主要包含两种类型的 **read**s:
- large streaming reads
- 单次操作读取几百 KB、1 MB 或者更大
- small random reads
- 任意 offset 读取几 KB
- 性能敏感的应用通常会对 small reads 进行 batch 和 sort
- workloads 也包含了许多大的、顺序性的追加**写入**
- 也支持随机小写入,但不需要做到高效;
- 高效地==并发追加==写入相同文件
- 原子性 + 最小化同步开销
- 持续性地==高带宽==比低延迟更重要
## 2.2 Interface
- GFS 提供了类似 file system 的接口,尽管没有实现类似 POSIX 的标准 API。
- 文件按目录结构组织,通过路径名定位
- 支持常用的操作,如 create,delete,open,close,read 和 write files。
- GFS 还额外提供了 snapshot 和 record append 操作。
- snapshot:低成本创建一个文件/目录的拷贝。
- record append:允许多个 clients 并发追加写入到同一个文件。
## 2.3 Architecture
- 一个 GFS cluster 由==一个 master== 和多个 chunkservers 组成。
- 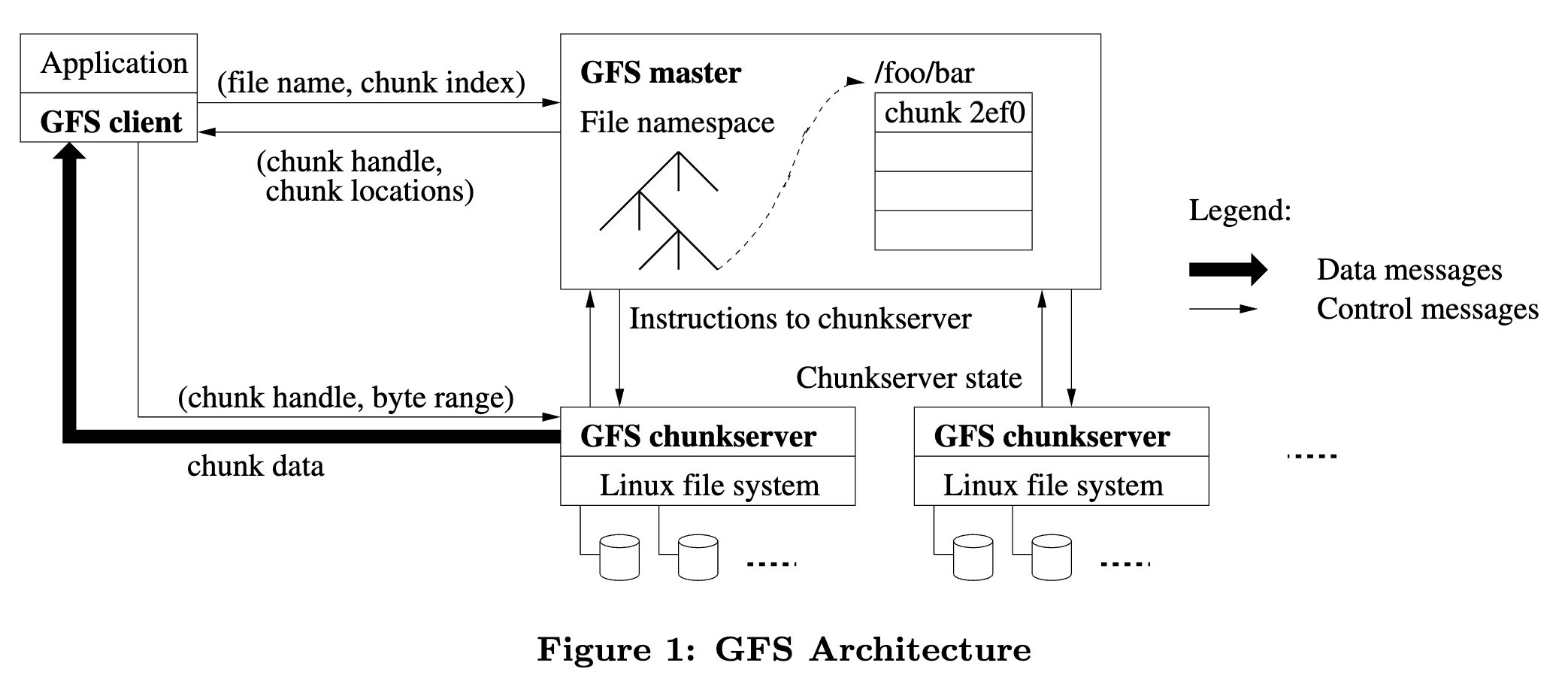
- 文件被切分为固定大小的 **chunk**s。
- 每个 chunk 通过一个不可变的、全局唯一的 64 位 ==chunk handle== 来标识。
- chunk handle 在 chunk 创建时由 master 进行分配。
- chunk 以 linux file 的形式存储在 chunkserver 的本地磁盘上,读写 chunk 时指定 chunk handle 以及 byte range。
- 为了可靠性,每个 chunk 会==复制==到多个 chunksservers。
- 默认三副本。用户可配置。
- master 负责 fs 元数据的维护以及系统管理。
- 元数据包括了 namespace、访问控制信息、文件到 chunks 的映射、chunk 的 locations。
- master 还控制系统范围的活动:
- chunk lease 管理
- orphaned chunks 的回收
- chunk 在 chunkservers 之间的迁移
- master 定期通过心跳跟每个 chunkserver 通信,发送指令和收集状态信息。
- GFS client 代码链接到应用程序中,它实现了 fs API,跟 master 和 chunkserver 进行通信、读写数据。
- client 跟 master 的通信只涉及元数据操作,所有数据层面的通信会直接发往 chunkservers。
- client 和 chunkserver ==都不会缓存== file data。
- client 缓存收益很小,大多数应用程序流式读取大文件或工作集太大而无法缓存。
- *流式只读取一遍,缓存没意义。*
- chunkserver 不缓存是因为已经有了 linux 的 buffer cache 。
## 2.4 Single Master
- 单 master 优势:
- 简化设计
- 使用 global knowlegde 作一些复杂的决策,例如 chunk 放置、复制
- 必须尽量减少 master 在读写流程中的参与,以避免其成为瓶颈。
- client 读写不经过 master;只向 master 询问连续哪个 chunkserver,并缓存该信息。
- 读流程示例:
1. client 使用 fixed chunk size 将目标 file name 和 byte offset 翻译为文件内的一个 chunk index;
2. client 向 master 发送请求(包含了 file name 和 chunk index),master 回应对应的 chunk handle 和 replicas's locations;
- client 以 filename + chunk index 作为 key 缓存该信息
3. client 向其他一个 replica 发送请求,大概率是最近的一个;
- 请求包含了 chunk handle + chunk 内的 byte range
- 后续对相同 chunk 的读取都不再需要 master(cache 失效前),client 通常会在一个请求内==询问多个==临近的 chunks。
## 2.5 Chunk Size
- Chunk size 是关键设计参数之一,选择了使用 ==64 MB==。
- 比通常的文件系统块大小要大很多。
- **lazy space allocation**:
- 每个 chunk 存储为一个普通的 linux file,按需扩展。
- 优势:避免了由于内部碎片化而浪费空间。
- *❓内碎片是指分配了未实际使用 ?*
- 大 chunk size 的**好处**:
1. 减少了 client 跟 master 的交互,读写相同 chunk 只需要一次请求 master;
- 尤其是顺序读场景
- 即使是 small random reads,TB 级别的工作集可以缓存所有的 localtions;
2. chunk 越大,在同一个 chunk 上操作的次数越多,能复用到 chunkserver 上的 TCP 链接,减少网络开销
- *❓减少了建立链接的开销?*
3. 减少了 master 上的元数据,可以全部放在内存里。
- 大 chunk size + lazy allocation 的**坏处**:
- 小文件的 chunks 个数很少,例如只有一个。如果频繁读取这个小文件,会导致某些 chunks 成为==热点==。实践中这个问题并不严重,大多数场景都是顺序读大文件。
- *chunks 过少无法分散热点*
- 解决方式:
- 更高的 replication factor(更多副本)
- 允许 client 从其他 clients 上读取数据
## 2.6 Metadata
- master 存储了三种主要类型的元数据:
1. file 和 chunk namespaces
2. files 到 chunks 之间的映射
3. 每个 chunk replica 的位置
<br>
- 所有的元数据都存储在 master 的内存中。
- 前两种类型的元数据会==持久化==到 master 本地磁盘上(通过记录 **operation log**),并复制到远程。
- chunk location 信息不持久化,而是通过问询 chunkserver 来获取。
### 2.6.1 In-Memory Data structures
- 因为元数据都存储在内存,所有 master 的操作很快。
- 例如可以在后台周期性地扫描**整个** state,用于实现
- chunk gc
- re-replication (chunkserver 故障后)
- chunk 迁移(均衡负载和磁盘空间)
- memory-only 的潜在问题:chunks 的数量即整体容量受限于 master 的内存大小。 在实践中不是问题。
- 每个 chunk 的元数据小于 64 字节。
- file namespace 数据中,每个 file 元数据小于 64 字节(使用了前缀压缩来存储文件名)。
### 2.6.2 Chunk Location
- 即 chunk 的各个副本在哪些 chunkservers 上,这个信息并不持久化。
- master 在启动会从 chunservers 上拉取。
- 之后 master 可以保证这些信息一直是最新的。
- 因为 master 控制了 chunk placement,并通过 Heartbeat 消息监控 chunkservers 上的状态。
- chunkserver 对其自身磁盘上拥有或不拥有哪些 chunks 有==最终决定权==。
- 即是 location 数据的唯一来源。
### 2.6.3 Opertion Log
- operation log 包含了关键元数据变更的历史。它是 GFS 的核心。
- 它不仅是元数据的持久化记录,也代表了并发操作的 **logical time line**。
- file 、chunks 以及它们的 versions 都通过它们创建时的 logical time 来==唯一且永久地==标识。
- operation log 很关键,因此需要可靠地存储它,并且在持久化之前变更对 clients 不可见。
- 将它==复制==到多个 remote machines,在 flush log record 到 local + remote disks之后再回复给 client。
- 通过 batch 来优化 flush 的吞吐。
- master 通过重放 op log 来恢复 file system state。为了最小化启动时间,需要保持 log 数据量尽可能小。
- log 达到一定阈值后进行 ==checkpoint==。启动时先加载 checkpoint 再回放 log。
- checkpoint 是一个 compact B-tree 形式,可以无需解析==直接 mmap== 到内存中(能进一步加速 recovery 时间)
- 创建 checkpoint 对于几百万文件量级需要 1 分钟,在单独线程内执行。创建完后同时写入本地和远程。
## 2.7 Consistency Model
- relaxed consistency model
- 能适配高度分布式的应用程序,同时保持相对的简单和实现高效。
### 2.7.1 Guarentees by GFS
- File namespace mutations 是原子的。
- 例如创建文件操作
- master 独占处理,通过 namespace locking 保证原子性和正确性。
- master 的 op log 为这些操作定义出了 global total order。
- data mutation 之后 file region 的状态取决于 mutation 的类型、操作是否成功,以及是否并发修改。
- **consistent**:所有 clients 始终看到相同的数据,无论从哪个副本上读取。
- **defined**:region 是 consistent 的,且 clients 能看到 mutation 写入的完整内容。
- undefined case:所有 client 看到相同的内容,但是包含了多次写入的混合片段,即无法反映任意一次写入的完整内容;
- 写入失败会导致 region inconsistent(因此也是 undefined),不同的 clients 可能在不同的时间看到不同的数据。
| | Write | Recrod Append |
| ------------------ | ------------------------ | ------------------------------------- |
| Serial success | defined | defined interspered with inconsistent |
| Concurrent success | consistent but undefined | defined interspered with inconsistent |
| Failure | inconsistent | inconsistent |
- [ ] 如何处理 inconsistent ❓
- data mutation 有两种: write 或者 record append
- write 由应用指定 file offset
- record append 原子性地、==at least once== 追加写入。
- offset 由 GFS 挑选,append 相对来说也是一个 write with offset,只不过应用程序认为这个 offset 就是文件的末尾。
- 写入后将 offset 返回给 client,这个 offset 是包含 record 的 define region 的起始位置。
- GFS 可以在中间插入 padding 或者 record deplicates。
- 经过一系列成功的 mutations 之后,被修改的 file region 保证是 defined 并且包含了 *last mutation* 的数据。GFS 通过以下措施实现这一点:
- 以==相同顺序==将 mutations 应用到 chunk 的各个副本
- 使用 chunk version number 来检测 ==stale replica==(chunkserver 宕机,副本缺失 mutations)
- stale replica 不参与 mutation,master 回应 chunk locations 也不会包含,最终会被 GC 掉。
- client 会缓存 chunk locations,因此可能会短暂读到 stable replica。等 cache 失效后可以恢复。
- 大多数场景是 append-only,因此 stale replica 只会返回过早的 chunk eof,而非 outdated data。当 reader 重试并联系 master,就可以获取到正确的 chunk location。
- 组件失败可能会损坏或销毁数据。
- master 和 所有 chunkservers 之间定期握手,通过 checksum 检测数据损坏;发现问题后,尽可能从其他有效副本恢复数据。如果所有的副本都丢失,则 chunk 不可逆地丢失,此时会明确给 clients 返回错误。
### 2.7.2 Implications for Applications
- 应用程序可以一些简单技术来适应 GFS 的 relaxed consistency model:
- 依赖 appends 而非 overwrites
- appending 更高效,对应用程序故障的容忍能力也更强。
- checkpointing
- *❓ GFS 提供的能力?*
- writing self-validating
- self-identifiying records
- GFS append 提供至少一次语义,应用可以通过 record 中的==唯一ID== 来去重。
---
# 3. System Interactions
- 即 client、master、chunkservers 之间如何交互,来实现 data mutations、atomic record append 和 snapshot。
## 3.1 Leases and Mutation Order
- **Mutation**:一个修改一个 chunk 的内容或者元数据的操作, 例如 write 或者 append 。
- 每个 mutation 会在 chunk 的==所有==副本上执行。使用 **leases** 来维护跨多个副本的 consistent mutation order。
- master 将 ==chunk lease== 授予给其中一个副本,成为 ==primary==。primary 为 chunk 的所有 mutations 选择一个 serial order,所有副本应用 mutation 时都遵循这个顺序。
- 因此 global mutation order 首先由 master 选择的 lease 授予顺序定义,并在一个租约内由primary 分配的序列号定义。
- lease 授予顺序 + lease 内的序列号
- lease 机制用来减少 master 的管理开销。
- *相当于部分工作让 primary 负责了?*
- lease 的初始超时是 60 秒。只要 chunk 正在被写入,primary 就可以请求并且无限期地从 master 接收续约(通过 Heartbeat 消息携带)。
- 如果 master 跟 primary 无法通信,在老的 lease 过期后可以安全地授予新的 lease。
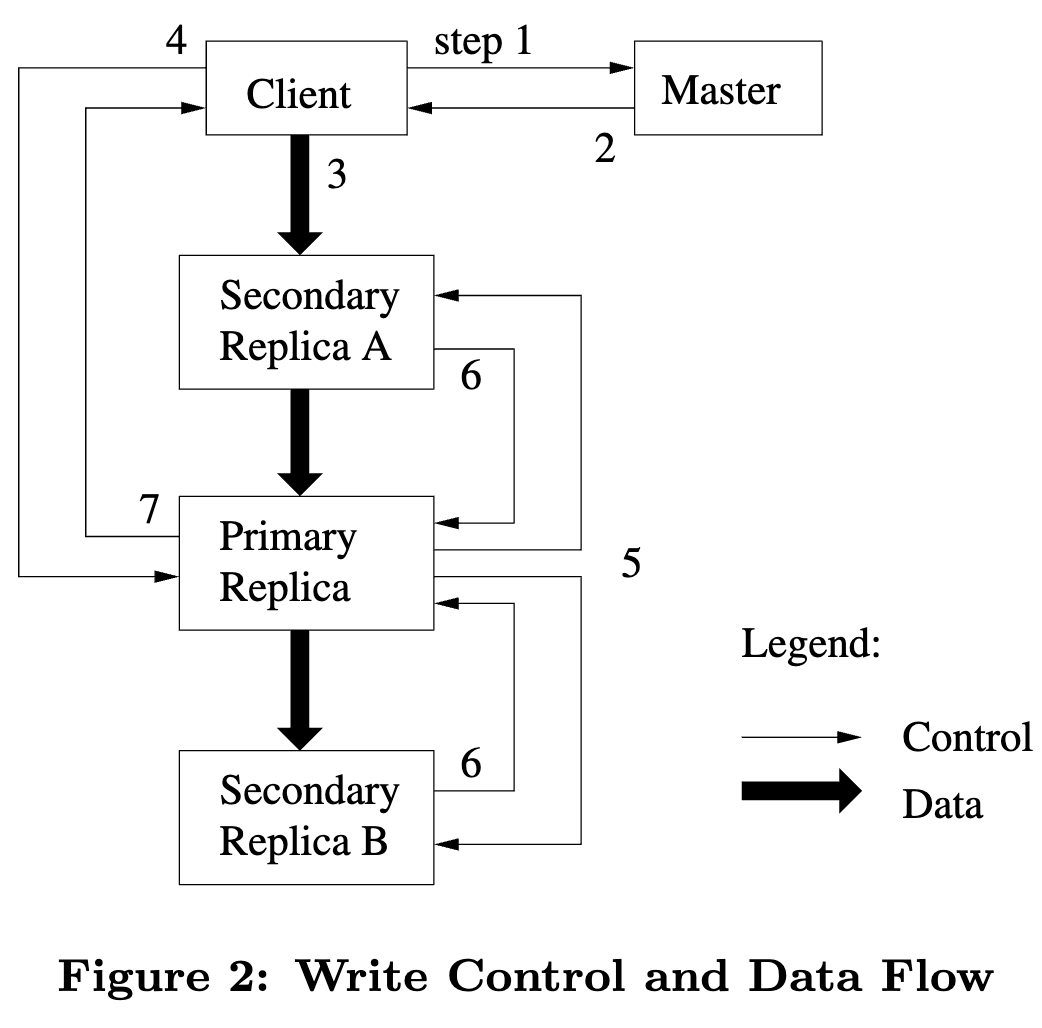
- 写入流程: ^5baf4c
1. client 向 master 询问哪个 chunkserver 持有目标 chunk 的 lease,以及其他副本的位置
- 如果没有 lease,master 会挑选一个副本进行授予
2. master 回复 primary 的标识 以及其他副本(secondary)的位置。
- client 进行缓存。只有当 primary 不可达或者 primary 回复说不再持有 lease 时,才会重新请求 master。
3. client 将数据推送到所有的副本(顺序任意)。
- 每个 chunkserver 将数据存储在内部的 ==LUR buffer cache==。
4. 当所有副本都确认收到了数据,client 向 primary 发送 write request。
- primary 为收到的所有 mutations 分配连续的序列号,并按照顺序应用到 local state。
5. primary 将 write request 转发给所有 secondary replicas。
- 每个 secondary 按照 primary 分配的顺序应用 mutation.
6. 所有 secondary 给 primary 回复操作完成。
7. primary 回复给 client。
- 任意副本上遇到的任意错误都会报告给 client。如果遇到错误,写入可能会在 primary 成功但在部分 secondary 上失败。该 client 请求会被视为失败,被修改的 region 将处于 inconsistent 状态。
- client 通过重试来处理错误。
- 如果一次写入的数据很大或者跨越了 chunk 边界,GFS client code 会拆分为多次写入操作。
- 依次执行上述的流程,但是可能会与其他客户端的并发操作==交错进行==而并被覆盖。
> [!Summary]
> - chunk lease 用于选举出 primary replica,primary 用于协调所有副本的写入,例如确定 mutations 统一的写入顺序;
> - 写入过程有些类似 2PC,先写入到所有副本的 buffer 后,再持久化;
## 3.2 Data Flow
- 解耦了 data flow 和 control flow
- data flow:client 推送数据到副本的 buffer 中
- control flow:发送命令将 buffer 数据持久化
- 精心选择的==链式传输==:而非树状,避免单台机器的带宽(出口)成为瓶颈
- 每台机器选择在网络拓扑上离自己==最近==的机器,转发过去,避开高延迟的链路
- 高延迟链路:跨交换机的链路
- 例如 Client 需要将数据推送到 S1-S4,Client 先将数据发送到离自己最近的 S1,S1 再转发给离自己最近的 S2,以此类推。
- 通过 IP 地址可以估算出网络拓扑的距离
```mermaid
flowchart LR
id1((Client))--> S1 --> S2 --> S3 --> S4
```
- 在 TCP 链接之上进行 ==pipline== 传输数据,最小化延迟
- chunkserver 收到一些数据后就马上转发,不等待收齐
> [!Summary]
> - 链式传输+最近选择
> - pipeline 转发
## 3.3 Atomic Record Appends
- 即 record append 操作,client 只需要指定 data。
- GFS 原子性地==至少一次==将 data 追加到文件上
- record append 也是 mutation 的一种,遵循 [[gfs-paper#^5baf4c|3.1的写入流程]],但需要 primary 增加一点**额外逻辑**
- primary 检查 append 操作是否会超过 chunk 的最大大小(64 MB)
- 如果是的话,让自己和 secondaries 把当前 chunk 填充到最大,并告诉 client 去下一个 chunk 上重试;为防止内碎片,一次 append 大小最多是 chunk 的 1/4 ;
- *填充成为零或者任意数据?*
- 如果当前 chunk 能容纳,primary 将数据追加到自身,并告诉 secondaries 写入到精确的 ==offset== ;
- 确定 append 的写入 offset,保证所有副本写入到相同位置
- 如果在任一副本上 append 失败,client 重试操作。
- 重试可能会导致相同 chunk 的副本包含不同的数据(出现同一个 record 的全部或部分数据重复),GFS ==不保证==所有副本上的数据是字节相同的,只保证数据作为一个原子单元至少写入一次。
- 一次成功的写入只需要保证数据在 chunk 的所有副本上写入到相同的 offset。
- *重试后返回由 primary 确定的、新的、更高的 offset ?*
- 写入成功的 region 是 defined 的,而中间区域是 inconsistent 的
- 
## 3.4 Snapshot
- snapshot 为一个文件或者一个目录树创建一份**拷贝**。
- 几乎是瞬时完成,最小化对 ongoing mutations 的影响。
- 用处:
- 为工作集创建 branch copy
- checkpoint current state,方便作修改、回滚等。
- 类似 [AFS](https://dl.acm.org/doi/10.1145/35037.35059),使用 ==copy-on-write== 技术来实现 snapshots。
- 当 master 收到 snapshot 请求后,先撤销相关 chunks 之上的 leases,让 master 有机会创建 chunk 的 new copy。
- master 会将 snapshot 操作==记入 log==,然后将 log 应用到 memory state,复制一份目标文件或目录元数据, 新创建的 snapshot file 指向跟源文件**相同**的 chunks(COW机制)。
- 后续 client 写入 snapshot 的 chunk C 时,先向 master 查找 lease holder,这时 master 会创建一个新的 chunk handle C',然后请求每个副本内的 chunkserver 执行拷贝,创建新 chunk C'。
- chunkserver ==locally copy==,不经过网络
> [!summary] COW
> 1. 快照文件指向跟源文件相同的 chunk ;
> 2. 后续写入该 chunk 时, master 创建新的 chunk handle,并在 chunkserver 本地拷贝创建新 chunk
----
# 4. Master Operation
## 4.1 Namespace Management and Locking
- 许多 master 的操作耗时较长,因此有必要让多个 master操作同时可运行。
- 对 namespace region **加锁**来解决多个操作的并发问题。
- 与传统文件不同,GFS 没有 per-directory 数据结构可以列举目录下的所有文件, 也不支持 alias(软链接和硬链接)。GFS 维护了 ==full pathname==(绝对路径) 到 metadata 的映射。
- 利用前缀压缩,可以高效存储在内存中。
- namespace tree 的每个 node 即绝对路径都有一个关联的==读写锁==。
- 每个 master 操作执行之前都需要按路径获取==一组== locks。
- 例如当操作涉及 `/d1/d2/../dn/leaf`,会获取 `/d1`,`/d1/d2`,`...`,`/d1/d2/../dn`的读锁,以及 `/d1/d2/../dn/leaf` 的读或写锁。
- 比如创建文件 `/home/user/foo` 时,需要获取 `/home` 和 `/home/user`的读锁,以及 `/home/user/foo` 的写锁,可以并行在同一个目录下创建多个文件。目录的读锁能保证目录不会被删除、重命名和 snapshotted。
- 加锁顺序:不同 level 的按 level 上下顺序,相同 level 的按字典顺序。防止死锁。
> [!summary]
> - 一个绝对路径对应一个读写锁;
> - 创建文件不需要对目录加写锁;
## 4.2 Replica Replacement
- Multi-level distribution:
- 一个集群几百个 chunkservers,分布在不同的机架上, 不同机架上两台机器间通信可能跨越多个交换机。
- 问题:一个 rack 的出入带宽可能小于机架内的所有机器的总的带宽。
- spread replicas ==across racks==:
- chunk replica placement 的两个目标:
1. 最大化数据的可靠性和可用性
2. 最大化网络带宽的利用率
- 如果只是将副本分布到不同的机器上,只能免疫磁盘/机器故障,且只能充分利用每台机器的带宽,这是不够的。
- across racks 可以免疫整个 rack 故障下线,也能同时利用多个 racks 的带宽。
- 劣势:写流量必须流经多个机架,延迟可能变大。
## 4.3 Creation, Re-replication, Rebalancing
- chunk replica 创建的三个原因:
- chunk creation
- re-replication
- rebalancing
- 当 master **创建 chunk** 放置初始的空副本时,会考虑几个因素:
1. 尽可能放置到空间使用率低的 chunkserver 上;
2. 限制每个 chunkserver ==最近创建==的副本数
- 这个指标能可靠地预测即将到来的大量写入流量
3. chunk 的多个副本要跨机架
- 当 chunk 可用的副本数低于用户指定值后,会进行 **re-replicates**
- 可能发生的原因(故障+配置变更):
- chunkserver 宕机
- chunkserver 报告副本损坏,磁盘错误
- replication goal 变大(配置了更多副本)
- 决策哪个 chunk ==优先==进行 re-replicate 的因素
- 离 replication goal 的差距有多大,越大越优先
- 例如丢失两个副本的 chunk 相比丢失一个副本的优先进行
- live files 的 chunks 优先,而非 deleted files 的(还没被 GC 的)
- 最小化应用程序的失败率,优先阻塞了 client progress 的 chunk
- master 挑选最高优先级的 chunk 然后指示 chunkserver 从现存的 replica 上 clone chunk
- 新副本位置的选择策略类似 chunk creation
- 为了避免 clone 流量影响 client 流量,master 限制整个集群和每个 chunkserver 上的clone **并发数量**;此外,每个 chunkserver 通过限制其对 source chunkserver 的读取请求来限制**带宽**。
> [!summary] re-replicate(补副本)
> - 副本故障或者副本数配置变更后触发;
> - 挑选目标 chunk 时,按照几个因素排出优先级;
> - clone chunk 时需要限制对资源的占用
- master 周期性对 replicas 进行 rebalance 操作。
- 检查当前副本的分布,移动副本均衡磁盘使用率和流量。
- 通常优先选择磁盘空闲空间少的作为 source chunkserver。
## 4.4 Garbage Collection
- 文件删除后,不会马上回收物理空间。而是对 file 和 chunks 都进行==延迟删除==。
- 延迟删除:
- 删除文件后,master 会先记录 log,然后重命名为一个 hidden name(包含了删除时间)。后续 master 扫描隐藏文件,对超过三天(可配置)的进行删除。
- 在真正删除之前,仍然可以按照新的特殊名字访问,也可以==撤销删除==(重命名为原来的名字)。
- 真正删除时将 hidden name 从 namespace 中(master 内存元数据)删除,断开 file 与它的 chunks 之间的引用。
- orphaned chunks
- master 将没有被文件引用的chunks 识别为 orphaned。
- 先将 orphaned chunk 的元数据删除,后续 master 通过==心跳消息==跟 chunkserver 交换哪些 chunks 是 orphaned,chunkserver 再对其上的副本进行删除。
> [!summary] GC
> - 延迟删除,可撤销;
> - 先删除文件元数据,删除后 chunks 成为 orphaned,再删除 chunk 的元数据和让 chunkserver 删除 副本。
- 延迟删除的问题:空间无法快速回收;解决方式:
- 用户再次显式删除文件时,加快回收。
- 用户可以指定哪个目录需要立即删除
## 4.5 Stale Replica Detection
- **产生**:
- chunkserver 宕机期间,它上面的 replica 缺失 mutations。
- **检测**:
- 对于每个 chunk,master 维护了 **chunk version number** 来辨别 stable replica。
- 当 master 给 chunk 授予新 lease 时,会增加 chunk version number 并告知 update-to-date replicas。master 和 这些 replicas 都持久化新的 version number。这些都发生在 对 client 可见和写入 chunk ==之前==。
- 如果有 replica 当前不可用,它的 version number 就无法增加,从而被 master 识别为 stale。(chunkserver 会上报它上面的 replicas 和 关联的 version)。
- 如果 master 发现有比自己记录中更新的 version number,则会假设在授予 lease 时失败了,并将较高的 version 视为最新的。
- **解决**:
- 通过 GC 来删除。在此之前,先对 client 屏蔽 stale replicas。
- 当 master 回复 client 哪个是 chunk lease holder 时,以及指示 chunkserver 去其他上 clone 时,都会携带 chunk version number。
- client 和 chunkserver 操作前都会==校验== version number ,保证访问最新的数据。
> [!question]
> lease extension 是否会增长 version number?
---
# 5. Fault Tolerance And Diagnosis
- 最大的挑战是处理经常发生的组件故障。
- 不能完全相信机器和磁盘。
- 组件故障可能会导致不可用,更坏的情况是 corrupted data
## 5.1 High Availability
- **Fast Recovery**
- master 和 chunserver 都可以==秒级==启动。不区分正常还是异常终止。
- **Chunk Replication**
- 每个 chunk 复制到位于不同 racks 的多台 chunkserver 上。
- 用户可以为 file namespace 的某个部分设置不同的 replication levels。
- 正在探索其他形式的跨服务器冗余,例如奇偶校验或纠删码,以满足日益增长的只读存储需求。
- **Master Replication**
- 复制了 master 的 state 来保证高可用。修改必须 flush 到 local disk 和所有 master replicas 上,才认定为 committed。
- 如果 master 无法故障启动 ,由 GFS 外的监控设施启动新的 master 进程。 client 通过 DNS alias 连接 master,master 实例变更后更新 DNS。
- shadow masters:
- 当 primary master 宕机后,可以提供 fs 的只读服务。
- 非 mirror,state 存在轻微 lag;读取副本的 log 进行应用变更;
- 也会像 primary master 一样向 chunkserver 拉去 chunk locations,交换信息。
- It depends on the primary master only for replica location updates resulting from the primary’s decisions to create and delete replicas.
## 5.2 Data Integrity
- 每个 chunkserver 使用 ==checksum== 来检测数据损坏。
- 无法通过比较不同的副本来检测,因为同一chunk 每个副本上的数据可能是不一样的。 每个 chunkserver 独立校验。
- 一个 chunk 拆分为 64 KB blocks,每个 block 对应一个 32 位 checksum。
- checksum 存储在内存和 log 中,与用户数据==分离==。
- *能避免读取时产生额外的 IO?*
- 读的时候,对涉及的所有 blocks 的 checksum 进行校验。
- 如果失败,则返回错误;并上报给 master,触发 re-replicate.
- GFS client 读取时尽可能按照 block ==对齐==,减小额外校验开销。
- 对 append 写入的 checksum 计算进行高度优化
- 增量更新 checksum,不需要校验之前的 checksum
- 而对于覆盖写必须先读取校验后再写入计算checksum,否则会隐藏 corruption;
- chunkserver 在空闲时会扫描和校验 ==inactive== chunks。检测很少被读取的 chunks 中的错误。
## 5.3 Diagnostic Tools
- servers 生成 diagnostic logs,记录重要事件和所有的RPC 请求/回应。
- 事件:如 chunkserver 上下线。
- RPC logs 记录除去 file data 外的完整请求和回应。通过收集 logs 可以跟踪交互历史、诊断问题,也能用于压力测试(回放?)和性能分析。
- logs 顺序+异步写入,减少性能影响。
---
# 7. Experiences
- 需要更多的基础设施来防止用户互相干扰。
- 一些最大的问题来自磁盘和 Linux 相关。
- IDE 协议版本支持问题,可能造成静默损坏数据。
- 开发 checksum 的动机。
--------
# Notes
- 文件切分为大 chunks;chunk 路由信息 master 不持久化,由 chunkserver 负责维护;
- 简化的接口,以及 relaxed consistency。
- 重点优化 append only writes 和 顺序读取,最常见;
- 写入 at least once
- 写入时副本间数据复制: 链式+网络最近+pipeline 传输
- chunk lease + primary/secondary replica
- primary 负责协调写入:确定 mutations 的顺序、append 的写入 offset
- master 内存元数据的 checkpoint 是 B-tree,加载时可以直接映射,提升 recover 速度;
- 副本跨 rack 分布
- 每个 chunk 的副本位于不同 racks 上。
- 无 cache。
## 问题
- [x] 单 master 故障处理
- [ ] chunk 新增流程
- [ ] 应用如果顺序读取 chunk,是否会遇到 inconsistent region,以及怎么处理
- [x] 追加写入一块很大的数据(跨 chunk),中间穿插了另一个客户端的写入
- 一次最大追加 1/4 chunk,chunk不够写入到下一个 chunk,不会跨 chunk
- [ ] re-replicate 操作与 ongoing write 如何协调